Bijna 10 jaar geleden ben ik gestart als zelfstandige op het gebied van kleinschalige automatisering. Met veel plezier heb ik diverse kleine en grote projecten gedaan. Ook het geven van Excel-cursussen heeft veel voldoening en positieve energie opgeleverd. Op mijn website ginfo.nl zijn nu ongeveer 140 artikelen verschenen onder de kop Tips&Trucs. Dit vooral om mijn opgebouwde ervaring en kennis te delen.
Toen ik enkele jaren geleden besloot om mijn werkzame leven te beëindigen en meer tijd te pakken voor andere zaken ben ik wel doorgegaan met het schrijven van artikelen.
Maar na deze 10 jaar moet ik toch constateren dat de inspiratie op begint te raken. Het wordt steeds moeilijker om een nieuw onderdeel van Excel te vinden waarover een artikel geschreven kan worden. Daartegenover staat dat Microsoft (gelukkig) niet stil zit en Excel regelmatig van nieuwe, geweldige uitbreidingen heeft en zal blijven voorzien. Om het gebruik daarvan goed te kunnen belichten moet je dat zelf in de praktijk veel hebben toegepast. Aan deze ervaring ontbreekt het mij en daarom heb ik deze opties ook niet besproken; de enige uitzondering is Power Query.
Dit alles heeft erin geresulteerd dat ik besloten heb om te stoppen met het publiceren van nieuwe artikelen. Mijn website zal ik wel nog een poosje in de lucht houden, zodat iedereen oude (en misschien verouderde) artikelen kan nalezen en de voorbeelden in de downloads kan bestuderen. Dit zolang ik de doorlopende kosten van de website nog aanvaardbaar vind ;-).
NB hebben de artikelen geholpen bij uw werk, bij uw hobby of vond u ze interessant om te lezen en wilt u helpen om de website in de lucht te houden? Iedere bijdrage op NL10ASNB0707879337 t.n.v. G. Verbruggen is welkom (svp onder vermelding van Bijdrage G-Info).
Andere sites
In mijn laatste tip wil ik enkele links opnemen naar andere sites:
Naam
Omschrijving
Link
Chandoo
De Engelstalige website van mijn ‘goeroe’. Zijn doel: At Chandoo.org, my goal is simple. I want you to become awesome in Excel & Power BI.
Een Engelstalige website van Randy Austin. Allerlei toepassingen waarbij VBA een grote rol speelt. Gebruik de button Send me workbooks om iedere week een complete applicatie (!) te ontvangen met Youtube-uitleg.
Vorige week werd duidelijk dat het bedrag aan belastingkorting voor de fossiele industrie in Nederland, vaak ook fossiele subsidies genoemd, veel groter is dan tot nu gedacht/ berekend.
(Foto: Joris van Gennip voor de Volkskrant)
Milieudefensie e.a. hebben op basis van een internationale definitie, opgesteld door de Wereldhandelsorganisatie (WHO), een nieuwe berekening gemaakt. De Nederlandse overheid hanteert dezelfde definitie en methodologie.
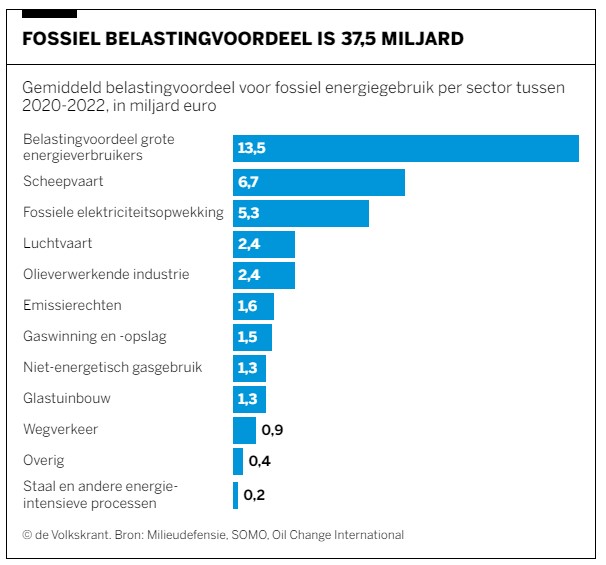
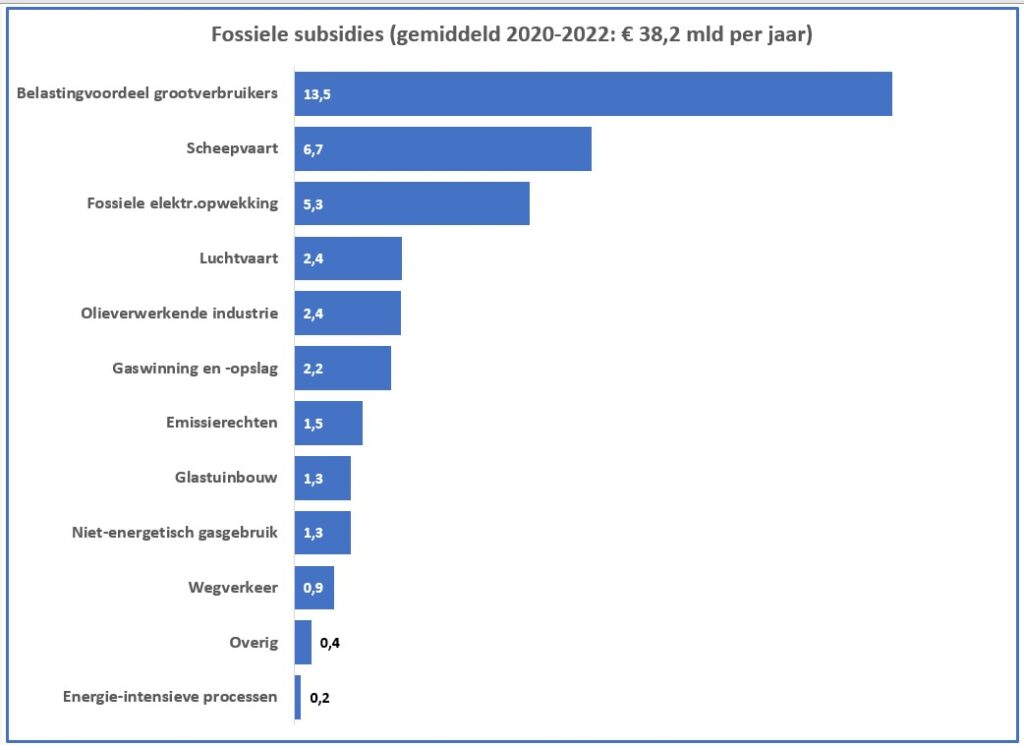
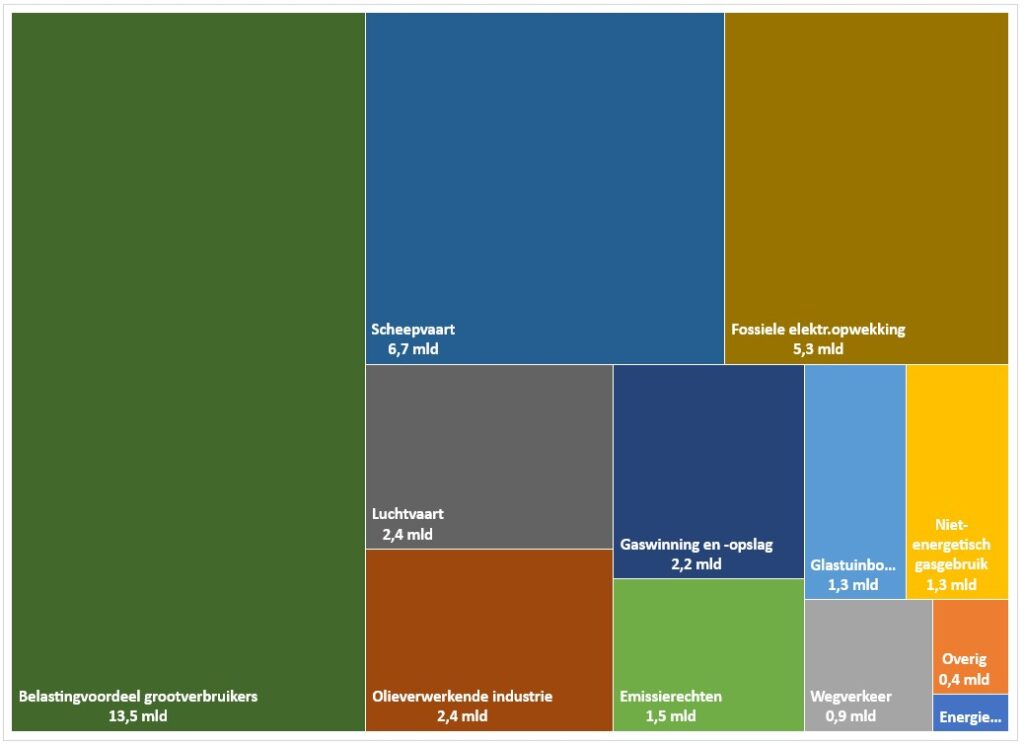
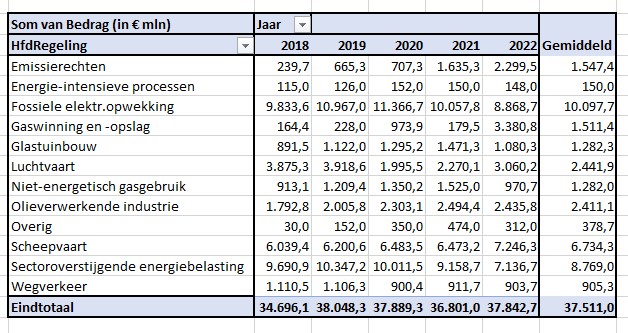
De totale omvang van de subsidies (een gemiddelde over de jaren 2020-2022) wordt in het betreffende rapport geraamd op ruim 37,5 miljard euro per jaar.
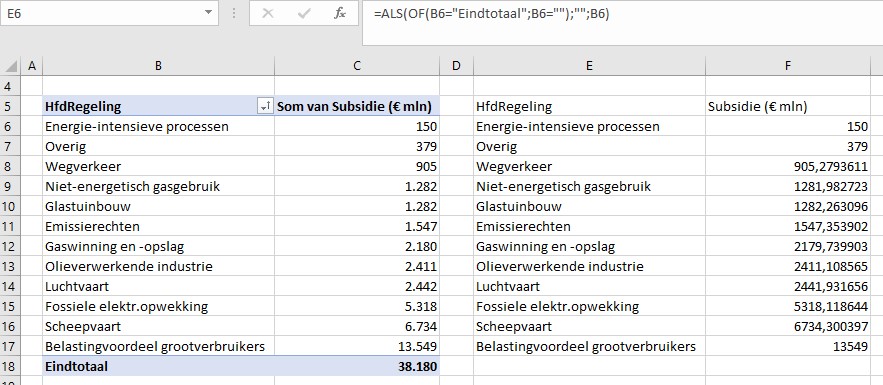
Bij bestudering van de onderliggende cijfers moeten we echter constateren, dat dit bedrag zelfs nog te laag is. Na correctie van een foutieve berekening komen we uit op een totaal van € 38,2 mld.
Hierna zullen we eens kijken naar de gehanteerde methode, de fout in de berekening en hoe je snel enkele soorten grafieken kunt maken die inzicht geven in de verhouding tussen de diverse soorten “subsidies”.
Basis-gegevens
In het tabblad Docu van het Voorbeeldbestand ziet u enkele verwijzingen naar onderliggende documenten. Via de derde link kunt u een spreadsheet downloaden met daarin op detailniveau de gehanteerde berekeningen en bronnen. Transparanter kan niet!
De gemiddelden over 2020-22 uit dit spreadsheet zijn overgenomen in het tabblad Data van het Voorbeeldbestand.
Maken we een overzicht daarvan met behulp van de draaitabel-optie van Excel (zie het tabblad Draai) dan zien we dat dit optelt tot € 38,2 mld en niet 37,5 zoals het rapport aangeeft (en dat door alle media is overgenomen).
We zien dat de post ten voordele van de grootgebruikers het grootste is. In het rapport wordt die hoofdcategorie Regelingen sectoroverstijgende energiebelasting genoemd.
NB wilt u de onderliggende details van een subsidie-bedrag zien? Dubbelklik in de draaitabel op dat bedrag en Excel opent een nieuw tabblad met daarin de betreffende regeling-bedragen.
Afwijking in berekening
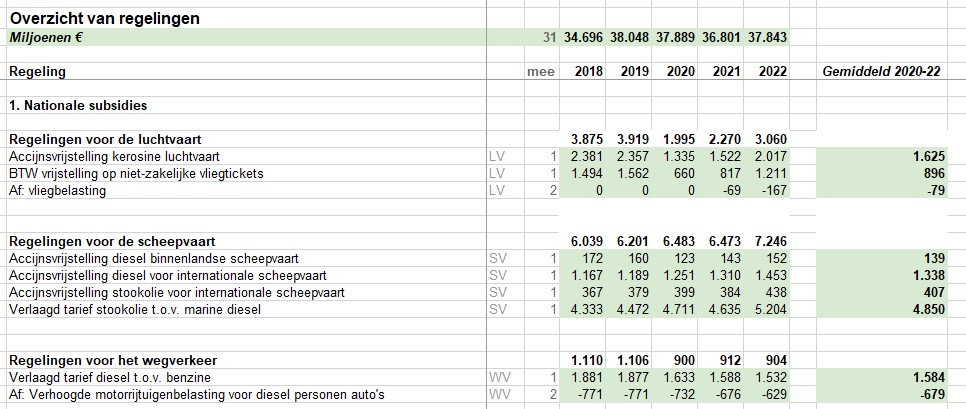
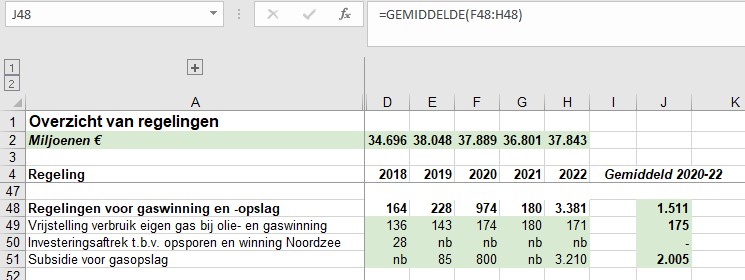
Waar komt het verschil in de totale subsidie-berekening nu vandaan? Hierboven staat een klein gedeelte van de door Milieudefensie e.a. gebruikte cijfers. In cel J48 wordt het gemiddelde over 3 jaar van de categorie gaswinning en -opslag bepaald. Maar dat is niet gelijk aan de som van de onderliggende gemiddeldes! Dat wordt veroorzaakt door de nb in cel G51. Bij het berekenen van het gemiddelde in die regel wordt die cel door Excel (terecht) niet meegenomen; bij het bepalen van het gemiddelde in cel J48 is (impliciet) de nb meegeteld als 0, waardoor dit bedrag lager uitkomt.
LET OP: wanneer je gemiddelden wilt berekenen (of dit nu in Excel is of niet) en er ontbreken basisgegevens, bedenk dan in welke volgorde de berekeningen moeten worden uitgevoerd.
Staafdiagram
Een eerste grafiek, die goed laat zien in welke mate de diverse subsidies bijdragen aan het totaal-bedrag is het zogenaamde staafdiagram (zie het tabblad Graf in het Voorbeeldbestand):
klik ergens in de draaitabel op het tabblad Draai van het Voorbeeldbestand
kies in de menutab Hulpmiddelen voor draaitabellen in het blok Analyseren op Draaigrafiek
kies de optie Staaf
zorg dat in de draaitabel de bedragen gesorteerd staan van laag naar hoog (via rechts-klikken)
selecteer bij Grafiekelementen de optie Gegevenslabels
klik rechts op één van de gegevenslabels en kies Gegevenslabels opmaken
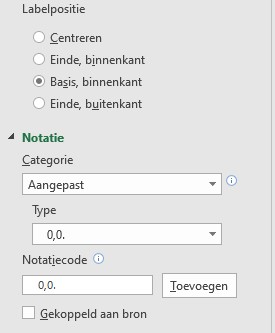
pas de Labelpositie aan en maak een aangepaste Notatie: 0,0. Dus een paar spaties, een nul, een komma, weer een nul en dan een punt. Excel zal de getallen dan van extra spaties aan de voorkant voorzien, zorgen dat er 1 decimaal wordt weergegeven en, door de punt achter de cijfers, dat hij moet afronden op duizendtallen.
de positie van de onderste 2 gegevenslabels zijn gewijzigd door nog een keer extra op deze labels te klikken en de opmaak aan te passen (Einde, buitenkant)
pas ‘naar smaak’ nog wat extra opmaak toe
De grafiek is ook voorzien van een dynamische titel:
klik ergens in de grafiektitel
tik in de formulebalk het volgende in: =Draai!$E$2
op het tabblad Draai staat in cel E2 de formule: =”Fossiele subsidies (gemiddeld 2020-2022: € “&TEKST(DRAAITABEL.OPHALEN(“Subsidie (€ mln)”;$B$5);”0,0.”)&” mld per jaar)”
Staafdiagram 2
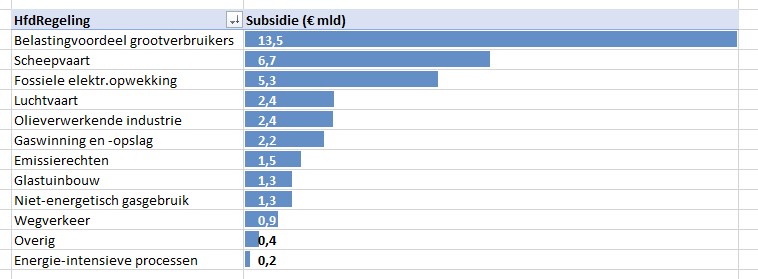
Een vergelijkbare grafiek kun je ook direct in de draaitabel maken (zie het tabblad Draai2 in het Voorbeeldbestand):
klik op één van de cellen in de bedragenkolom van de draaitabel
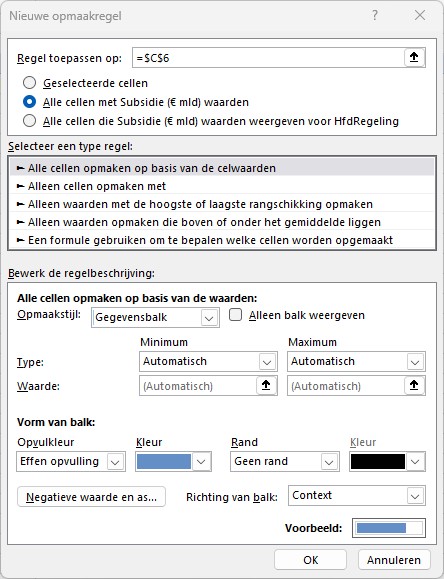
klik in de menutab Start in het blok Stijlen op Voorwaardelijke opmaak en kies de optie Nieuwe regel
vul het tussenscherm in, zoals hiernaast. Het keuzerondje zorgt er voor dat als de draaitabel later uitgebreid wordt, de nieuwe gegevens ook deze opmaak krijgen.
klik rechts op één van de bedragen en kies de optie Getalnotatie. Ook hier zorgen we weer voor een aangepaste notatie: 0,0.
de kop van de bedragenkolom moeten we nog veranderen, want er worden nu geen miljoenen meer weergegeven maar miljarden.
NB wilt u nog wat tips voor het opmaken van draaitabellen kijk dan op het tabblad Docu van het Voorbeeldbestand; daar staat een verwijzing naar een internet-artikel en naar een ‘spiekbriefje’.
Treemap
Het tabblad Tree1 van het Voorbeeldbestand bevat een ander soort grafiek, waarmee de verhouding tussen de onderdelen goed zichtbaar gemaakt kan worden, een zogenaamde Treemap.
Helaas kan die niet als Draaigrafiek rechtstreeks op een draaitabel gebaseerd worden (tenminste niet in mijn Excel-versie 2019). We hebben een tussenstap nodig (zie het tabblad Draai):
Naast de draaitabel maken we dus een verwijzing naar die gegevens. Selecteer de betreffende kolommen en kies in de menutab Invoegen in het blok Grafiek de optie Hiërarchiegrafiek. Daar vindt u de Treemap-optie. De treemap is op een grafiekblad Graf geplaatst, zodat we een grafiek overhouden zonder ‘afleiding’ daar omheen. Excel schikt de diverse categorieën zodanig dat er een mooi gevulde rechthoek ontstaat. Helaas: bij het verder opmaken van de grafiek zult u merken dat het niet mogelijk is om een dynamische titel toe te voegen. En ook de oplossing met een Tekstvak gaat hier niet werken.
Dezelfde treemap staat ook op een gewoon Excel-blad (zie het tabblad Tree2). Nu kun je wel een tekstvak toevoegen en daarin een verwijzing maken naar cel E2 in het tabblad Draai.
Een ander voordeel van het plaatsen op een gewoon Excel-blad is dat je de vorm van de rechthoek kunt aanpassen aan je eigen wensen:
Extra data
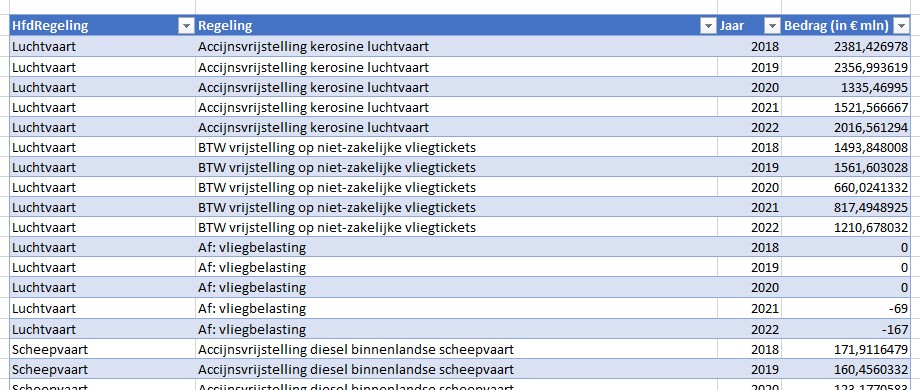
Voor de liefhebbers heb ik met behulp van Power Query uit de bron wat meer details opgehaald (zie het tabblad Data2 in het Voorbeeldbestand):
Op basis van deze data kun je diverse overzichten genereren, bijvoorbeeld een draaitabel op hoofdregeling-niveau over de jaren:
LET OP: het probleem met het middelen zoals hierboven aangegeven, steekt hier ook weer de kop op!
In het vorige artikel hebben we laten zien hoe je ‘makkelijk’ gegevens van de CBS-site kunt overnemen; door kopiëren en door het gebruik van de download-optie.
Op het einde van dat artikel hebben we beloofd dat we deze keer zouden laten zien hoe je op een meer geautomatiseerde manier gegevens van het CBS kunt overnemen in Excel.
Het CBS en Excel kennen allebei het Open-Data-protocol; daar gaan we gebruik van maken. In onderstaand artikel allereerst daarom een korte uitleg van Open Data.
Open Data
Om gegevens tussen systemen te kunnen uitwisselen moeten uiteraard de vorm en inhoud hiervan bekend zijn. Wil je de uitwisseling automatiseren dan moeten er harde afspraken over die vorm en inhoud gemaakt worden.
In dit geval bepaalt het CBS de inhoud (welke gegevens worden beschikbaar gesteld, hoe vaak et cetera), maar kunnen we zelf op hun website min of meer de lay-out en vorm van uitwisselen bepalen (zoals we in het vorige artikel zagen).
Het CBS ondersteunt echter ook het zogenaamde Open Data-protocol (via zogenaamde API‘s). Dit is een set van afspraken waardoor de aanleverende en de ontvangende partij precies weten wat de vorm van de aangeleverde gegevens is. Ook Excel (als ontvanger) ondersteunt dit protocol.
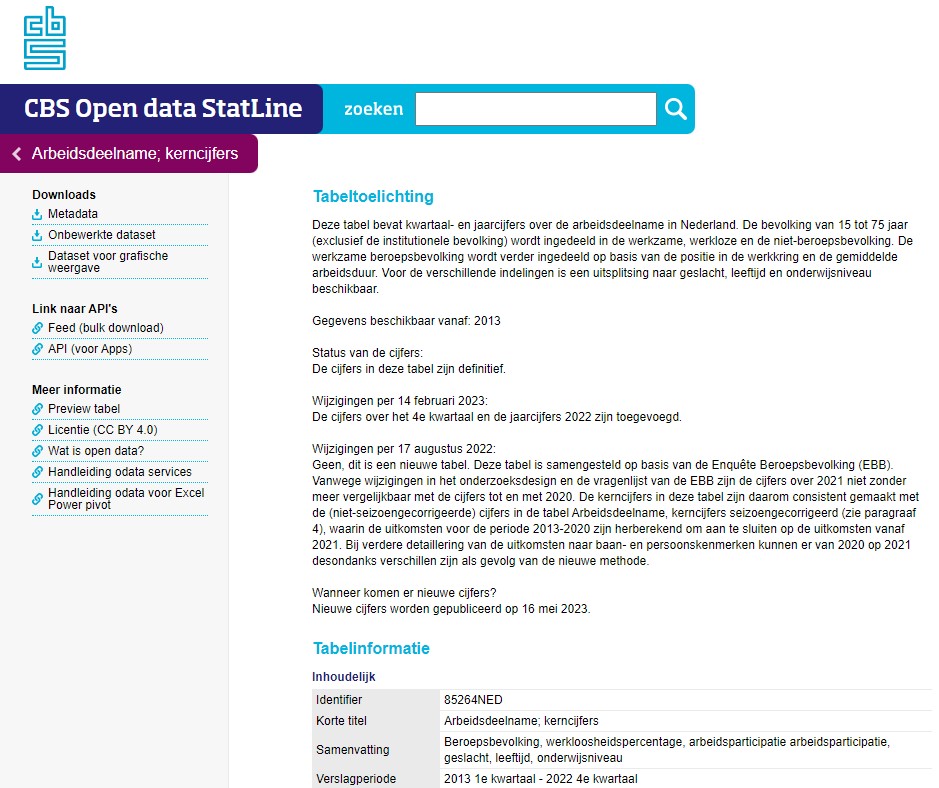
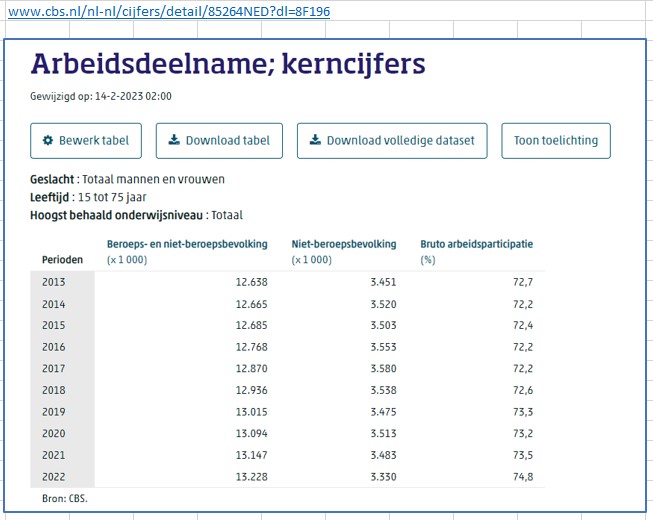
Wanneer je in een CBS-Statline-scherm op de Download-button klikt, zie je dat er ook een mogelijkheid is om naar het Dataportaal te gaan:
Op deze pagina kun je verschillende datasets downloaden en informatie over de (verwerking van) Open Data vinden. Voor het verder automatiseren in Excel hebben we alleen de Identifier nodig (in dit geval 85264NED):
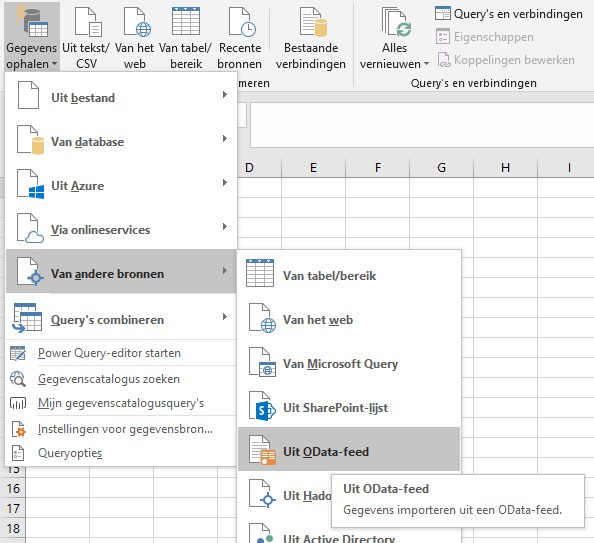
kies in de menutab Gegevens de optie Gegevens ophalen/Van andere bronnen/Uit OData feed
in het vervolgscherm wordt gevraagd naar de URL; dat is in dit geval opendata.cbs.nl/ODataFeed/odata/85264NED Klik OK.
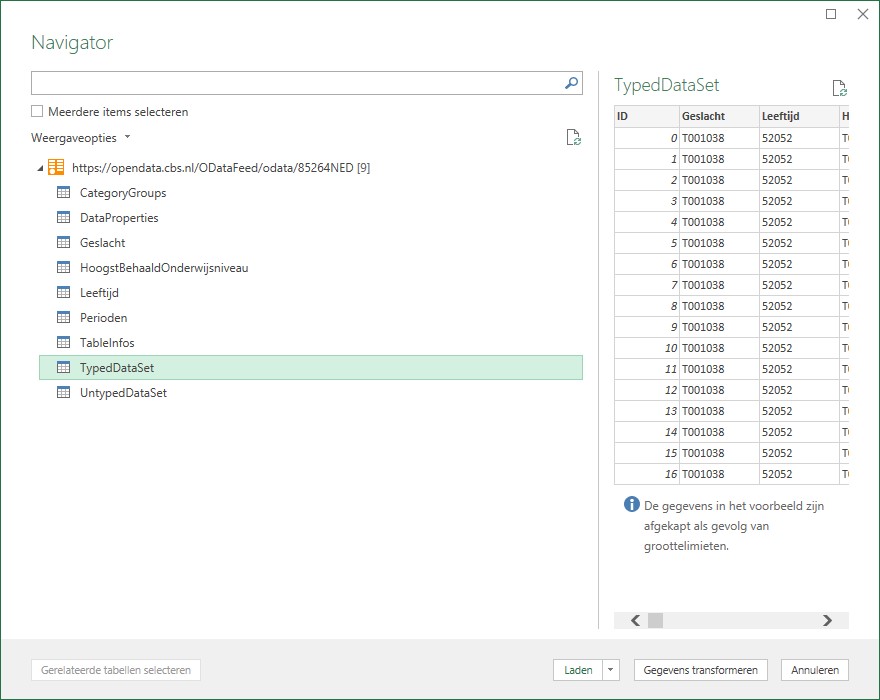
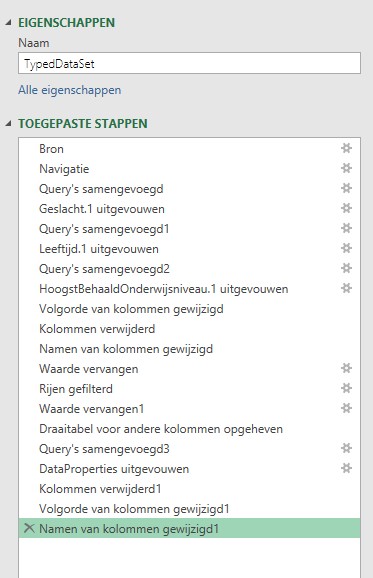
Kies de tabel TypedDataset en kies Gegevens transformeren
de kolom ID hebben we niet nodig; Verwijderen dus
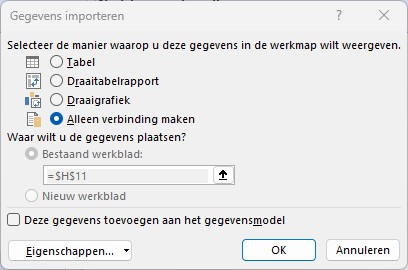
kies in de menutab Start de optie Sluiten en laden
de tabel wordt in een Excel-tabblad geplaatst (zie het tabblad Power in het Voorbeeldbestand)
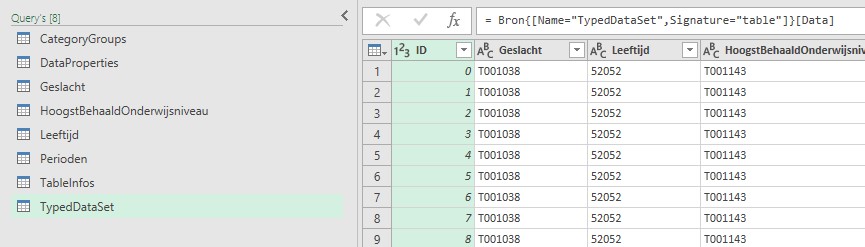
We hebben nu een zogenaamd genormaliseerde tabel van het CBS binnengehaald. Een nadeel is dat de tabel niet een zodanige vorm heeft dat je daar gemakkelijk een draaitabel ‘op los kunt laten’. Daar moeten we nog wat aan doen!
NB1 het ophalen van een Open-Data-tabel vanuit de CBS-website gaat altijd via de URL opendata.cbs.nl/ODataFeed/odata/Identifier, waarbij je zelf de juiste Identifier dient op te geven.
NB2 de query en de Excel-tabel krijgen automatisch de naam TypedDataSet.
Power Query 2
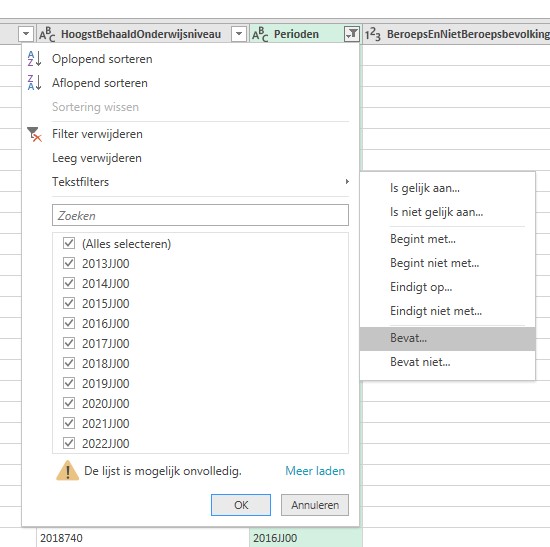
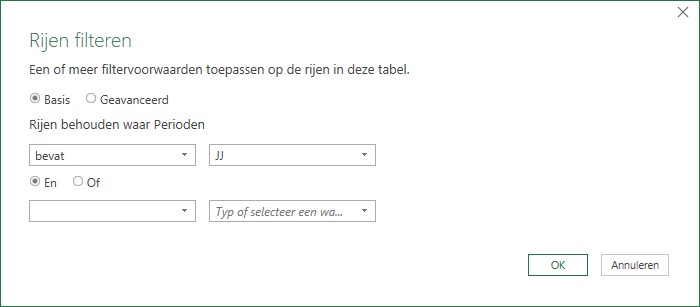
In het tabblad Power2 in het Voorbeeldbestand hebben we op dezelfde manier als hiervoor de tabel TypedDataset opgehaald. Maar omdat we alleen geïnteresseerd zijn in jaar-cijfers zijn de op te halen rijen gefilterd:
kies het vinkje achter Perioden
selecteer binnen de optie Tekstfilters de keuze Bevat …
vul JJ in
en klik OK
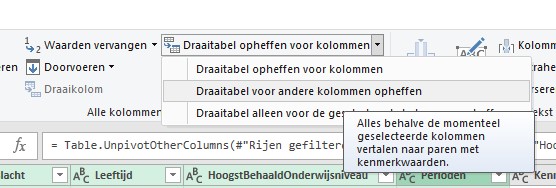
Maar nu willen we nog een database-layout van de tabel maken. De eerste 4 kolommen voldoen daar al aan, maar de anderen niet:
selecteer de eerste 4 kolommen
kies binnen de menutab Transformeren binnen Draaitabel opheffen voor kolommen de optie Draaitabel voor andere kolommen opheffen
kies Sluiten en laden en plaats het resultaat in een Excel-tabel
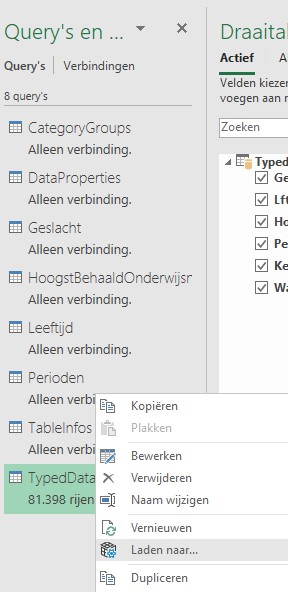
NB de naam van de query en de Exceltabel worden TypedDataSet (2) respectievelijk TypedDataSet_2, omdat de naam TypedDataSet al voorkomt.
Wanneer je nu een draaitabel op basis van de tabel maakt moet je wel goed uitkijken welke selectie je maakt:
De tabel staat nog vol met codes; dat is ook niet wat we willen. Het CBS heeft ieder Open-Data-item netjes uitgenormaliseerd: “Normalisatie is het proces van het ordenen van gegevens in een database. Dat betreft het maken van tabellen en het leggen van relaties tussen die tabellen op basis van regels die als doel hebben de gegevens te beveiligen en de database flexibeler te maken door redundantie en inconsistente afhankelijkheid te voorkomen“.
Willen we dus af van al die codes dan zullen we ook de gerelateerde tabellen moeten binnenhalen.
Power Query 3
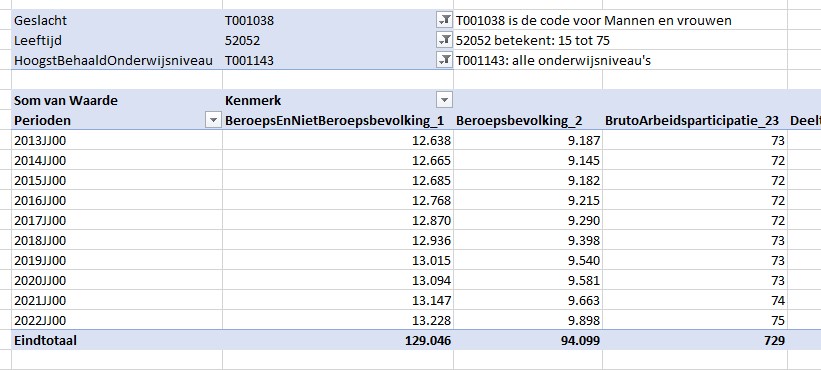
We gaan opnieuw de Arbeidsdeelname, kerncijfers ophalen:
kies in de menutab Gegevens de optie Gegevens ophalen/Van andere bronnen/Uit OData feed
in het vervolgscherm wordt gevraagd naar de URL; dat is in dit geval ook weer opendata.cbs.nl/ODataFeed/odata/85264NED Klik OK.
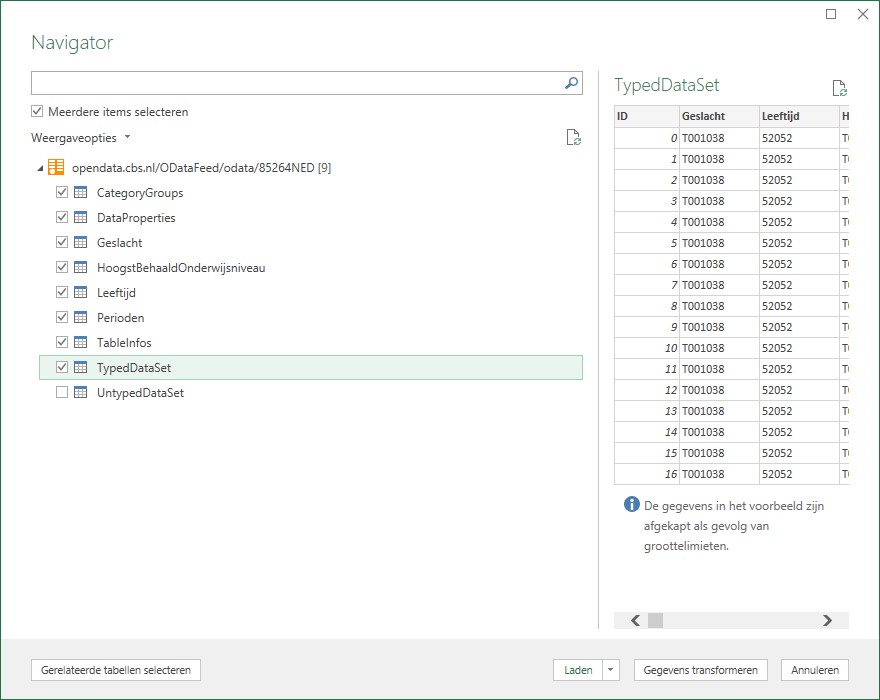
plaats een vinkje bij Meerdere items selecteren
vink alle tabellen aan behalve UntypedDataset en kies Gegevens transformeren
alle aangevinkte tabellen worden tegelijkertijd in Power Query binnengehaald
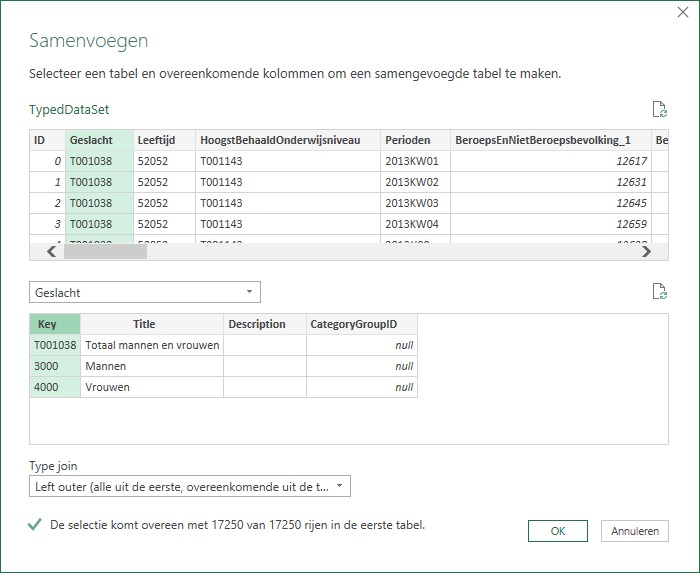
nu gaan we de codes in de kolom Geslacht “vertalen”: * kies binnen de menutab Start de optie Query’s samenvoegen * vul het vervolgscherm als volgt in: * klik OK * klik dan op de 2 pijltjes in de kop van de nieuwe kolom achteraan * zorg dat in het vervolgscherm alleen Title is aangevinkt en klik OK
hetzelfde doen we met Leeftijd en HoogstBehaaldOnderwijsNiveau (zie de stappen in Power Query in het Voorbeeldbestand; voor uitleg over het werken in Power Query, zie het artikel Power Query)
in de volgende stappen wijzigen we de volgorde van de kolommen, verwijderen we overbodige kolommen en voeren nog wat cosmetische acties uit. Daarna zorgen we er weer voor dat we een mooie database-layout krijgen (Draaitabel voor andere kolommen opheffen).
ook de codes in de Kenmerk kolom “vertalen” we.
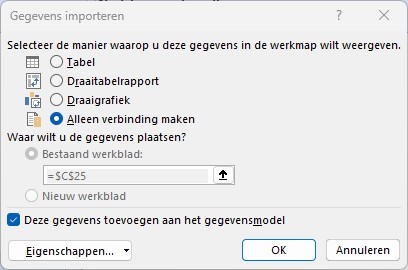
we sluiten Power Query, maar let op: kies Sluiten en laden naar … en zorg dat er alleen een verbinding gemaakt wordt: Op deze manier blijven alle gegevens in het geheugen, maar worden niet nog eens dubbel in Excel zelf vastgelegd.
klik dan rechts op de tabel TypedDataset (3)
kies de optie Laden naar … en vul het scherm als volgt in Door de tabel in het gegevensmodel op te nemen kunnen we toch analyses uitvoeren met behulp van draaitabellen.
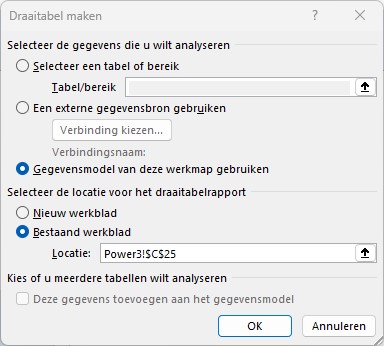
Als voorbeeld maken we een draaitabel:
open een nieuw tabblad
selecteer de cel waar de draaitabel moet komen
kies in de menutab Invoegen de optie Draaitabel
in het volgende scherm staan alle opties goed: Excel kiest als basis voor de draaitabel het Gegevensmodel.
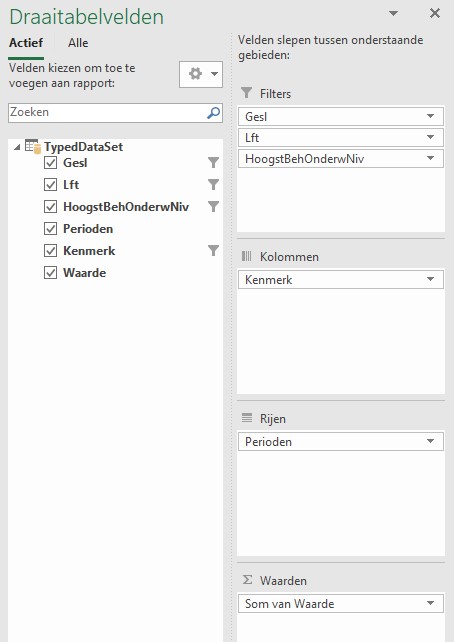
vul het Filters-, Kolommen-, Rijen- en Waarden-gebied in met velden uit de 3e TypedDataSet zoals hiernaast weergegeven. Het resultaat (zie het tabblad Power3 van het Voorbeeldbestand):
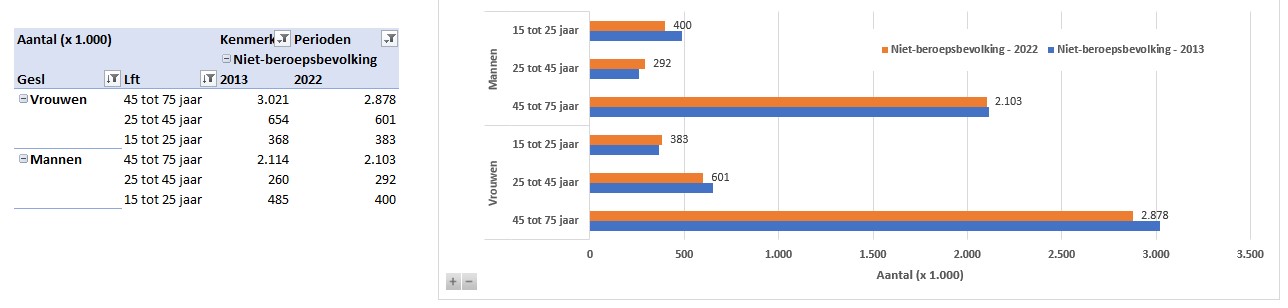
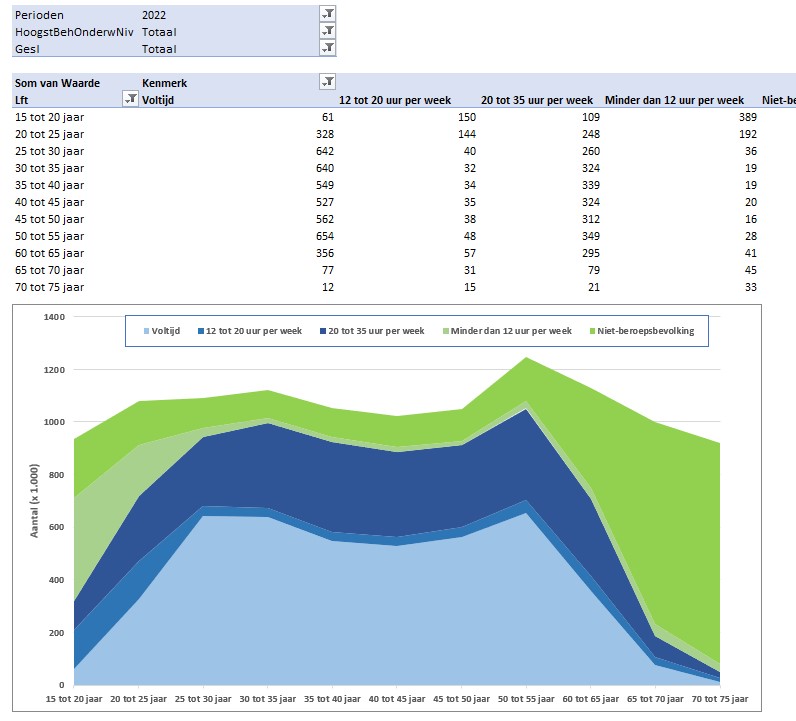
Twee andere voorbeelden, die je nu snel op basis van de CBS-gegevens kunt maken:
en
Zijn de gegevens bij het CBS gewijzigd of aangevuld? Kies in de menutab Gegevens de optie Alles vernieuwen en alle overzichten en grafieken worden automatisch aangepast!
In sommige situaties is het handig om niet alleen het CBS als bron te noemen maar om ook de onderliggende info in je eigen analyse over te nemen en/of te gebruiken.
Er zijn verschillende methoden om die cijfers in Excel te krijgen. Hierna zullen we er enkele bespreken: allereerst het simpelweg kopiëren, daarna het op verschillende manieren downloaden van cijfers.
In een volgend artikel zullen we ook het gebruik van de Open Data-optie bespreken, waarmee het ophalen van cijfers verder gestandaardiseerd en geautomatiseerd kan worden.
Aanleiding
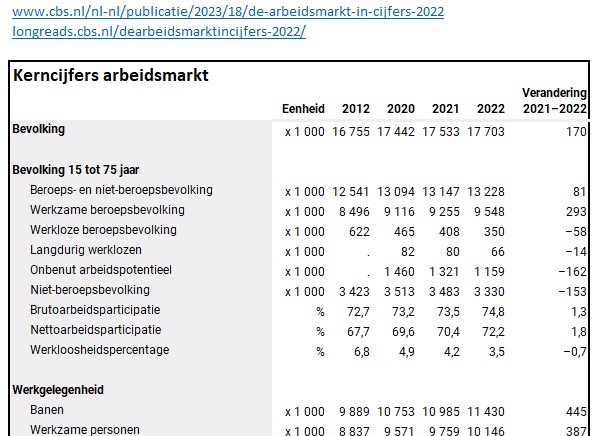
Aanleiding voor dit artikel was een verhaal in de Volkskrant van 3 mei jl. Dat ging over de resultaten van een rapport van het CBS, De arbeidsmarkt in cijfers 2022.
Bij het lezen van het artikel en het rapport kreeg ik de behoefte om op bepaalde onderwerpen wat verder in te zoomen. Daarvoor had ik wel de onderliggende cijfers nodig.
Een samenvatting met de belangrijkste resultaten van het CBS-onderzoek was snel gekopieerd:
selecteer de gewenste gegevens op de website
kies Kopiëren, Ctrl-C
selecteer de cel in Excel waar de linkerbovenhoek moet komen
kies Plakken, Ctrl-V
op de juiste plaatsen een lege regel toevoegen, de kopjes vet maken en de onderliggende items laten inspringen
We gaan nu de gegevens niet kopiëren, maar maken een download. Kies de button
open de download door in de Verkenner in de Download-map op het bestand te dubbelklikken (het bestand heeft in dit geval de naam table__85264NED.csv). In de Chrome-browser komt de naam van de download ook onder in het scherm te staan; de download kun je dan openen door daar te klikken. NB wordt het bestand niet in Excel geopend dan moet je er voor zorgen dat de extensie CSV gekoppeld is aan Excel of de optie Openen met gebruiken
alle gegevens komen in één kolom terecht. Die moeten we dus nog ‘knippen’.
selecteer alle betreffende cellen in de kolom.
kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Tekst naar kolommen.
zorg dat in het vervolgscherm de optie Gescheiden is aangevinkt. Klik op de button Volgende.
zorg dat Komma is aangevinkt en kies Voltooien
Alle gegevens, zoals ze in de tabel op het scherm stonden, worden in een overzichts-vorm aangeleverd.
Wat als we meer en andere gegevens er bij willen hebben?
Download 2
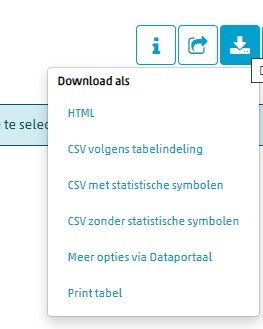
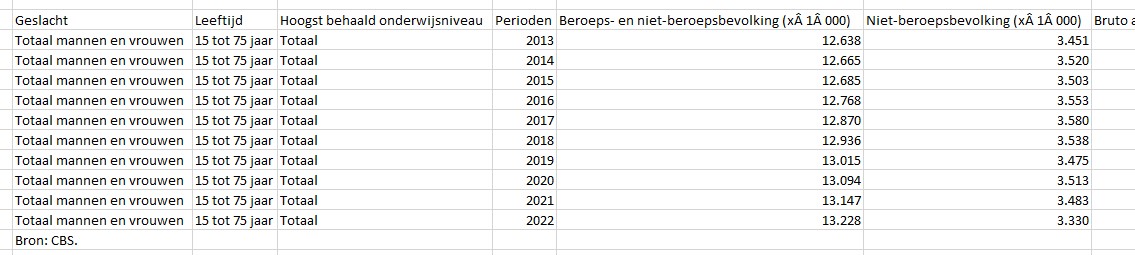
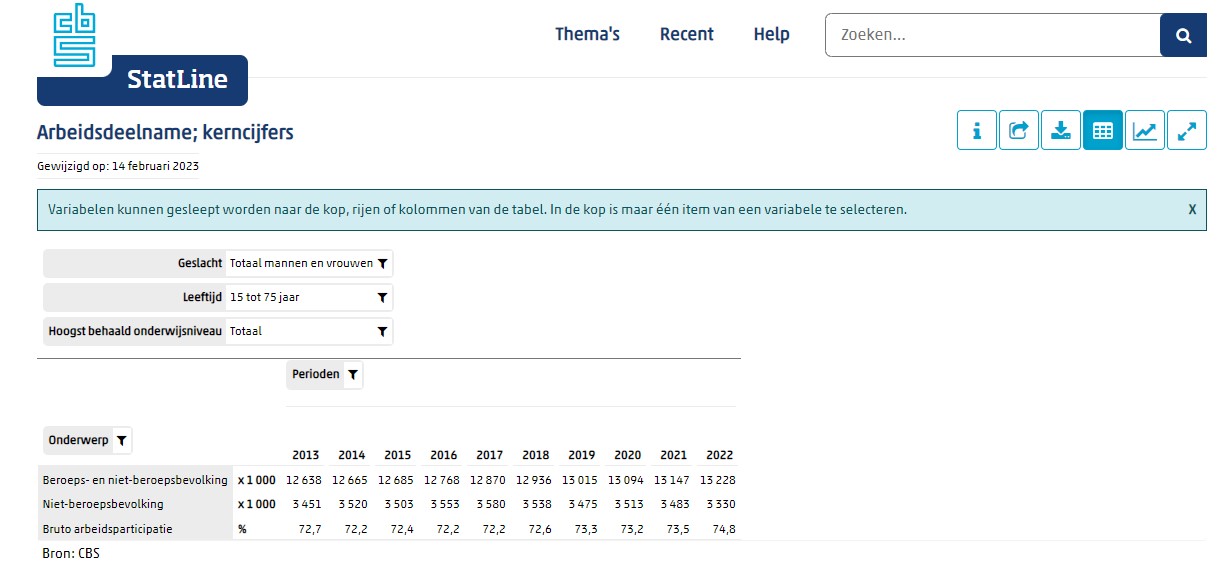
Door op de web-pagina de optie te klikken kom je vanzelf in het Statline-gebied van het CBS, waar je veel meer opties hebt om gegevens te kiezen.
Maar we gaan eerst eens kijken wat er gebeurt als je nu Download kiest: Kies de optie CSV volgens tabindeling.
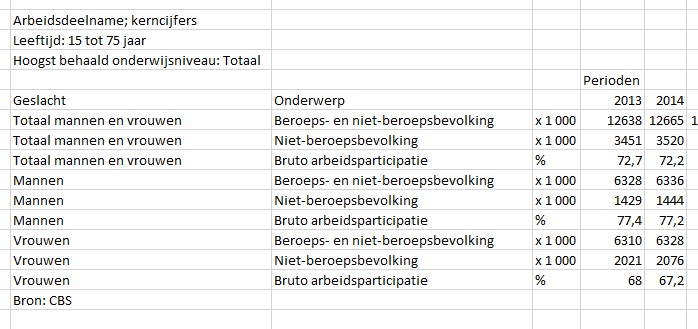
Open de download; het resultaat zal direct in Excel getoond worden (zie het tabblad Download2 in het Voorbeeldbestand):
Je kunt allerlei filteringen aan of uit zetten. Maar je kunt ook onderdelen verplaatsen.
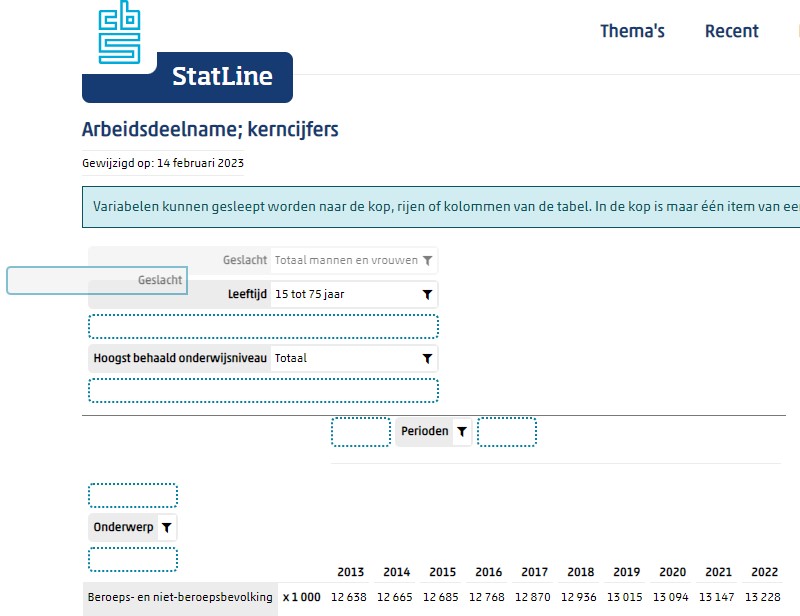
Wanneer je bijvoorbeeld de button Geslacht met de muis ‘vastpakt’ kun je die verplaatsen naar het rijengebied:
Plaats Geslacht boven Onderwerp en zorg bij de filtering dat alle opties zijn aangevinkt
Kies weer de Download-button en open het bestand:
Na wat oefening zul je merken dat je op deze manier redelijk snel gewenste gegevens in Excel kunt overnemen. Een nadeel is dat er veel ‘handwerk’ bij komt kijken en dat de lay-out vaak niet direct geschikt is om verschillende analyses uit te voeren. En als de cijfers door het CBS worden geactualiseerd zullen alle handelingen opnieuw moeten worden gedaan!
In het volgende artikel zullen we dan ook het gebruik van de zogenaamde Open-Data-optie van het CBS en Excel bespreken.
Deze week kwam de vraag binnen of het mogelijk was om met behulp van een formule gegevens uit een tabel, die aan een bepaalde voorwaarde voldoen, te selecteren. De eerste reactie was: hup, dat doen we even. Maar dat viel toch nog tegen.
Want niet iedereen heeft de beschikking over Excel 2021 of Excel 365. Daar ben je met één formule in een cel klaar. Maar niet getreurd: er zijn altijd alternatieven denkbaar.
Nieuwe Filter-functie
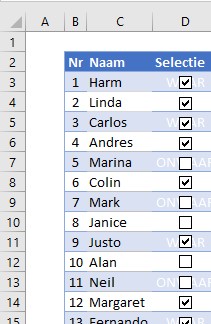
Meer specifiek was de vraag hoe de namen in een bestand met een formule zouden kunnen worden geselecteerd op basis van de selectie in kolom D (zie Voorbeeldbestand).
Vanaf Excel-2021 en -365 bestaan er zogenaamde Spill-functies (ik kwam ergens de Nederlandse benaming Overloop-functies tegen). Het speciale van dit soort functies is dat wanneer je een formule met zo’n functie in een cel plaatst, het resultaat over meerdere cellen terecht kan komen (vandaar spill en overloop). In dit geval plaatsen we ergens de formule =FILTER(Tabel1[Naam];Tabel1[Selectie]=Waar;”Niets gevonden”) en het resultaat is dan alle namen ‘met een vinkje’ in cellen onder elkaar.
‘Oude’ oplossing1
Maar heb je niet de beschikking over deze nieuwe functies dan zul je iets anders moeten bedenken.
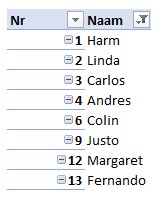
Een oplossing is om op basis van de tabel met namen en selecties een draaitabel te maken. Plaats het veld Naam in het vak Rijen en Selectie in het vak Filters (of maak een slicer zoals in het Voorbeeldbestand). Uiteraard kiezen we bij Selectie dan alleen de optie Waar.
In het voorbeeld is ook een lege naam aangevinkt en deze komt in de rij (leeg) tevoorschijn.
NB Excel sorteert alle namen automatisch op alfabetische volgorde.
Wil je de oorspronkelijke volgorde aanhouden, plaats dan ook Nr in het vak Rijen.
In het voorbeeld hiernaast zijn ook de geselecteerde lege namen in de draaitabel uitgefilterd.
Maar helaas deze oplossing voldeed niet aan de verwachtingen: “Kan het ook met een formule zodat er na het aanvinken van de personen geen extra handeling (het vernieuwen van de draaitabel) meer nodig is?“
Oplossing2
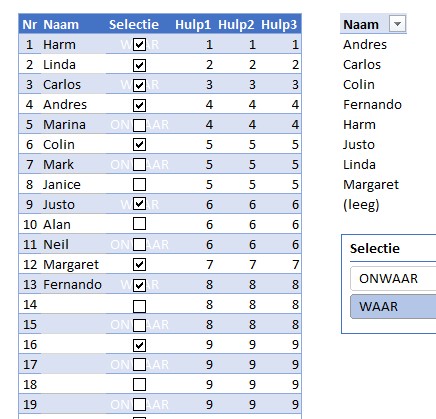
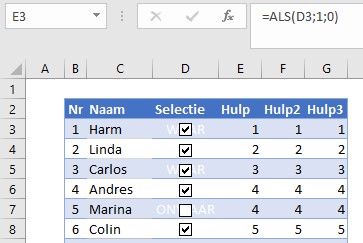
Voor deze oplossing hebben we een hulpkolom nodig (zie kolom E in het Voorbeeldbestand). Daar geven we iedere geselecteerde naam een eigen volgnummer.
In de eerste regel (cel E3) plaatsen we de formule =ALS(D3;1;0) Dus als cel D3 de waarde Waar bevat dan wordt het volgnummer 1 anders 0.
Cel E4 krijgt de formule =E3+D4 We maken hier gebruik van het feit dat Excel de waarde Waar bij een berekening omzet naar 1 (en Onwaar naar 0). Cel E4 kan dan naar beneden gekopieerd worden.
NB we hadden in cel E3 dus ook de formule =D3+0 kunnen plaatsen.
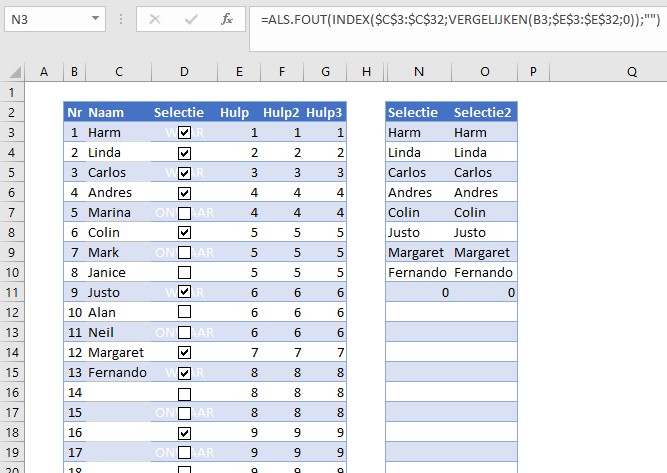
En nu het resultaat. In cel N3 plaatsen we de formule =ALS.FOUT(INDEX($C$3:$C$32;VERGELIJKEN(B3;$E$3:$E$32;0));””)
Als eerste gaan we de waarde van de teller in B3 Vergelijken met de hulp-kolom E. De derde parameter is een 0, dus Excel zoekt een exacte match en dan ook nog de eerste die hij (of zij?) tegenkomt.
Op basis van de gevonden regel in de tabel haalt INDEX de overeenkomende naam op. Als het ergens mis gaat (bijvoorbeeld als het volgnummer niet voorkomt in de hulpkolom) dan is het resultaat “” (niets dus).
In de kolommen F en G staan 2 alternatieven voor de bepaling van de hulpvariabele: cel F3 bevat de formule =AANTAL.ALS($D$3:D3;WAAR). Deze kan naar beneden gekopieerd worden waarbij de eerste D3 blijft staan (deze is absoluut) en de tweede wordt D4, D5 et cetera (een relatieve verwijzing).
Oplossing3
Deze oplossing bouwt door op het vorige artikel op de website van G-Info over de Aggregaat-functie. Bekijk de formule in cel O3 van het Voorbeeldbestand: =ALS.FOUT(INDEX(C$3:C$32;AGGREGAAT(15;6;(RIJ($D$3:$D$32)-RIJ($D$3)+ 1)/($D$3:$D$32 =WAAR);RIJ($A1))); “”)
Gebruik de optie Formule evalueren om de werking te onderzoeken.














 te klikken kom je vanzelf in het Statline-gebied van het CBS, waar je veel meer opties hebt om gegevens te kiezen.
te klikken kom je vanzelf in het Statline-gebied van het CBS, waar je veel meer opties hebt om gegevens te kiezen. 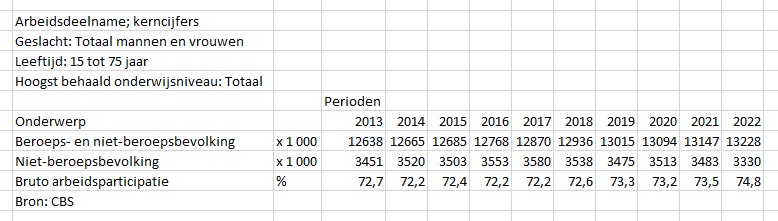
 Voorbeeldbestand: Filter2019.xlsx
Voorbeeldbestand: Filter2019.xlsx