Vorige week werd duidelijk dat het bedrag aan belastingkorting voor de fossiele industrie in Nederland, vaak ook fossiele subsidies genoemd, veel groter is dan tot nu gedacht/ berekend.
(Foto: Joris van Gennip voor de Volkskrant)
Milieudefensie e.a. hebben op basis van een internationale definitie, opgesteld door de Wereldhandelsorganisatie (WHO), een nieuwe berekening gemaakt. De Nederlandse overheid hanteert dezelfde definitie en methodologie.
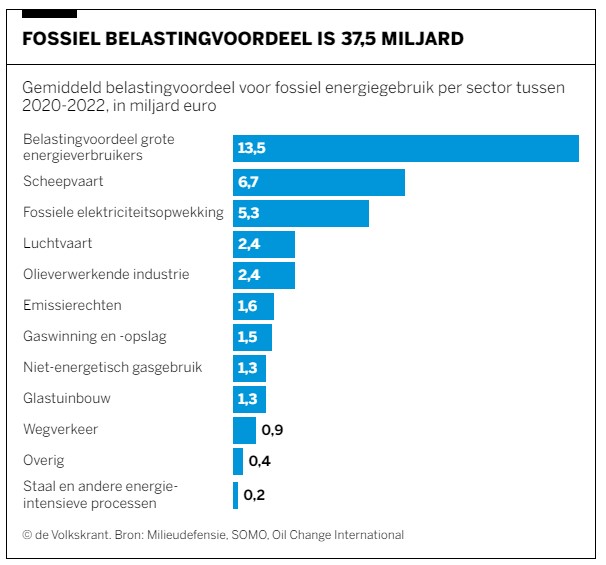
De totale omvang van de subsidies (een gemiddelde over de jaren 2020-2022) wordt in het betreffende rapport geraamd op ruim 37,5 miljard euro per jaar.
Bij bestudering van de onderliggende cijfers moeten we echter constateren, dat dit bedrag zelfs nog te laag is. Na correctie van een foutieve berekening komen we uit op een totaal van € 38,2 mld.
Hierna zullen we eens kijken naar de gehanteerde methode, de fout in de berekening en hoe je snel enkele soorten grafieken kunt maken die inzicht geven in de verhouding tussen de diverse soorten “subsidies”.
Basis-gegevens
In het tabblad Docu van het Voorbeeldbestand ziet u enkele verwijzingen naar onderliggende documenten. Via de derde link kunt u een spreadsheet downloaden met daarin op detailniveau de gehanteerde berekeningen en bronnen. Transparanter kan niet!
De gemiddelden over 2020-22 uit dit spreadsheet zijn overgenomen in het tabblad Data van het Voorbeeldbestand.
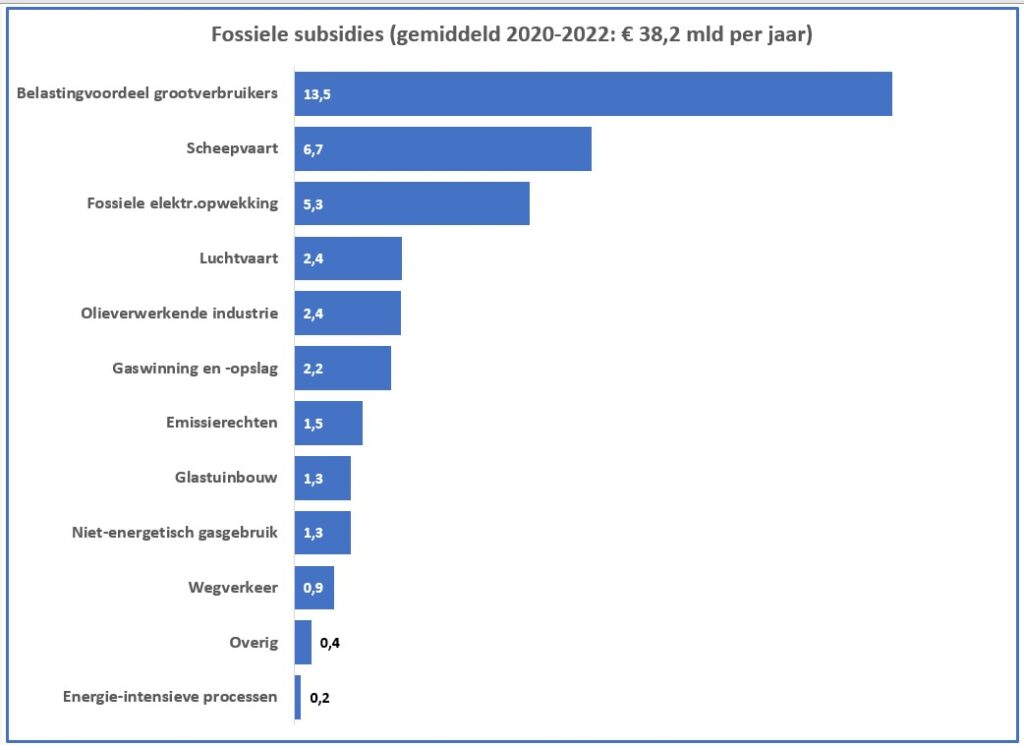
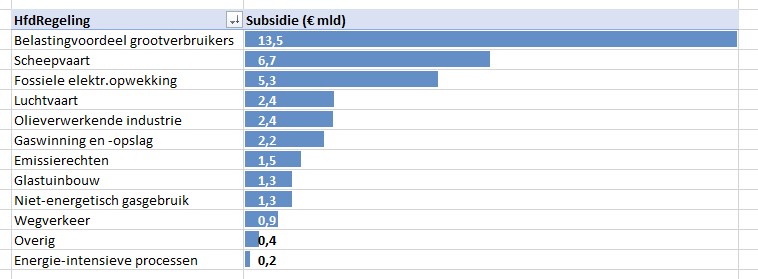
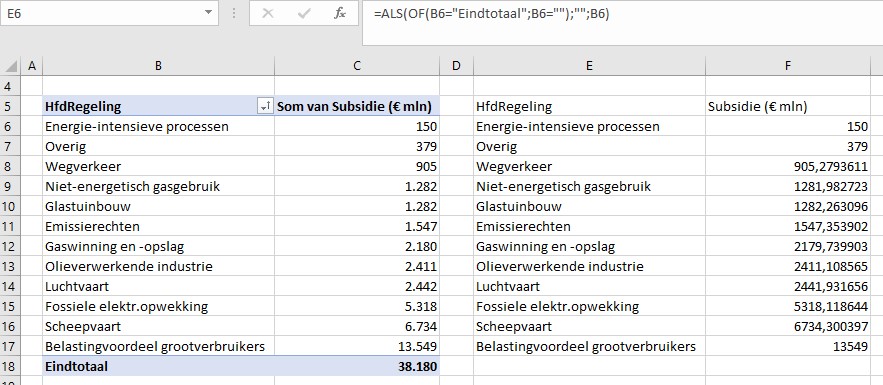
Maken we een overzicht daarvan met behulp van de draaitabel-optie van Excel (zie het tabblad Draai) dan zien we dat dit optelt tot € 38,2 mld en niet 37,5 zoals het rapport aangeeft (en dat door alle media is overgenomen).
We zien dat de post ten voordele van de grootgebruikers het grootste is. In het rapport wordt die hoofdcategorie Regelingen sectoroverstijgende energiebelasting genoemd.
NB wilt u de onderliggende details van een subsidie-bedrag zien? Dubbelklik in de draaitabel op dat bedrag en Excel opent een nieuw tabblad met daarin de betreffende regeling-bedragen.
Afwijking in berekening
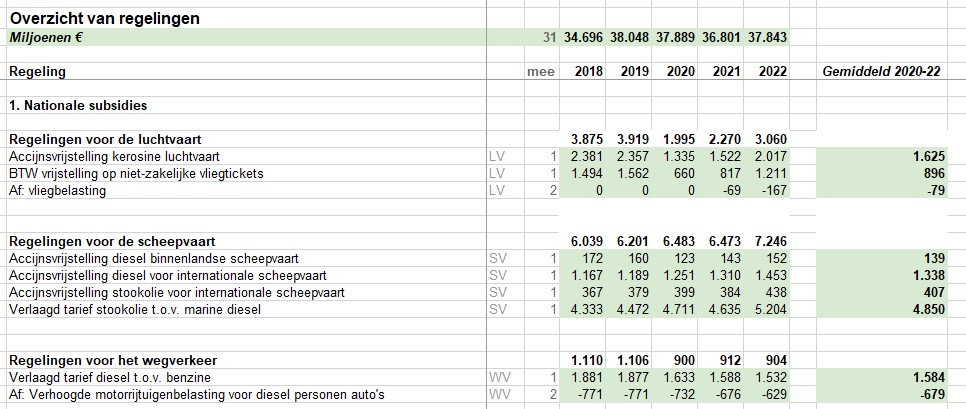
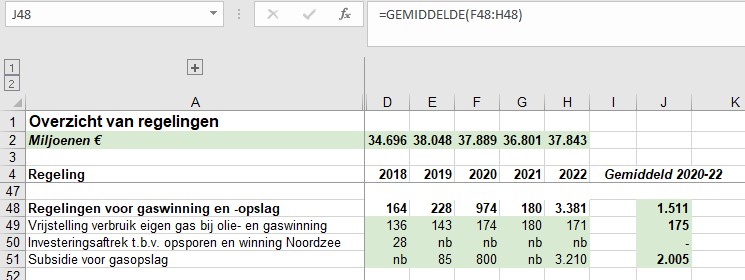
Waar komt het verschil in de totale subsidie-berekening nu vandaan? Hierboven staat een klein gedeelte van de door Milieudefensie e.a. gebruikte cijfers. In cel J48 wordt het gemiddelde over 3 jaar van de categorie gaswinning en -opslag bepaald. Maar dat is niet gelijk aan de som van de onderliggende gemiddeldes! Dat wordt veroorzaakt door de nb in cel G51. Bij het berekenen van het gemiddelde in die regel wordt die cel door Excel (terecht) niet meegenomen; bij het bepalen van het gemiddelde in cel J48 is (impliciet) de nb meegeteld als 0, waardoor dit bedrag lager uitkomt.
LET OP: wanneer je gemiddelden wilt berekenen (of dit nu in Excel is of niet) en er ontbreken basisgegevens, bedenk dan in welke volgorde de berekeningen moeten worden uitgevoerd.
Staafdiagram
Een eerste grafiek, die goed laat zien in welke mate de diverse subsidies bijdragen aan het totaal-bedrag is het zogenaamde staafdiagram (zie het tabblad Graf in het Voorbeeldbestand):
klik ergens in de draaitabel op het tabblad Draai van het Voorbeeldbestand
kies in de menutab Hulpmiddelen voor draaitabellen in het blok Analyseren op Draaigrafiek
kies de optie Staaf
zorg dat in de draaitabel de bedragen gesorteerd staan van laag naar hoog (via rechts-klikken)
selecteer bij Grafiekelementen de optie Gegevenslabels
klik rechts op één van de gegevenslabels en kies Gegevenslabels opmaken
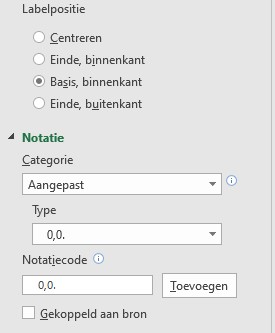
pas de Labelpositie aan en maak een aangepaste Notatie: 0,0. Dus een paar spaties, een nul, een komma, weer een nul en dan een punt. Excel zal de getallen dan van extra spaties aan de voorkant voorzien, zorgen dat er 1 decimaal wordt weergegeven en, door de punt achter de cijfers, dat hij moet afronden op duizendtallen.
de positie van de onderste 2 gegevenslabels zijn gewijzigd door nog een keer extra op deze labels te klikken en de opmaak aan te passen (Einde, buitenkant)
pas ‘naar smaak’ nog wat extra opmaak toe
De grafiek is ook voorzien van een dynamische titel:
klik ergens in de grafiektitel
tik in de formulebalk het volgende in: =Draai!$E$2
op het tabblad Draai staat in cel E2 de formule: =”Fossiele subsidies (gemiddeld 2020-2022: € “&TEKST(DRAAITABEL.OPHALEN(“Subsidie (€ mln)”;$B$5);”0,0.”)&” mld per jaar)”
Staafdiagram 2
Een vergelijkbare grafiek kun je ook direct in de draaitabel maken (zie het tabblad Draai2 in het Voorbeeldbestand):
klik op één van de cellen in de bedragenkolom van de draaitabel
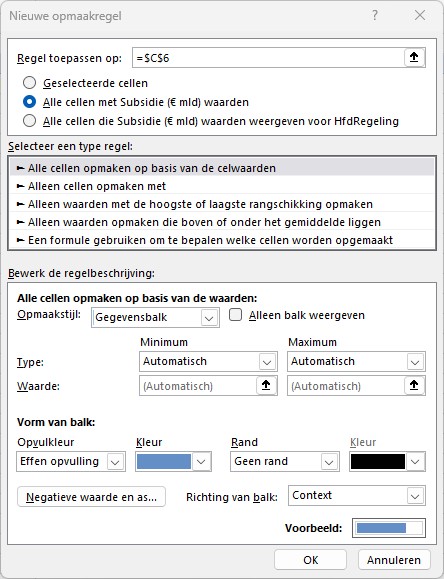
klik in de menutab Start in het blok Stijlen op Voorwaardelijke opmaak en kies de optie Nieuwe regel
vul het tussenscherm in, zoals hiernaast. Het keuzerondje zorgt er voor dat als de draaitabel later uitgebreid wordt, de nieuwe gegevens ook deze opmaak krijgen.
klik rechts op één van de bedragen en kies de optie Getalnotatie. Ook hier zorgen we weer voor een aangepaste notatie: 0,0.
de kop van de bedragenkolom moeten we nog veranderen, want er worden nu geen miljoenen meer weergegeven maar miljarden.
NB wilt u nog wat tips voor het opmaken van draaitabellen kijk dan op het tabblad Docu van het Voorbeeldbestand; daar staat een verwijzing naar een internet-artikel en naar een ‘spiekbriefje’.
Treemap
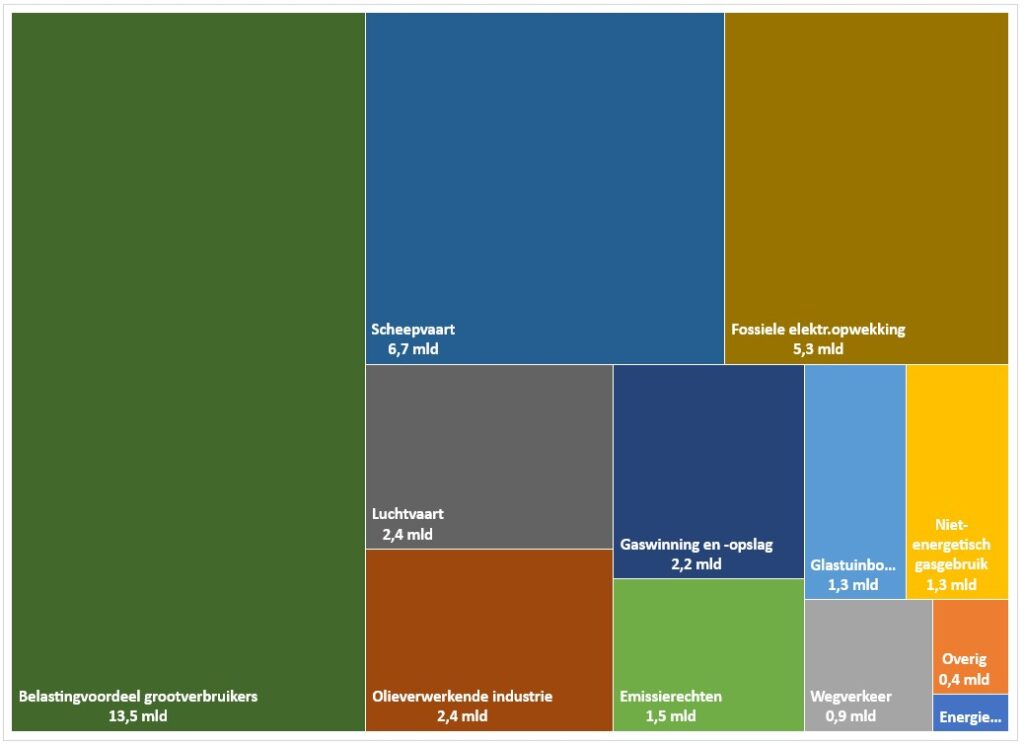
Het tabblad Tree1 van het Voorbeeldbestand bevat een ander soort grafiek, waarmee de verhouding tussen de onderdelen goed zichtbaar gemaakt kan worden, een zogenaamde Treemap.
Helaas kan die niet als Draaigrafiek rechtstreeks op een draaitabel gebaseerd worden (tenminste niet in mijn Excel-versie 2019). We hebben een tussenstap nodig (zie het tabblad Draai):
Naast de draaitabel maken we dus een verwijzing naar die gegevens. Selecteer de betreffende kolommen en kies in de menutab Invoegen in het blok Grafiek de optie Hiërarchiegrafiek. Daar vindt u de Treemap-optie. De treemap is op een grafiekblad Graf geplaatst, zodat we een grafiek overhouden zonder ‘afleiding’ daar omheen. Excel schikt de diverse categorieën zodanig dat er een mooi gevulde rechthoek ontstaat. Helaas: bij het verder opmaken van de grafiek zult u merken dat het niet mogelijk is om een dynamische titel toe te voegen. En ook de oplossing met een Tekstvak gaat hier niet werken.
Dezelfde treemap staat ook op een gewoon Excel-blad (zie het tabblad Tree2). Nu kun je wel een tekstvak toevoegen en daarin een verwijzing maken naar cel E2 in het tabblad Draai.
Een ander voordeel van het plaatsen op een gewoon Excel-blad is dat je de vorm van de rechthoek kunt aanpassen aan je eigen wensen:
Extra data
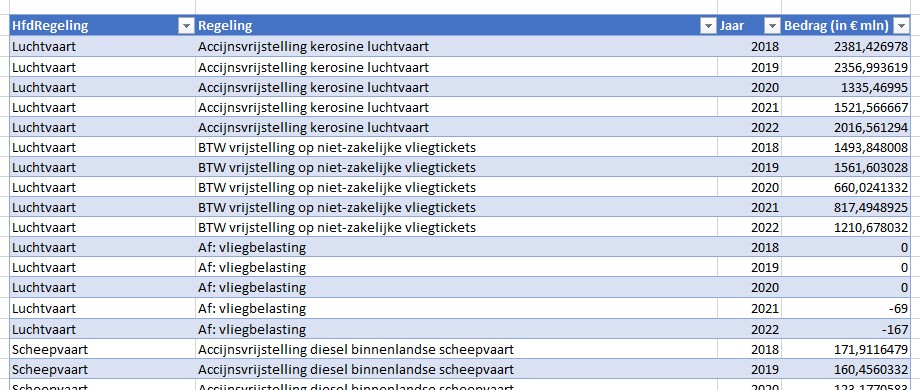
Voor de liefhebbers heb ik met behulp van Power Query uit de bron wat meer details opgehaald (zie het tabblad Data2 in het Voorbeeldbestand):
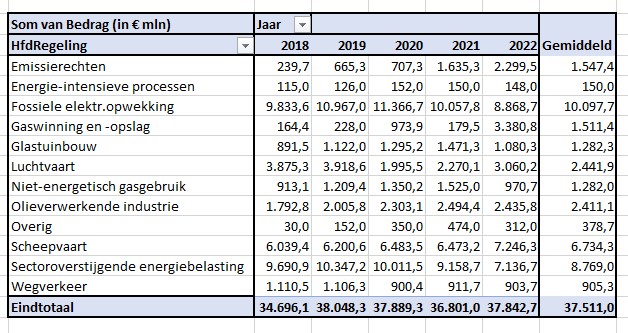
Op basis van deze data kun je diverse overzichten genereren, bijvoorbeeld een draaitabel op hoofdregeling-niveau over de jaren:
LET OP: het probleem met het middelen zoals hierboven aangegeven, steekt hier ook weer de kop op!
In veel artikelen op de website van G-Info worden slicers gebruikt om snel gegevens in een draaitabel te filteren. In het artikel Slicers in Excel hebben we de grondbeginselen laten zien; een soort Slicers voor Dummies dus.
Het werd tijd voor een vervolg, een artikel voor gevorderden.
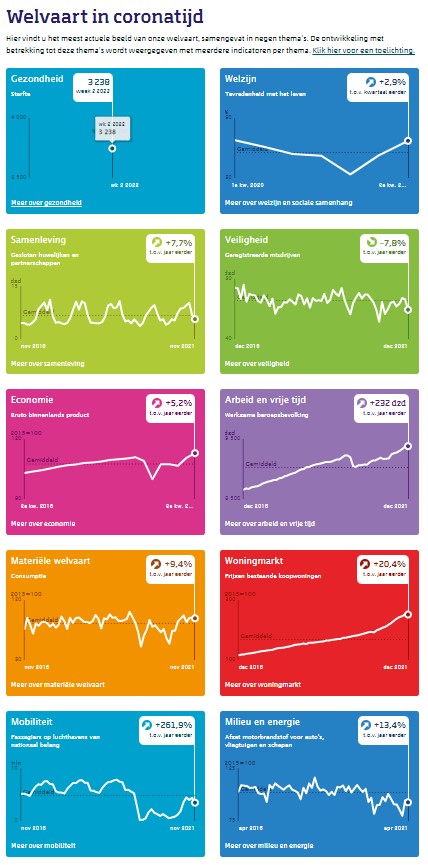
Om wat materiaal te hebben om het gebruik van slicers toe te lichten, ging ik (uiteraard) weer eens rondkijken op de site van het CBS. Daar trof ik een interessante pagina aan, waar geprobeerd wordt de ontwikkeling van de welvaart in Coronatijd zichtbaar te maken. Dit aan de hand van 10 verschillende invalshoeken, zoals Gezondheid (sic!), Economie en Mobiliteit.
Je kunt daar niet alleen grafieken vinden, maar ook doorklikken naar onderliggende data. Dat is voor ons natuurlijk altijd fijn. Kunnen we kijken of we de grafieken na kunnen bouwen of misschien wel verbeteren.
In dit artikel laten we zien hoe de basis-gegevens er uitzien, hoe je daar snel en makkelijk grafieken van maakt en hoe Slicers een rol kunnen spelen bij de presentatie.
Daarnaast zullen we aan de hand van wat fictieve gegevens kijken hoe je de vormgeving van de slicers helemaal naar je hand kunt zetten.
Bron-gegevens
Zoals gezegd hebben we bron-gegevens ontleend aan een pagina op de CBS-website: cbs.nl/nl-nl/visualisaties/welvaart-in-coronatijd. Alle 10 de grafieken hebben een eigen bronbestand; wat opvalt is dat de structuur van de bestanden flink verschillen. Het ene bestand bevat gegevens over diverse jaren, een ander slechts de data van 1 jaar; de detaillering is soms een kwartaal, in een ander geval worden de gegevens getoond op weekbasis etc.
In de eerste 10 werkbladen van het voorbeeldbestand zijn de gegevens overgenomen (soms is de structuur daarvan iets aangepast om het creëren van een grafiek makkelijker te maken).
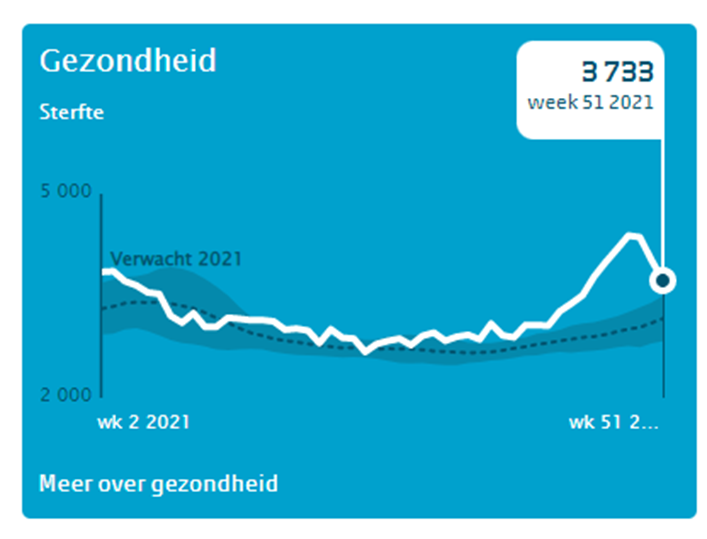
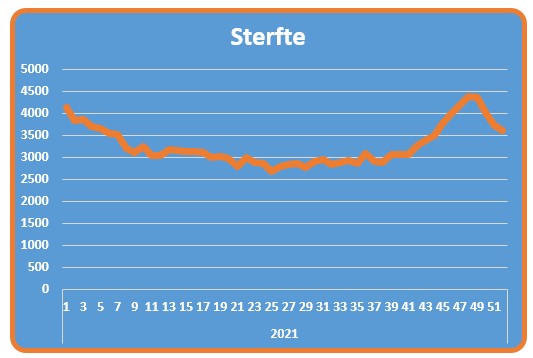
Gezondheid
Op het tabblad Sterfte van het voorbeeldbestand ziet u de grafiek van het CBS en de daarbij behorende gegevens. Als gezondheids-indicator hebben ze ervoor gekozen om de eventuele oversterfte te laten zien.
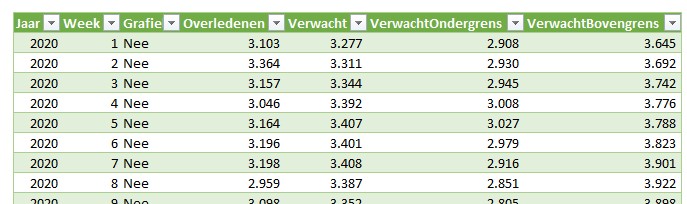
In de grafiek zijn de weken van 2021 weergegeven, terwijl de bron veel meer gegevens bevat. We hebben daarom aan de tabel tblOverlijden een kolom Grafiek toegevoegd, waarmee we kunnen aangeven of een bepaalde week in de grafiek zichtbaar moet zijn of niet:
Op basis van deze gegevens is een draaitabel gemaakt waarin per Jaar en Week de overlijdens etc. worden geturfd. In het Filter-blok staat het veld Grafiek:
Binnen de menutab Hulpmiddelen voor draaitabellen, in de tab Analyse staat de optie Draaigrafiek in het blok Extra.
Een paar aanpassingen:
rasterlijnen verwijderen
de titel en legenda verwijderen
alle Veldknoppen verwijderen
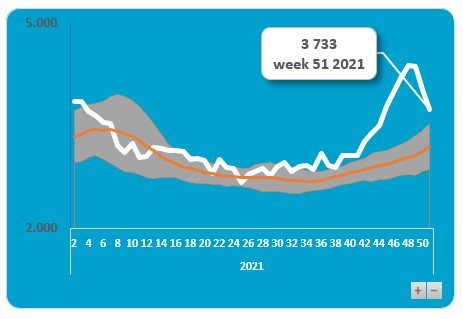
wijzig het grafiektype in Combinatie, waarbij de overlijdens en de verwachting een lijn worden en de andere 2 een vlak
wijzig de achtergrondkleur en de kleuren van de items in de grafiek (het vlak van de Ondergrens krijgt dezelfde kleur als de achtergrond)
pas de opmaak van de assen aan
NB1 je kunt aan punten van een grafiek ook labels koppelen. In dit geval hebben we alleen aan het laatste punt van de grafiek een label gehangen: klik op een lijn in de grafiek, dan nogmaals op het punt waar een label moet komen en klik dan met de rechtermuisknop op dat punt en kies de optie Gegevenslabel toevoegen (om eerlijk te zijn: het label is gekoppeld aan het punt van week 51 van 2021. Wanneer de bovengrens in het tabblad wordt gewijzigd, zal het label wel de juiste inhoud bevatten, maar niet naar het juiste punt wijzen! Uiteraard is dat aan te passen, maar dat gaat ver buiten de scope van dit artikel).
NB2 de inhoud van het zichtbare label wordt via een formule in het tabblad bepaald
NB3 de achtergrondkleur van de grafiek match exact met het origineel. Ik heb de Google Chrome-extensie Eye Dropper gebruikt om de juiste RGB-codes te achterhalen.
NB4 de grafiek is (nog) niet helemaal gelijk aan die van het CBS. Wat meer toelichting van de grafiek en de cijfers zou op zijn plaats zijn, maar ook dat valt buiten de scope van dit artikel.
LET OP wijzig je de grenzen voor de items die in de grafiek moeten worden weergegeven, vergeet dan niet de draaitabel te Vernieuwen (of rechts te klikken op het Grafiekgebied en de optie Gegevens vernieuwen te kiezen).
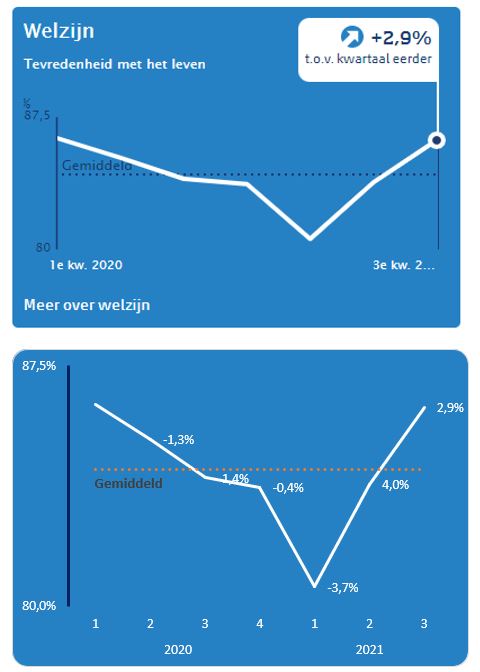
Welzijn
Op het tabblad Welzijn van het voorbeeldbestand staan de betreffende grafiek van het CBS, de brongegevens, een daarop gebaseerde draaitabel en een daarmee gekoppelde draaigrafiek.
In de bron zijn alleen kwartaalgegevens vastgelegd; de getallen op de horizontale as lijken me dat duidelijk genoeg aan te geven.
Het gemiddelde is aan de brongegevens als een aparte kolom toegevoegd. Hetzelfde geldt voor de percentages die de wijziging t.o.v. de vorige maand weergeven.
NB de tekst Gemiddeld is in dit geval als een label aan het eerste punt van de horizontale stippellijn toegevoegd. Door de Notatie van het label aan te passen wordt niet de waarde weergegeven maar in dit geval een letterlijke tekst.
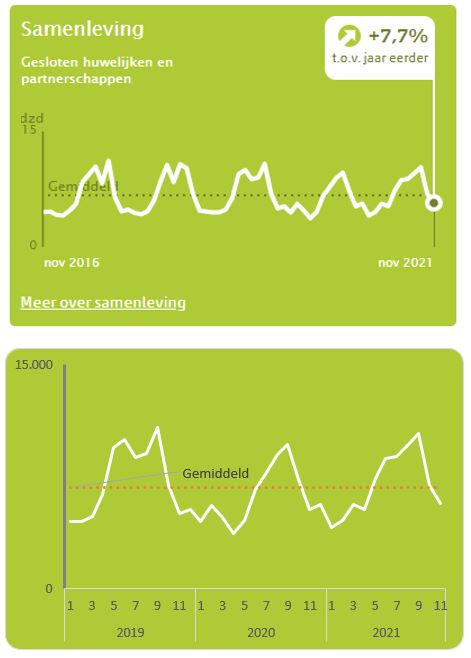
Samenleving
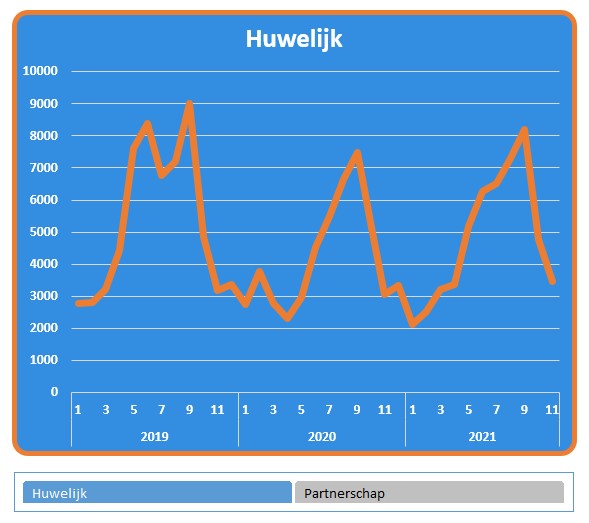
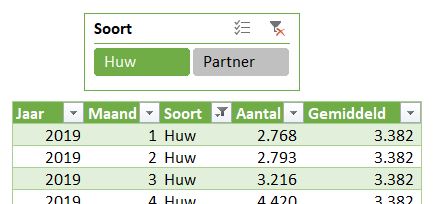
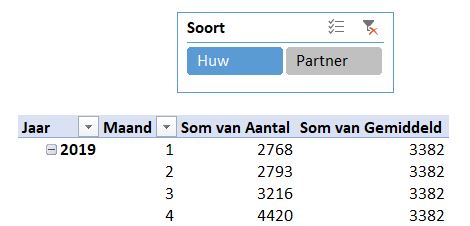
In het tabblad Huw van het voorbeeldbestand ziet u de grafiek van het CBS over Samenleving. Ze hebben daar het verloop van het aantal huwelijken en partnerschappen van de laatste jaren weergegeven.
De brongegevens bevatten daar slecht de gegevens vanaf 2019, dus onze grafiek is wat ‘kleiner’.
De gehanteerde methode is weer hetzelfde: maak een draaitabel op basis van de brongegevens, kies bij Analyse een daarop gebaseerde Draaigrafiek en maak nog wat lay-out-aanpassingen.
De tekst Gemiddeld is weer als een label aan de horizontale lijn gekoppeld. Bij het verplaatsen van dit label naar een plaats waar deze de grafiek niet overlapt, krijgen we ‘gratis’ een koppel-lijntje.
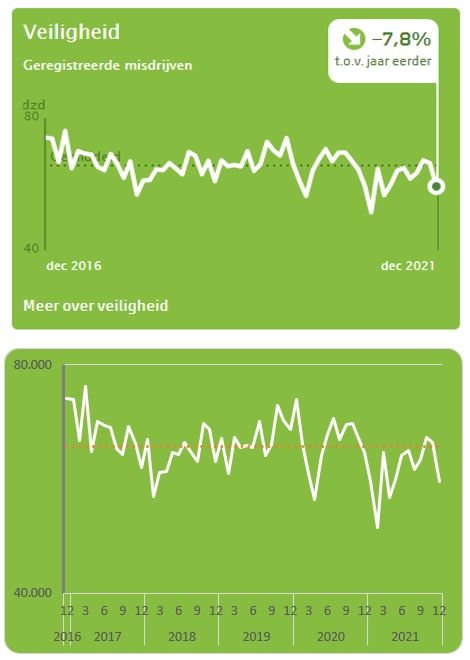
Veiligheid etc.
Ook voor Veiligheid en de andere items vindt u in diverse tabbladen de brongegevens zoals het CBS die beschikbaar stelt.
In het tabblad Veiligheid ziet u onder de CBS-grafiek ook weer een vergelijkbare Excel-grafiek. De manier waarop die is gemaakt bevat geen verrassingen. Misschien de inhoud wel: het aantal misdrijven is dalende, en dat niet alleen in de Corona-periode.
Aan u om voor de overige onderdelen een grafiek te maken. Juist ja: het valt buiten de scope!
Combinatie van data en slicers
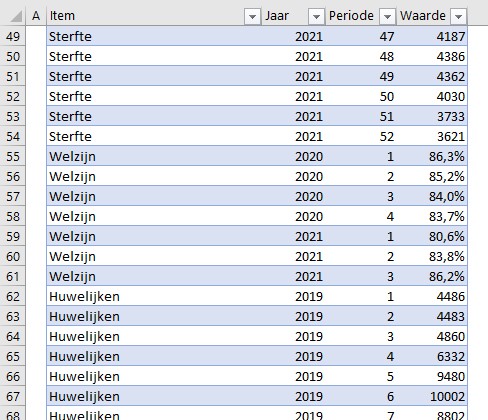
In het tabblad DataTotaal van het voorbeeldbestand zijn de belangrijkste gegevens uit de 10 tabbladen in één tabel opgenomen.
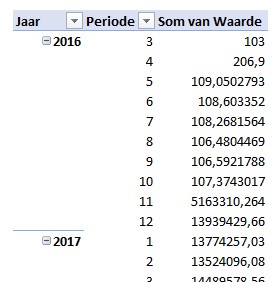
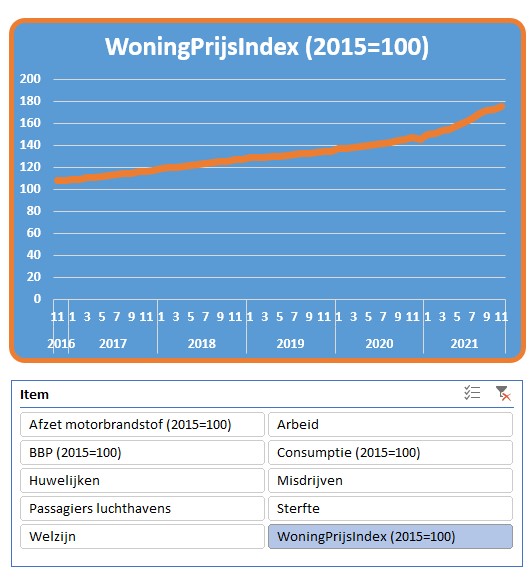
Het soort gegeven staat in de kolom Item, het Jaar is logisch, in de kolom Periode kunnen zowel kwartaal-, maand- als weekaanduidingen voorkomen. In de kolom Waarde staan de bijbehorende percentages, aantallen, indexen etc.
Maken we op basis van deze gegevens een draaitabel dan wordt het een zootje: is die 3 bij periode nu een week, maand of kwartaal, wat stelt die 103 voor?
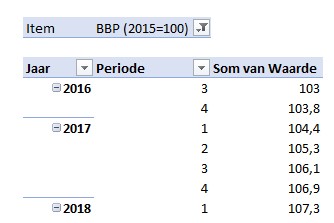
Plaatsen we Item nu in het Filter-gebied en kiezen we als filter het BBP dan wordt alles duidelijk:
De periodes zijn natuurlijk kwartalen en de waarde stelt een index voor (zie de indicatie in de item-naam).
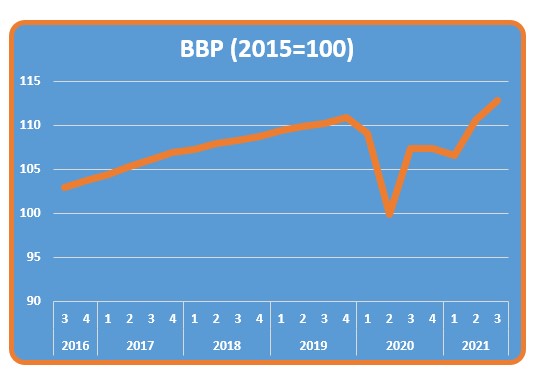
Nog even een draaigrafiek maken via Hulpmiddelen voor draaitabellen/ Analyseren (en wat opmaak) en we zien de ontwikkeling van het BBP over de jaren.
Kies je een ander Item in het Filter-gebied dan krijgen we direct de daarbij behorende grafiek:
Het zou natuurlijk mooi zijn als de achtergrondkleur zich zou aanpassen aan het gekozen item, maar dat is niet de scope ….
Wat we wel kunnen verbeteren is de manier van filteren, namelijk met behulp van een slicer (wel de scope!):
klik ergens in de draaitabel (of in de draaigrafiek)
kies in de menutab Hulpmiddelen in het onderdeel Analyseren in het blok Filter de optie Slicer invoegen
selecteer het veld (of velden) waarvoor je een slicer wilt
en klik OK
In dit voorbeeld hebben we (uiteraard) gekozen om te filteren op Item. Er ontstaat dan een slicer waarbij alle beschikbare item-namen onder elkaar staan.
Klik je in de kop van een slicer dan komt er een menutab Hulpmiddelen voor slicers tevoorschijn. Binnen de Opties hebben we het aantal Kolommen op 2 ingesteld en een Slicerstijl gekozen die qua kleur bij de grafiek past. Nog even de breedte en hoogte aanpassen (via de grepen aan de randen) en klaar!
Slicer met meerdere koppelingen
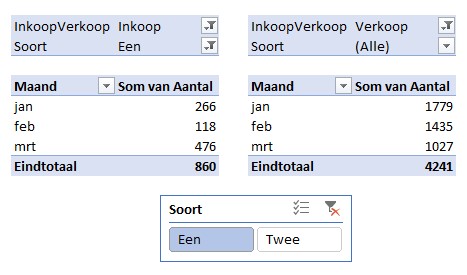
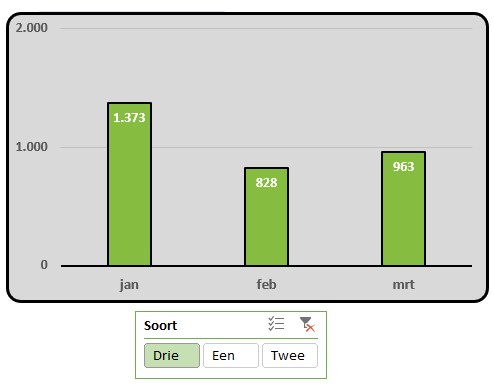
In het tabblad SlicerDubbel van het voorbeeldbestand staat een simpel voorbeeldje met een tabel van Inkopen en Verkopen. Op deze tabel zijn twee draaitabellen gebaseerd.
Aan de eerste draaitabel is een slicer gekoppeld, waarbij de Soort Een is gefilterd. Het zou natuurlijk mooi zijn als ook tegelijkertijd de tweede draaitabel wordt gefilterd.
NB als je een slicer toevoegt is het niet noodzakelijk dat dat onderdeel ook in het Filter-gebied van de draaitabel is geplaatst. In dit geval zou je dus Soort uit de kop van de draaitabellen kunnen verwijderen. De slicer maakt al duidelijk wat er gefilterd wordt.
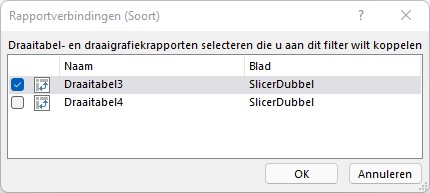
Een slicer koppelen aan meerdere draaitabellen:
klik in de kop van de slicer; daarmee selecteer je deze.
in de menutab Hulpmiddelen voor slicers in de Opties kies je de optie Rapportverbindingen
selecteer de draaitabellen die met behulp van deze slicer gefilterd moeten worden:
LET OP dit koppelen aan meerdere draaitabellen kan alleen wanneer de draaitabellen op dezelfde brongegevens zijn gebaseerd.
Soorten filters
Excel kent (op dit moment) 2 soorten filters: de Slicer zoals we die hiervoor al hebben gezien en een Tijdlijn. Deze laatste kan alleen maar gebruikt worden wanneer de brongegevens een kolom met datums bevat.
Als voorbeeld hebben we aan de tabel met misdrijven een kolom JrMnd toegevoegd, waarin de Jaar– en Maand-kolommen worden gecombineerd (zie het tabblad Veiligheid2 in het voorbeeldbestand).
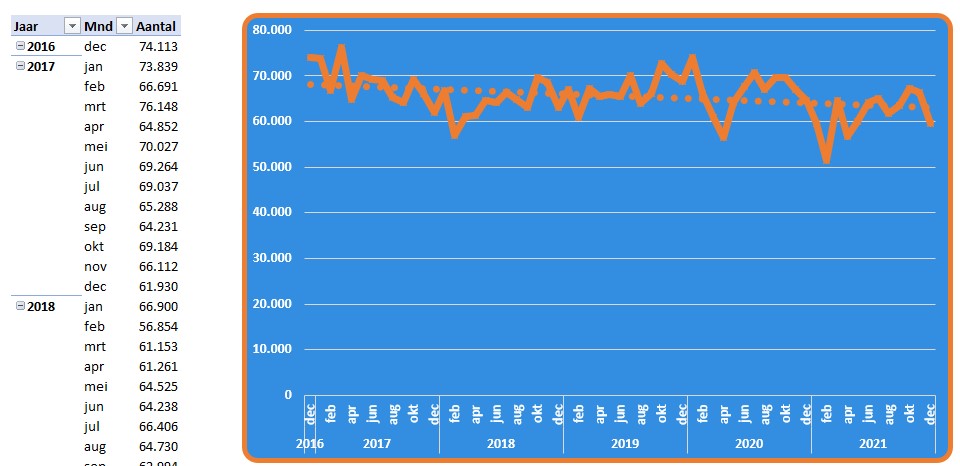
Op basis van deze gegevens zijn weer een draaitabel en een draaigrafiek gemaakt. Door aan de grafiek ook nog een (lineaire) trendlijn toe te voegen is de tendens in de tijd goed te zien.
NB bij het maken van de draaitabel is het veld JrMnd naar het Rij-gebied gesleept. Excel ‘ziet’ dat het om een datum gaat en maakt direct meerdere velden aan in dat gebied. In dit geval, omdat de reeks meerdere jaren bevat, Jaar en daarnaast ook nog Kwartaal en de Maand. Geen Dag omdat Excel denkt, dat het niet zinvol is om zaken op dagbasis te rubriceren. Wil je dat wel dan moet je zelf de groepering van de datum aanpassen (zie Groeperen in een draaitabel).
In plaats van een Slicer voegen we nu een Tijdlijn in.
Dit is een heel handig hulpmiddel als je snel de resultaten van verschillende periodes wilt bekijken.
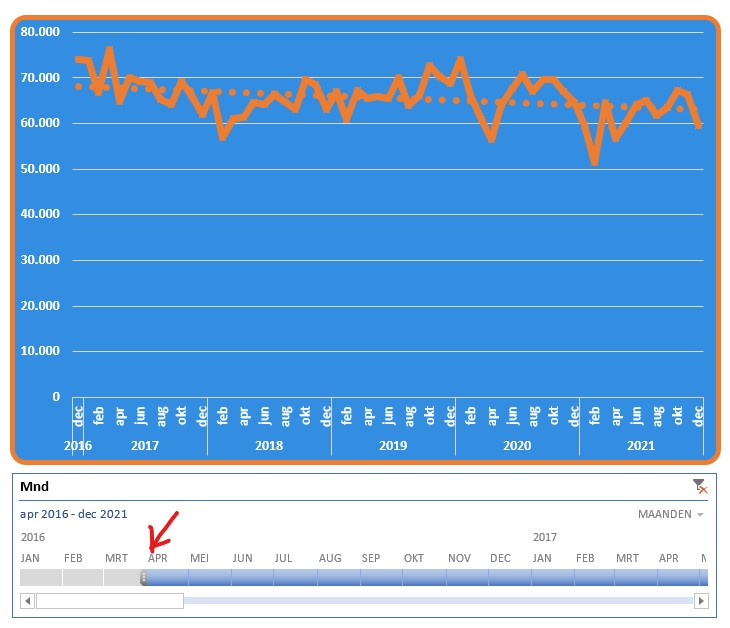
In dit geval hebben we gegevens van 5 jaren tot onze beschikking (en nog een maand in 2016, dus voor Excel 6 jaar); willen we een selectie maken dan moeten we met de schuifbalk onderaan aan de gang.
Het tijdsbestek kunnen we inperken door aan de zijkanten de begrenzing te verschuiven (zie het rode pijltje hierboven). Ook kun je maanden selecteren door op het blokje onder een maand te klikken, eventueel met Shift ingedrukt om een reeks maanden te kiezen.
NB je kunt geen ‘losse’ maanden selecteren, alleen een reeks aaneengesloten perioden.
In de Tijdlijn linksboven zie je altijd de huidige selectie; aan de rechterkant kun je de soort periode kiezen.
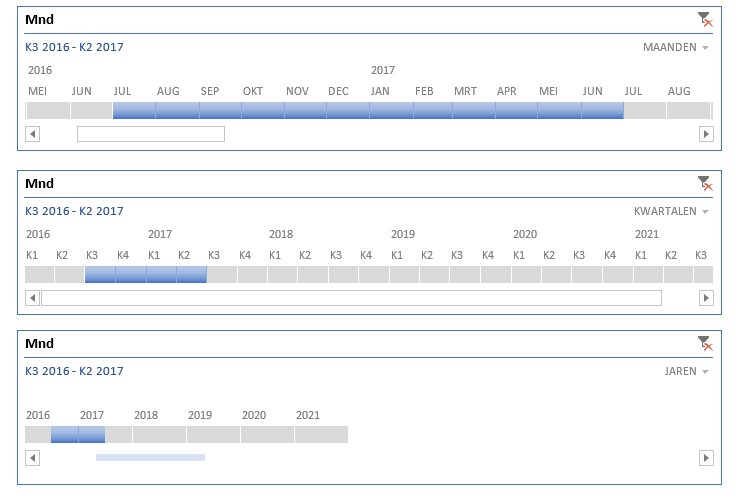
In het voorbeeld hebben we de Tijdlijn 2 keer gekopieerd met ieder een andere periodesoort.
Duidelijk is te zien dat een keuze in de ene Tijdlijn invloed heeft op de anderen.
Slicer-instellingen
Op allerlei manieren zijn Slicers (en Tijdlijnen) nog te fine-tunen.
De kopregel van de slicer is lang niet altijd nodig en misschien wel ongewenst wanneer die bijvoorbeeld de lay-out van je dashboard verstoort.
In het voorbeeld op het tabblad Huw2 van het voorbeeldbestand is het ook duidelijk zonder kop wat de 2 keuzemogelijkheden inhouden.
Klik met de rechtermuisknop op een slicer, kies de optie Slicerinstellingen en verwijder het vinkje bij Koptekst weergeven:
NB om alle filteringen in één keer ongedaan te maken is nu iets moeilijker; je kunt niet meer de -button in de slicerkop gebruiken. Klik rechts op de slicer en kies Filter wissen uit.
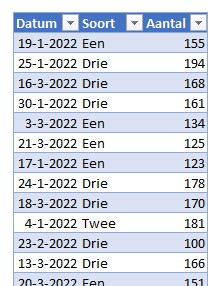
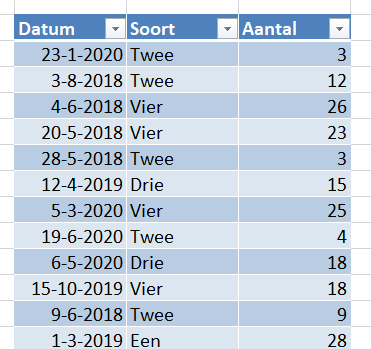
Om nog enkele andere slicer-instellingen te laten zien bevat het tabblad Instellingen van het voorbeeldbestand een tabelletje met per Datum en Soort een Aantal.
Op de bekende manier laten we daar een draaitabel op los en maken dan een draaigrafiek.
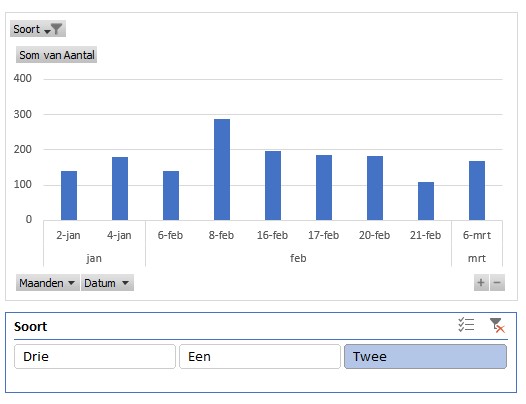
Nog een slicer voor de Soort en we kunnen analyseren.
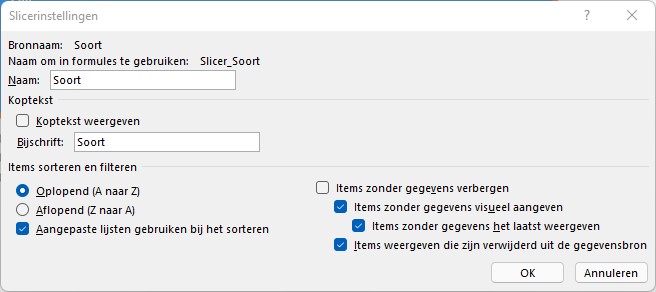
Vervelend: de sortering in de slicer is niet zoals we zouden willen.
Maar in de Slicerinstellingen kunnen we alleen voor oplopend of aflopend kiezen en deze sortering is niet, zoals bij een draaitabel, handmatig aan te passen.
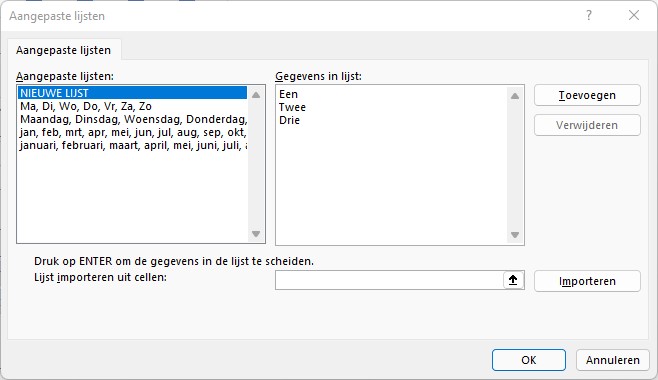
Wel ziet u bij de instellingen staan dat Excel rekening kan houden met Aangepaste lijsten.
scrol helemaal naar beneden en daar ziet u onder het kopje Algemeen een button Aangepaste lijsten bewerken
tik de lijst in, in de gewenste volgorde, en kies Toevoegen
NB1 hier zie je ook waarom Excel de dagen van de week en maanden altijd in de juiste volgorde plaatst bij een sortering.
NB2 je moet nog wel de draaitabel (of -grafiek) vernieuwen om de sortering in de slicer daadwerkelijk uit te laten voeren.
NB3 deze lijst wordt in het Excel-systeem vastgelegd en zal dus ook in andere werkmappen toegepast kunnen worden. Ook in nog nieuw te ontwikkelen systemen.
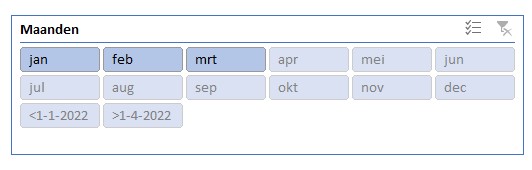
Voor deze draaitabel is ook een slicer voor de Maanden gemaakt. In de slicer zijn diverse periodes ‘grijs’.
Dat betekent dat die niet meer in de bron voorkomen of door een andere filtering nu niet meer actief zijn in de draaitabel. In Slicerinstellingen kunt u de optie Items zonder gegevens verbergen aanvinken.
Opmaak van slicers
Door middel van de Slicerinstellingen, zoals hiervoor aangegeven, kunt u de lay-out van een slicer al behoorlijk aanpassen.
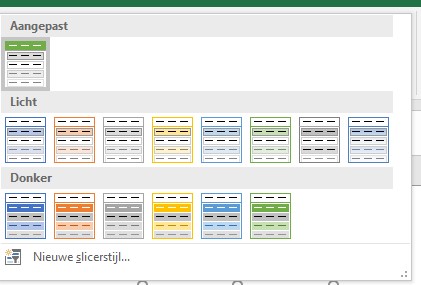
Via de menutab Hulpmiddelen voor slicers/Opties kun je ook een Slicerstijl kiezen, 8 lichtgekleurde varianten en 6 donkere.
Op het tabblad Opmaak van het voorbeeldbestand hebben we een groen/grijze grafiek gecombineerd met een slicer met als stijl Licht6.
Wilt u de slicer helemaal naar uw eigen hand zetten:
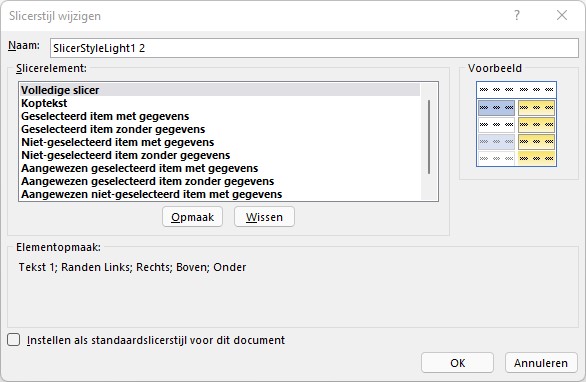
klik met de rechter muisknop op de variant die het meest lijkt op hoe u het wilt hebben.
kies de optie Dupliceren
pas de naam aan
kies een onderdeel (Volledige slicer, Koptekst et cetera) en klik op de button Opmaak
herhaal het vorige punt voor alle onderdelen die u wilt aanpassen
klik op OK In dit voorbeeld is de kop flink onder handen genomen, hebben we de rand van de slicer weggelaten en hebben we ook de kleuren van de niet-geselecteerde items aangepast.
Deze opmaak wordt bij de Slicerstijlen onder het kopje Aangepast opgeslagen; zie het voorbeeld KopGroen in het voorbeeldbestand.
NB1 zoals u ziet kunt u deze stijl ook als standaard voor alle NIEUWE slicers instellen
NB2 experimenteer met de diverse opties om te kijken wat het resultaat is.
LET OP de draaitabel op het tabblad Opmaak is onder de grafiek verborgen.
Slicer gekoppeld aan tabel
Tot nu toe hebben we slicers alleen gebruikt om gegevens in een draaitabel te filteren. Maar slicers kunnen ook toegepast worden op Excel-tabellen (zie het tabblad Huw van het voorbeeldbestand). Een groot nadeel is, dat de filtering in de tabel die daardoor wordt uitgevoerd, er voor zorgt dat sommige gedeelten van het tabblad niet meer zichtbaar zijn (kies maar eens Partner als filtering).
Wanneer je een slicer aan de draaitabel koppelt, heb je dat probleem niet. En het gewenste resultaat (de grafiek in dit geval) wordt automatisch aangepast.
Totalen in een grafiek weergeven, dat is simpel: voeg de betreffende reeks toe aan de grafiek-gegevens. Misschien dat je deze reeks nog aan de secundaire as moet koppelen, maar daarmee ben je klaar.
Maar bij een draai-grafiek (een grafiek gebaseerd op een draaitabel) zul je merken dat je wel wat flexibiliteit inlevert; dan is een lijntje met totalen toevoegen niet mogelijk. Met VBA kun je een heel eind komen, maar zonder programmeren niet. In dit artikel wat alternatieve mogelijkheden.
Basis-gegevens
We gaan uit van een tabel (tblData2 op het tabblad Data van het Voorbeeldbestand) met daarin Datums en het Soort artikel met een bijbehorend Aantal.
Wil je zien hoe dit overzicht tot stand is gekomen: kijk op het tabblad Basis van het Voorbeeldbestand. Daar worden telkens random nieuwe data gecreëerd.
Draaitabel
Om deze gegevens snel te kunnen analyseren maken we een draaitabel:
selecteer een cel in de brongegevens
klik in de menutab Invoegen in het blok Tabellen op de optie Draaitabel en dan op de button OK
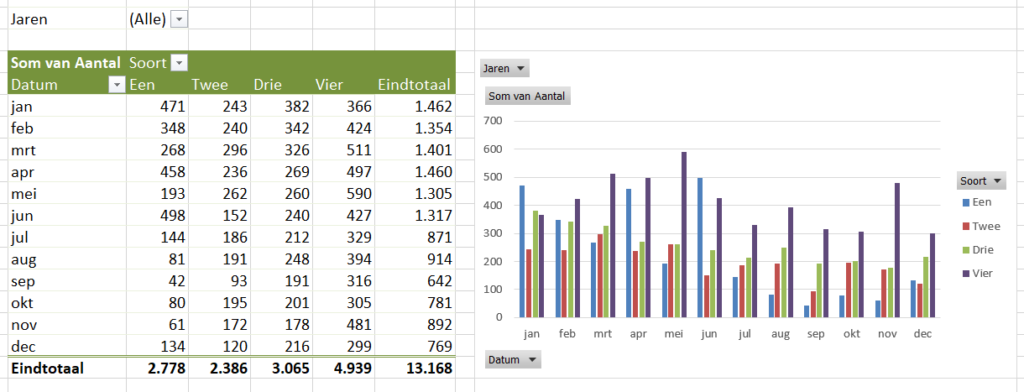
sleep de Datum naar het Rijen-gebied, Soort naar de Kolommen en Aantal naar het Waarden-gebied
standaard zal Excel de datums direct groeperen (in Jaren, Kwartalen en Maanden) LET OP één van de namen in de Rijen is nog steeds Datum, maar deze bevat nu de maanden. Wil je een andere groepering? Zie het artikel Groeperen in een draaitabel.
sleep Jaren naar het Filters-gebied en verwijder Kwartalen uit de Rijen.
de Soort is alfabetisch gesorteerd: versleep de kolom met de waarde Drie naar rechts (door de rand met de muis ‘vast te pakken’). Het resultaat staat in het tabblad Ovz1 van het Voorbeeldbestand.
Draaigrafiek
Een grafiek maakt de onderlinge verhoudingen tussen de cijfers vaak een stuk duidelijker:
selecteer een cel van de draaitabel
kies in de menutab Hulpmiddelen voor draaitabellen/Analyseren in het blok Extra de optie Draaigrafiek
kies de optie Gegroepeerde kolom en klik op OK
Verander je nu iets in de draaitabel (filter je bijvoorbeeld een bepaald jaar uit) dan past de grafiek zich automatisch aan.
Draaigrafiek aanpassen 1
De standaard-grafiek kent wel wat nadelen. Allereerst willen we van die ‘lelijke’ veldknoppen af: klik rechts op één van de knoppen en kies de optie Alle veldknoppen verbergen in grafiek.
Op het tabblad Ovz2 van het Voorbeeldbestand staat het resultaat:
LET OP Excel geeft alle kolommen automatisch een kleur; normaal wijzig ik deze handmatig in vaste kleuren zodat ook bij filtering iedere Soort zijn eigen kleur houdt. Helaas: bij draaigrafieken worden deze instellingen door Excel niet vastgehouden.
Draaigrafiek aanpassen 2
Ook al is een grafiek bedoeld om intuïtief inzicht in de onderliggende cijfers te krijgen, dan nog werkt het goed (of is het zelfs noodzakelijk) om in een grafiek de waarde(s) van de belangrijkste gegeven(s) te laten zien.
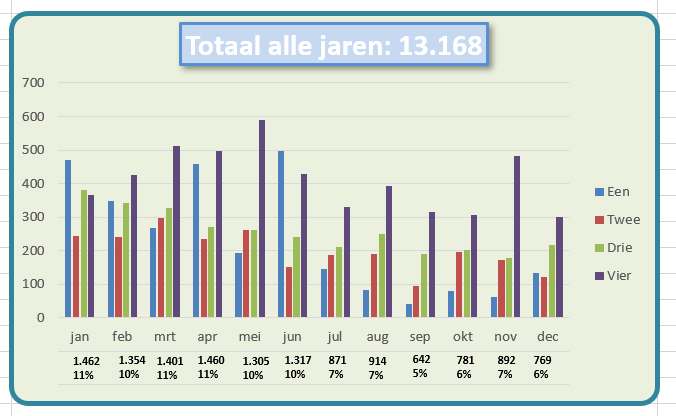
In het tabblad Ovz3 van het Voorbeeldbestand heeft de grafiek een veelzeggende titel meegekregen:
in een lege cel creëren we daartoe eerst de volgende formule: =ALS(C2=”(Alle)”; “Totaal alle jaren: “; “Totaal voor ” & C2 &”: “) & TEKST(DRAAITABEL.OPHALEN(“Aantal”;$B$4);”#.##0″) Als in cel C2 alle jaren zijn gekozen dan nemen we een overeenkomende tekst, anders wordt de tekst Totaal voor met daarachter de inhoud van cel C2 (gekoppeld door het &-teken). Achter de zo gemaakte tekst plaatsen we met behulp van de functie DRAAITABEL.OPHALEN (zie het betreffende artikel) het totaal van Aantal. Met de functie Tekst geven we een opmaak mee (een punt voor de duizendtallen en geen decimalen).
zorg dat de grafiek een Grafiektitel heeft; bijvoorbeeld op de volgende manier: selecteer de grafiek en klik op de + rechts daarvan en vink de betreffende optie aan.
klik op de Grafiektitel en daarna in de formulebalk. Tik in = en klik dan op de cel uit de eerste stap (in Ovz3 is dat cel I2). In de formulebalk komt dan automatisch de formule: =’Ovz3′!$I$2. Druk op Enter.
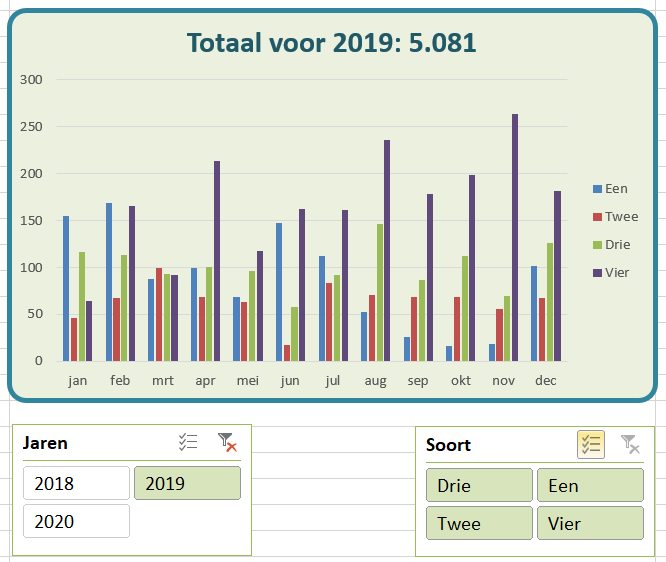
Nog een paar slicers toevoegen (zie Slicers in Excel) en we hebben (het begin van) een interactief dashboard.
Bij het filteren in de draaitabel (hier mer behulp van slicers) kan het gebeuren dat het scherm ‘verspringt’; door een paar aanpassingen aan de draaitabel blijft de opmaak stabiel:
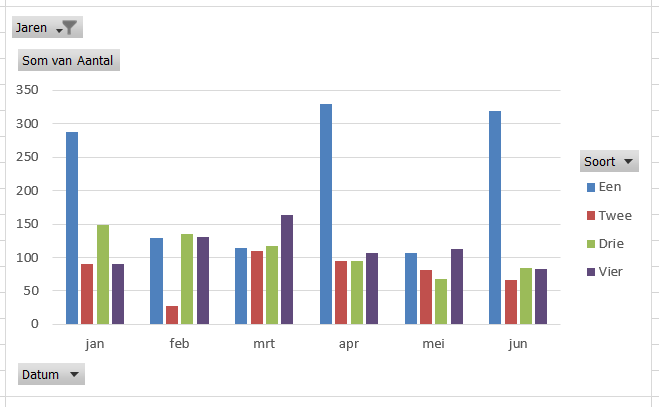
om te zorgen dat in jaren waar (nog) niet alle maanden gevuld zijn (in het voorbeeld 2020), toch alle maanden zichtbaar zijn (en dus ook in de grafiek): klik rechts op een van de maanden in de draaitabel, kies Veldinstellingen, vink op het tabblad Indeling&afdrukken de optie Items zonder gegevens weergevenaan
klik rechts op een van de cellen in het Waarden-gebied, kies Opties voor draaitabel en vink de optie Kolombreedte automatisch aanpassenuit
Draaigrafiek aanpassen 3
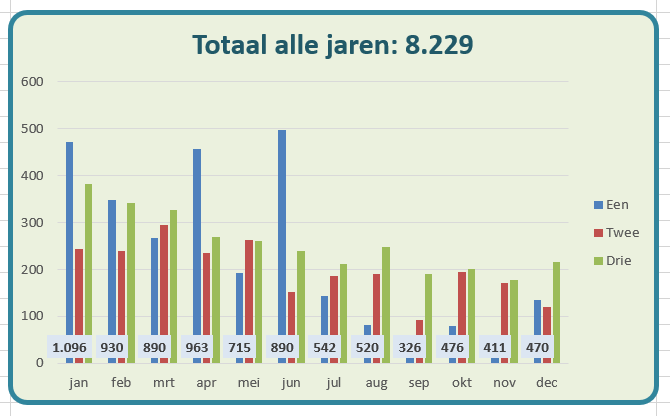
Maar we zijn niet gauw tevreden: we hebben nu het totaal aantal in de titel staan, maar wat zijn de totalen per maand? In de draaitabel staan de betreffende getallen netjes op het einde van iedere rij, maar we zien die niet terug in de grafiek.
Nog erger: er is ook geen optie om dat klaar te krijgen! Uiteraard kunnen we met VBA aan de slag, maar daar is wel wat programmeer-arbeid voor nodig. Eens even kijken of het ook zonder kan: ja natuurlijk, we zorgen dat één reeks labels heeft en laten de inhoud van die labels wijzen naar de totalen per maand.
zorg dat ergens in het tabblad een reeks cellen gevuld is met de rij-totalen. In het tabblad Ovz4 staan in de cellen C24:C35 verwijzingen naar de draaitabel met behulp van de functie DRAAITABEL.OPHALEN.
klik op één van de kolommen in de grafiek
klik op de + rechts van de grafiek en zet de Gegevenslabels aan, inclusief de optie Basis, binnenkant zodat alle labels op dezelfde hoogte komen
klik rechts op een van de labels en kies de optie Gegevenslabels opmaken
bij Labelopties kun je de waarden opgeven die weergegeven moeten worden (Waarde uit cellen). Maak hier een verwijzing naar de cellen C24:C35; vink de optie bij Waardeuit en dan Waarde uit cellenaan.
Helaas, deze methode heeft 2 (?) tekortkomingen (zie het tabblad Ovz4 van het Voorbeeldbestand):
de labels worden gecentreerd op de overeenkomende kolom
als de betreffende soort uitgefilterd wordt zijn ook de labels weg!
Draaigrafiek aanpassen 4
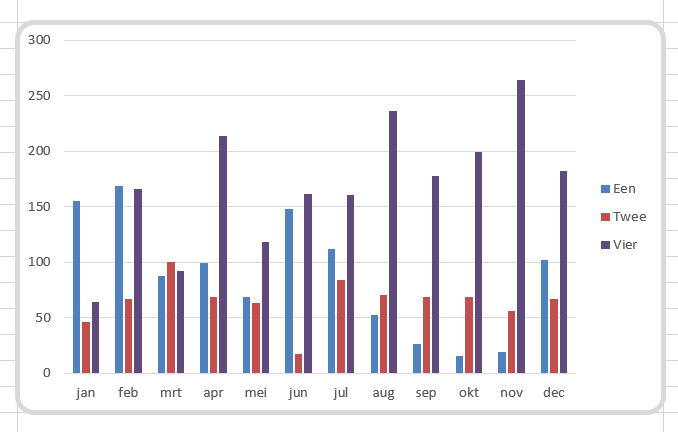
In het tabblad Ovz5 van het Voorbeeldbestand staat een grafiek die de totalen per maand toont, inclusief de procentuele verdeling over het jaar.
De volgende aanpassingen zijn doorgevoerd:
allereerst is er ruimte gemaakt onder aan de grafiek: klik rechts op de linkeras, kies As opmaken en zorg dat de minimumgrens niet meer automatisch wordt bepaald maar (in dit geval) -200 is
de notatie van de as is zodanig aangepast, dat de negatieve getallen niet worden weergegeven: #.##0;
vanaf cel C24 worden de maandtotalen opgehaald: =DRAAITABEL.OPHALEN(“Aantal”;$B$4;”Datum”;B24)
vanaf cel D24 bepalen we de inhoud van de teksten die we gaan toevoegen: =ALS(C24=0;””; TEKST(C24;”#.##0″)& TEKEN(13)& TEKST(C24/DRAAITABEL.OPHALEN(“Aantal”;$B$4);”0%”)) Als C24 nul is dan hoeft er niets weergegeven te worden, anders de inhoud van cel C24 samen met het resultaat van het maandresultaat (C24) gedeeld door het totale resultaat (weergegeven als percentage zonder decimalen); tussen de twee elementen staat een code 13 (‘naar de volgende regel’). NB in cel D24 en verder is het resultaat van code 13 niet te zien, maar dadelijk in de grafiek wel.
klik ergens in de grafiek en kies dan in de menutab Invoegen in het blok Illustraties de optie Vormen en daarna bij Basisvormen de optie Tekstvak en ’teken’ met de muis waar je het tekstvak wilt hebben LET OP als je niet eerst ergens in de grafiek klikt wordt het tekstvak niet aan de grafiek gekoppeld maar aan het tabblad; bij het verplaatsen van de grafiek gaat het tekstvak dan niet mee!
klik in de formulebalk, tik het =-teken en klik met de muis op de cel met de tekst die weergegeven moet worden
pas de grootte van de tekst en/of het tekstvak aan en verplaats het tekstvak naar de juiste plaats (pak met de muis de ‘rand vast’)
herhaal de stappen 5 t/m 7 voor alle maanden NB je kunt ook het eerste tekstvak kopiëren (Ctrl-C) en dan via Ctrl-V zoveel tekstvakken maken als nodig zijn. Die moeten dan nog verplaatst worden en de inhoud aangepast.
Vanaf 31 maart publiceert het RIVM andere gegevens dan daarvoor. Helaas is het dus niet meer mogelijk om via het voorbeeldbestand de (ver)spreiding van Corona op een consistente manier te volgen. Op de site https://nlcovid-19-esrinl-content.hub.arcgis.com/ zijn wel nog diverse overzichten en kaarten te vinden.
Corona: de laatste weken beheerst deze crisis niet alleen het nieuws maar ook ons leven. Het einde is nog niet in zicht. Het zou mooi zijn als we met Excel een bijdrage zouden kunnen leveren aan de oplossing er van. Helaas, maar wat we wel kunnen, is proberen inzicht te geven in de omvang en voortgang van de besmettingen en overlevenden.
Het RIVM publiceert dagelijkse nieuwe gegevens en ook een kaartje dat de verspreiding van de besmettingen laat zien.
Voor G-Info is dit een goede aanleiding om eens te kijken hoe we van gegevens, die we over Corona kunnen vinden, informatie kunnen maken. Niet voor niets is onze hoofddoelstelling: van Gegevens naar Informatie.
In dit artikel gaan we eerst op zoek naar gegevens rond Corona. Daarna kijken we welke informatie we daaraan kunnen ontlenen. We zullen daarom diverse (vaak met behulp van draaitabellen gemaakte) overzichten bekijken. Als laatste zult u zien dat Voorwaardelijke opmaak heel handig is om snel binnen een grote hoeveelheid gegevens de uitschieters te signaleren.
Brongegevens
In dit artikel focussen we ons op de situatie in Nederland. Het is dan ook logisch dat we terecht komen bij het RIVM. Dit instituut publiceert iedere dag een update van de situatie op hun website rivm.nl.
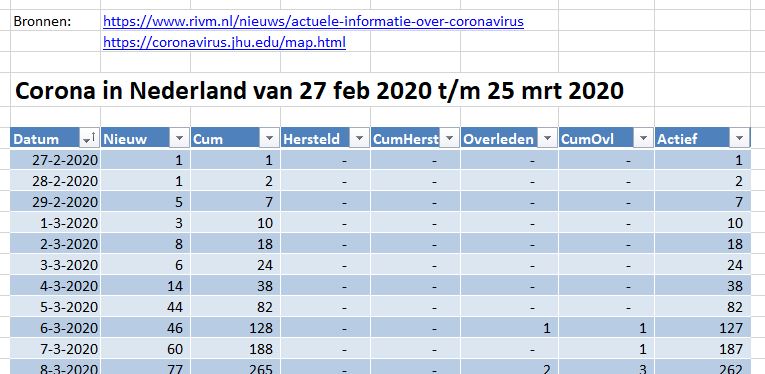
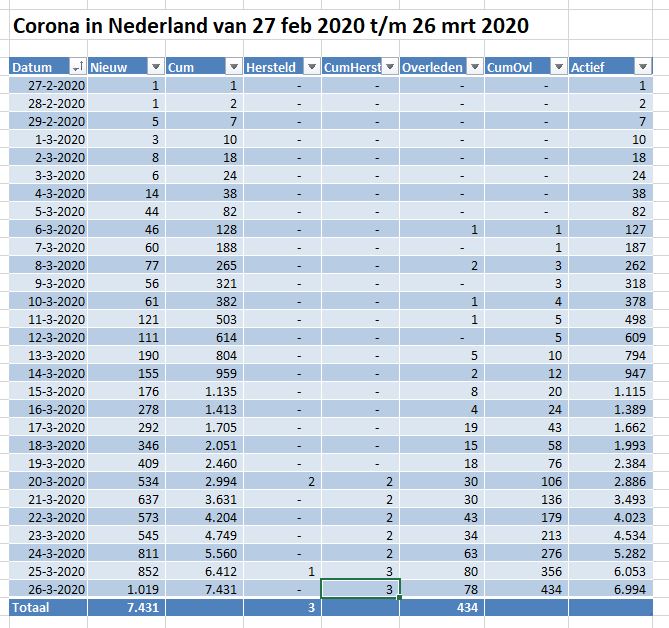
Op deze site hebben we vanaf de uitbraak in Nederland kunnen terugvinden hoeveel mensen er besmet zijn geraakt en hoeveel daarvan er ondertussen zijn overleden (zie het tabblad DataNed van het Voorbeeldbestand).
Deze gegevens zijn dagelijks handmatig ingevoerd in een Excel-tabel met de naam tblNed. De kolom Cum bevat een formule, die een lopend cumulatief bepaalt (in cel D9 staat bijvoorbeeld =D8+C9); op een vergelijkbare manier worden ook de 5e en 7e kolom gevuld. In de laatste kolom (Actief) berekenen we het aantal personen, dat op dit moment nog besmet is: =[@Cum]-[@CumHerst]-[@CumOvl].
NB1 het RIVM geeft aan, dat de door hen gehanteerde cijfers geen exacte waarheid weergeven: “Het werkelijke aantal besmettingen met het nieuwe coronavirus ligt hoger dan het aantal dat hier genoemd wordt. Dit komt omdat niet iedereen met mogelijke besmetting getest wordt, maar vooral patiënten die zo ziek zijn dat ze in het ziekenhuis opgenomen worden en zorgverleners. Het aantal gemelde patiënten en overleden patiënten kan per dag verschillen om verschillende redenen. Zo zien we dat overleden patiënten niet altijd op dezelfde dag gemeld worden.” Voor inzicht in de verspreiding lijken ze mij echter significant genoeg.
NB2 gegevens over personen, die hersteld zijn, zijn niet bekend bij het RIVM of worden niet geregistreerd. Op de website van de Johns Hopkins University over Corona worden wel aantal vermeld. Of deze op dit moment de werkelijkheid benaderen betwijfel ik.
NB3 dit artikel is in de loop van enkele dagen geschreven. Aangezien de werkmap in die dagen continu is bijgewerkt kunnen data in de afbeeldingen afwijken van die in het Voorbeeldbestand.
NB4 boven de tabel staat een dynamische kopregel; de inhoud past zich aan aan de datums in de tabel: =”Corona in Nederland van “&TEKST(MIN(tblNed[Datum]);”d mmm jjjj”)&” t/m “&TEKST(MAX(tblNed[Datum]);”d mmm jjjj”) Teksten worden aan elkaar gekoppeld met behulp van het &-teken; de minimum- en maximum-datum wordt met behulp van de functie Tekst van het gewenste formaat voorzien.
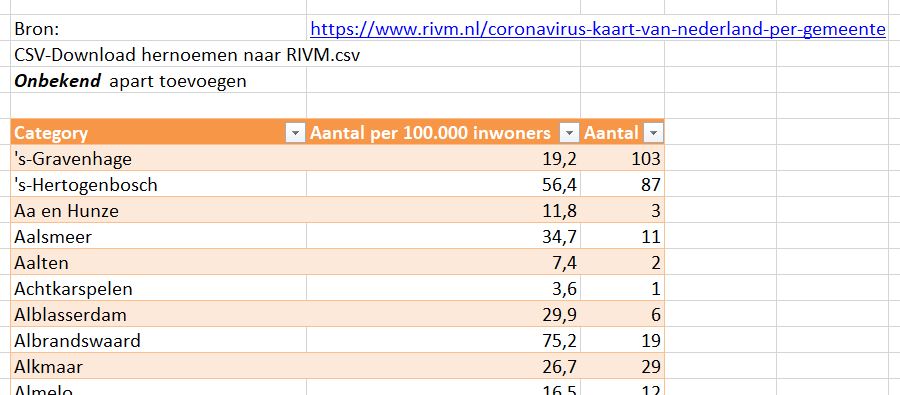
Als tweede bron is dagelijks een bestand gedownload van de RIVM-site (via het pijltje naast de kaart met gemelde Corona-gevallen).
In het Voorbeeldbestand is dit geautomatiseerd via de Power Query-tabel op het tabblad DagInput. Het bestand bevat het totaal aantal bekende Corona-gevallen per gemeente. Om de resultaten van de gemeentes met elkaar te kunnen vergelijken is dit aantal genormaliseerd (de kolom Aantal per 100.000 inwoners), namelijk door te delen door het aantal inwoners van die gemeente (en met 100.000 te vermenigvuldigen).
Deze gegevens (zonder de kopregel) zijn iedere dag gekopieerd naar de Excel-tabel tblGem op het tabblad DataGem van het Voorbeeldbestand.
LET OP vanaf 27 maart bevat het bestand van het RIVM 4 namen van gemeenten, die anders gespeld worden dan daarvoor: Bergen (L.) moet zijn: Bergen (L) Bergen (NH.) moet zijn: Bergen (NH) Hengelo moet zijn: Hengelo (O) s-Gravenhage moet zijn: ‘s-Gravenhage (in de Excel-cel moet dus een dubbele ‘ komen) De Power Query routine is hier op aangepast, anders met de hand wijzigen in de tabel tblGem.
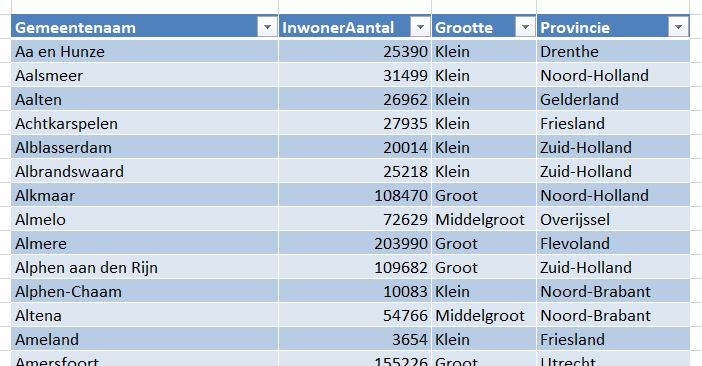
Een ander bronbestand (zie het tabblad ProvGemeente) is een overzicht van alle gemeentes in Nederland met daarachter het inwoneraantal, een indeling naar klein, middelgroot en groot en de bijbehorende provincie.
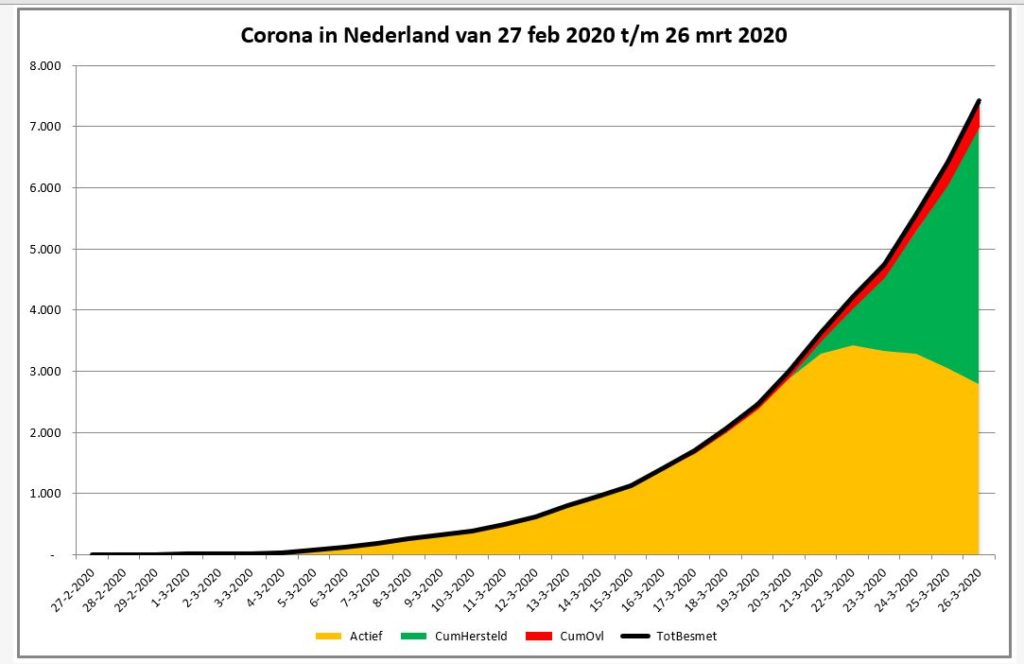
Het overzicht in het tabblad DataNed van het Voorbeeldbestand laat het verloop in de tijd zien van het aantal besmettingen, overledenen en herstelden. Maar hoe de getallen zich tot elkaar verhouden is moeilijk te onderscheiden. Een grafiek is geschikter om dit te laten zien:
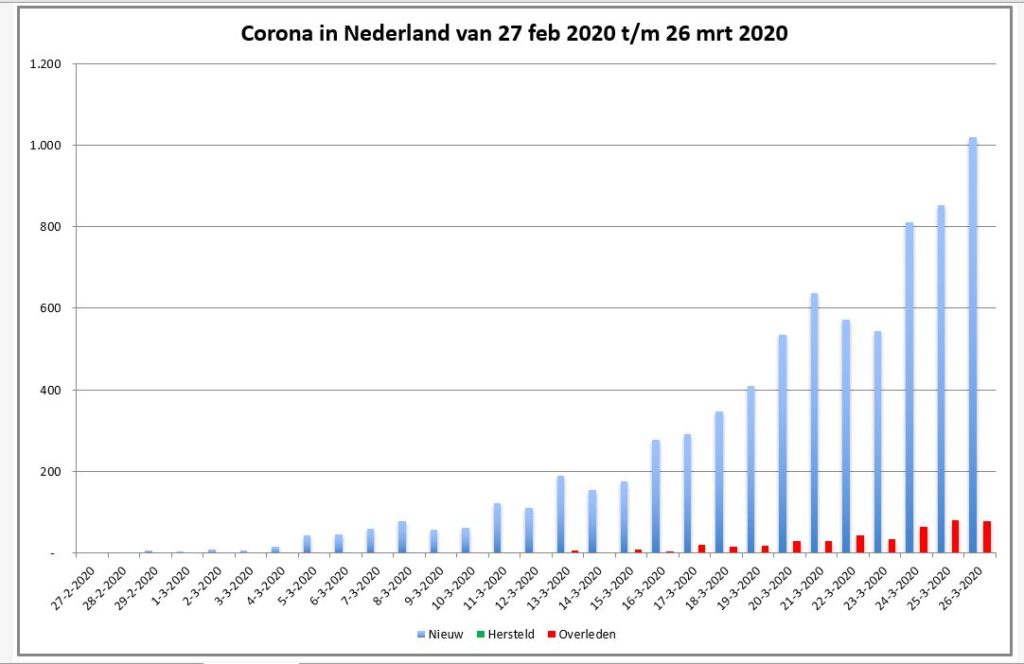
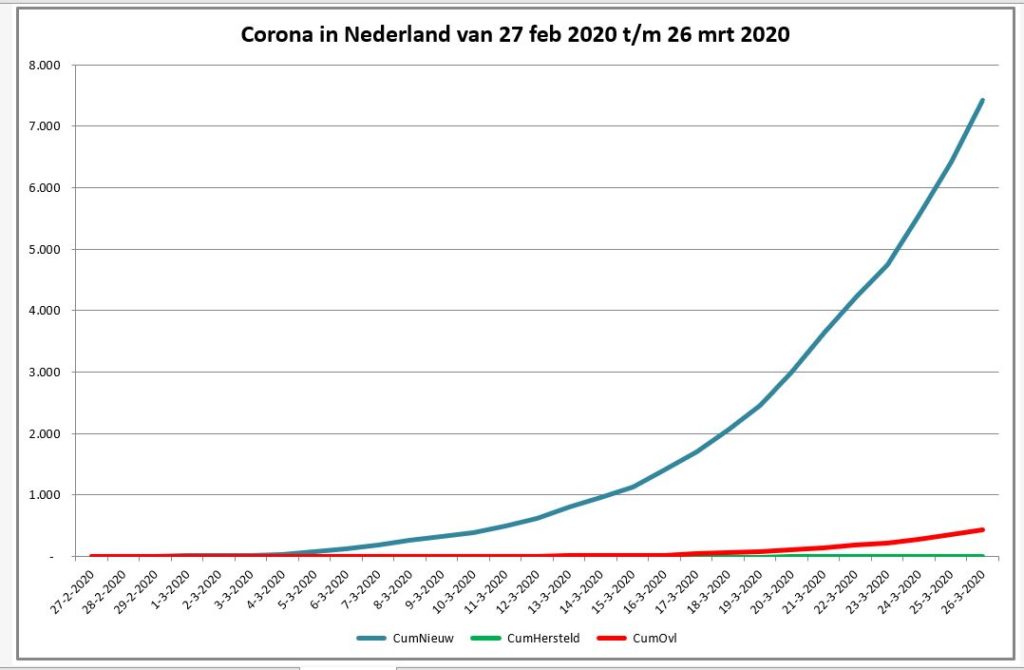
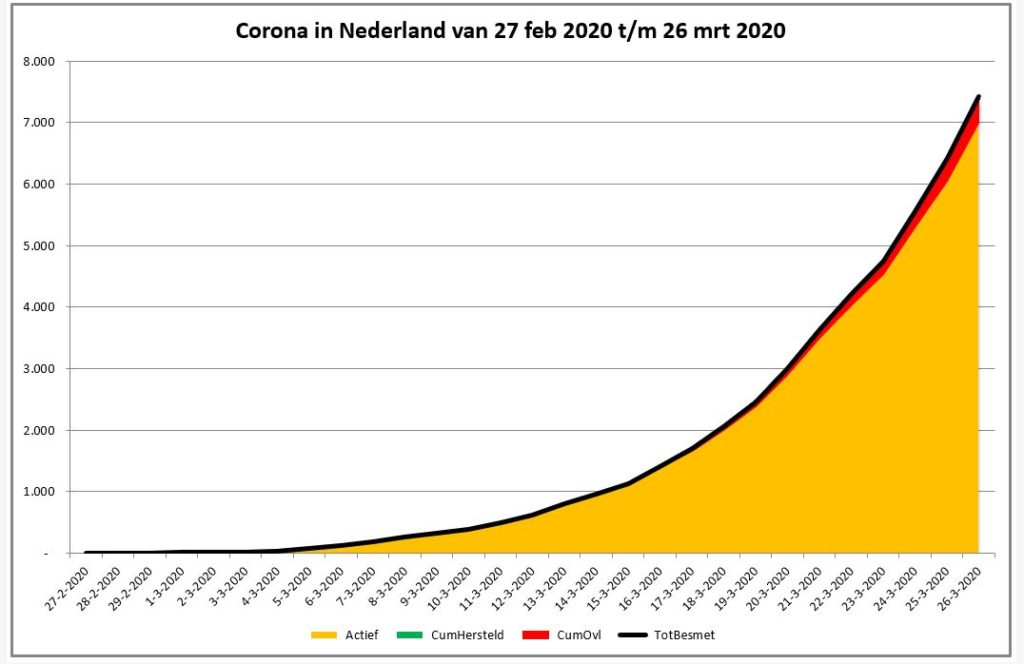
De eerste grafiek (staafdiagram) laat het aantal nieuwe geregistreerde besmettingen, herstelden en overledenen per dag zien (tabblad GrafNed1). De lijngrafiek (tabblad GrafNed2) toont de cumulatieven daarvan in de tijd. In de derde grafiek (tabblad GrafNed3) wordt door het gebruik van vlakken de opdeling van het aantal cumulatieve besmettingen zichtbaar gemaakt.
NB1 bij het schrijven van dit artikel was het aantal herstelden nog gering (volgens de gehanteerde bronnen); resultaten daarvan zijn in de grafieken dan ook nauwelijks/niet zichtbaar.
NB2 in de laatste grafiek moet het oranje vlak (de actieve besmettingen) in de loop van de tijd steeds meer de veel besproken ‘uitgevlakte’ curve laten zien. Het groene vlak (herstelden) zal steeds groter moeten worden. Een fictief voorbeeld staat hiernaast.
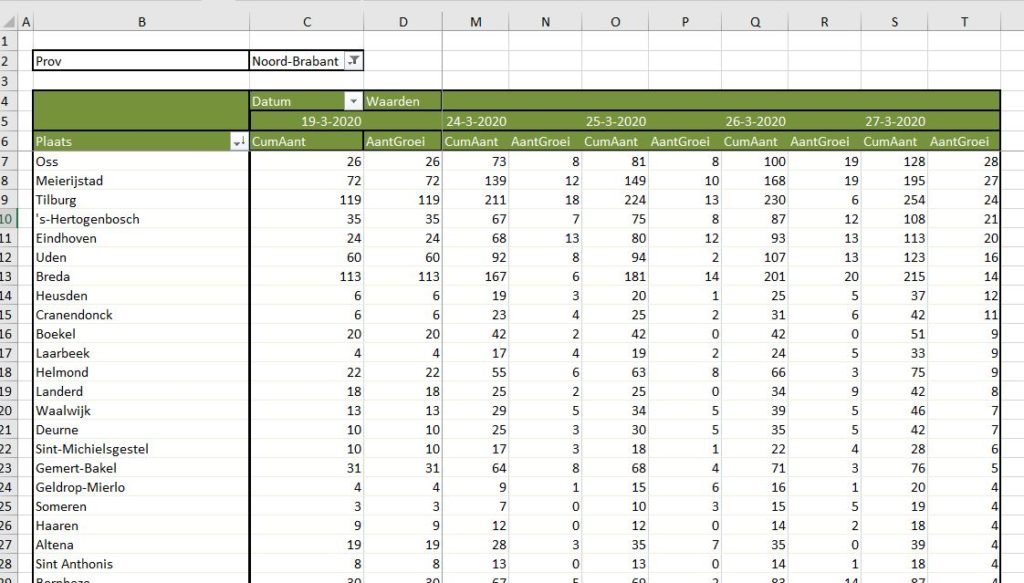
Overzicht per gemeente, basis
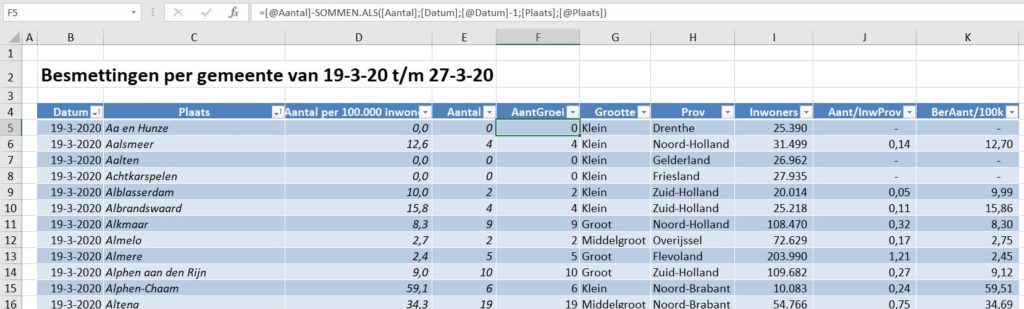
Zoals bij de bronnen aangegeven bevat het tabblad DataGem van het Voorbeeldbestand de totaal-aantallen geregistreerde besmettingen per gemeente per dag.
Om hierna diverse analyses op de gegevens uit te kunnen voeren zijn de brongegevens in deze tabel verrijkt:
in kolom F wordt de dagelijkse groei van het aantal voor een gemeente berekend: =[@Aantal]-SOMMEN.ALS([Aantal];[Datum];[@Datum]-1;[Plaats];[@Plaats]) Trek van het Aantal in een bepaalde rij het Aantal af van de vorige dag bij die gemeente. NBSOMMEN.ALS telt alle Aantallen op waarvan de Datum gelijk is aan de Datum in die regel minus 1 en waar de Plaats gelijk is aan de Plaats in die regel. In principe is er altijd maar 1 geval, die aan deze voorwaarden voldoet.
de indeling van de gemeente naar grootte wordt in kolom G bepaald door dat gegeven op te zoeken in tblGemProv in het tabblad ProvGemeente: =INDEX(tblGemProv[Grootte];VERGELIJKEN([@Plaats];tblGemProv[Gemeentenaam];0))
op een vergelijkbare manier worden in de kolommen H en I respectievelijk de provincie en het aantal inwoners van een gemeente opgehaald.
de genormaliseerde aantallen per gemeente (uitgedrukt in Aantal besmettingen per 100.000 inwoners) wordt door het RIVM aangeleverd; kolom D. Om provincies goed met elkaar te kunnen vergelijken moeten ook de aantallen per provincie worden genormaliseerd. In kolom J wordt de benodigde berekening uitgevoerd: =[@Aantal]/ INDEX($N$5:$N$16;VERGELIJKEN([@Prov];$M$5:$M$16;0)) *100000 NB de kolommen M en N bevatten een draaitabel die het aantal inwoners per provincie bepaald.
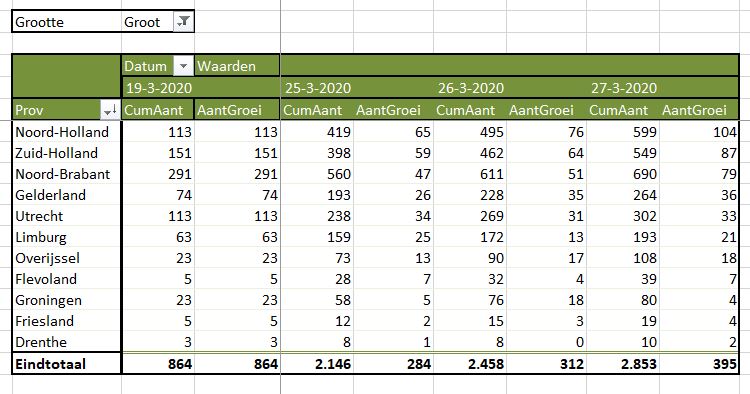
Overzicht per provincie (1)
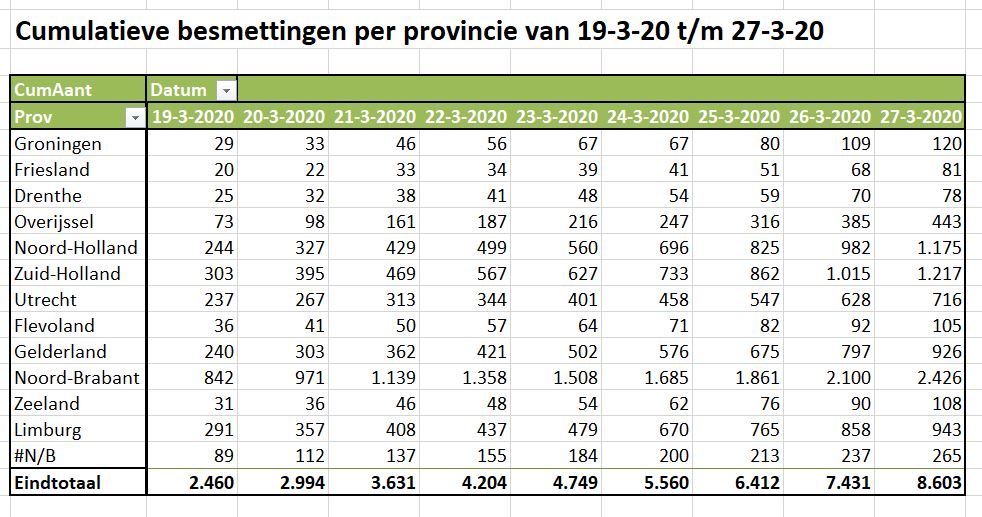
Waar in Nederland zitten de meeste Corona-gevallen? Met behulp van een draaitabel kunnen we snel een overzicht per provincie maken (gerangschikt van noord naar zuid; zie tabblad OvzProv1 van het Voorbeeldbestand):
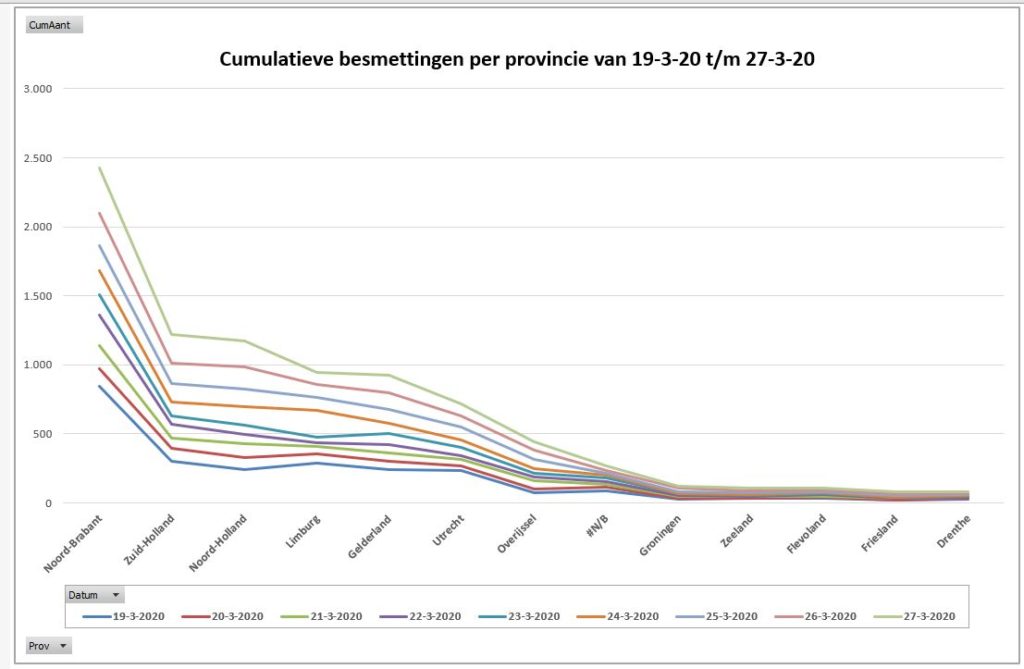
Uit de bijbehorende draaigrafiek kunnen makkelijker conclusies getrokken worden (tabblad GrafProv1):
in absolute zin is het aantal besmettingen vanaf het begin (van de registratie in dit Excel-bestand, 19 maart) het grootst in Noord-Brabant, gevolgd door Noord- en Zuid-Holland en Gelderland en Limburg.
Deze laatste provincie kende een relatief grote groei op 24 maart.
De hoop dat de groei in Brabant zou gaan afvlakken zien we nog niet terug (dan zouden de lijnen daar steeds dichter bij elkaar moeten gaan liggen; op 27 maart zien we zelfs weer een groei) .
Ook neemt de groei in Noord- en Zuid-Holland toe.
In Limburg blijft de groei de laatste dagen gelijk.
De noordelijke provincies en Flevoland en Zeeland lijken nog weinig ‘geraakt’.
LET OP wanneer er gegevens voor een nieuwe datum zijn toegevoegd dan moet de draaitabel vernieuwd worden. Aangezien alle draaitabellen in deze werkmap dezelfde bron gebruiken (tblGem) worden al deze draaitabellen dan tegelijkertijd ververst.
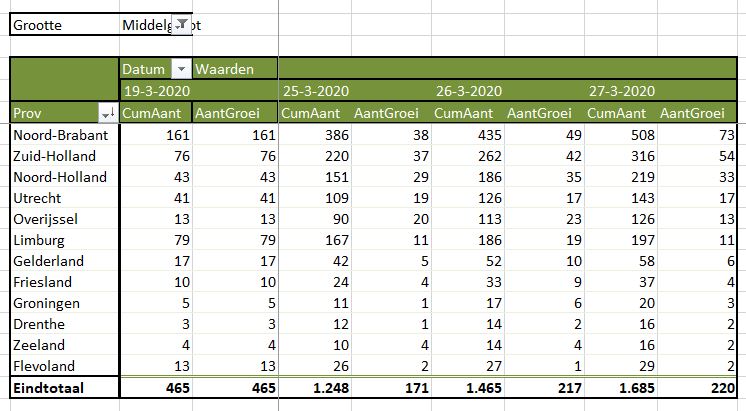
Overzicht per provincie (2)
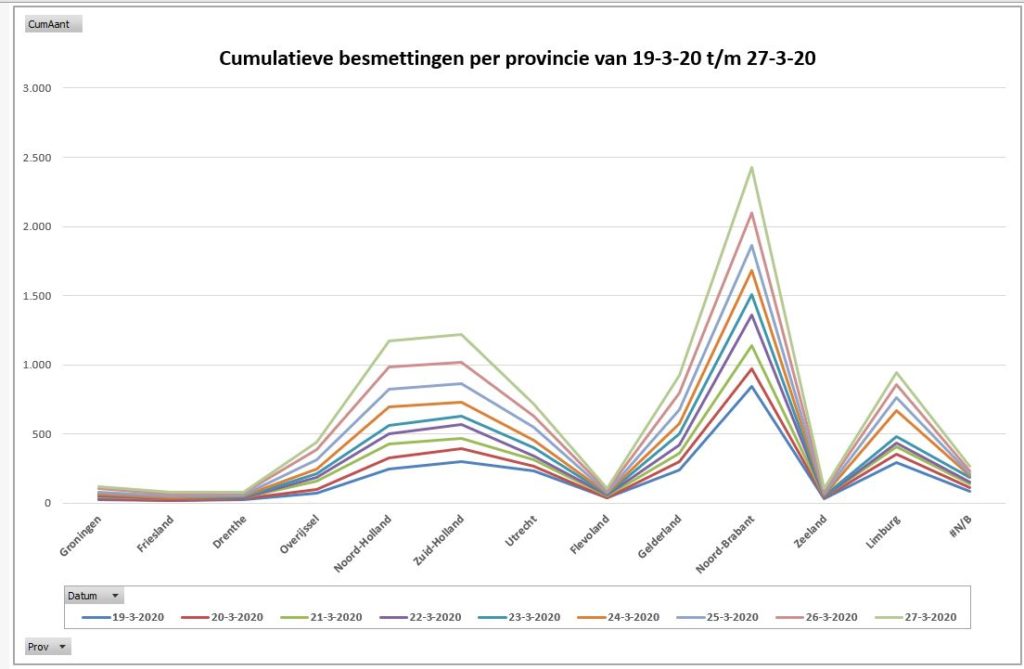
Wanneer we eenzelfde draaitabel sorteren van ‘hoog naar laag’ op de gegevens van de laatste dag (tabblad OvzProv2) dan ziet de bijbehorende draaigrafiek er als volgt uit (tabblad GrafProv2):
Noord- en Zuid-Holland gaan ongeveer gelijk op
Gelderland ‘haalt Limburg langzaamaan in’
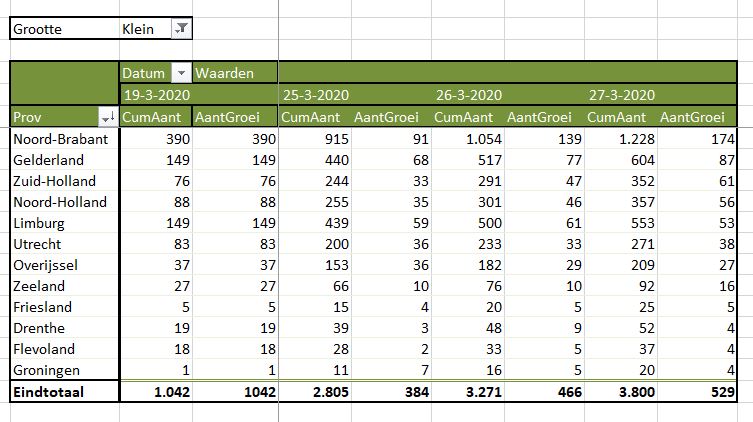
Overzicht per provincie (3)
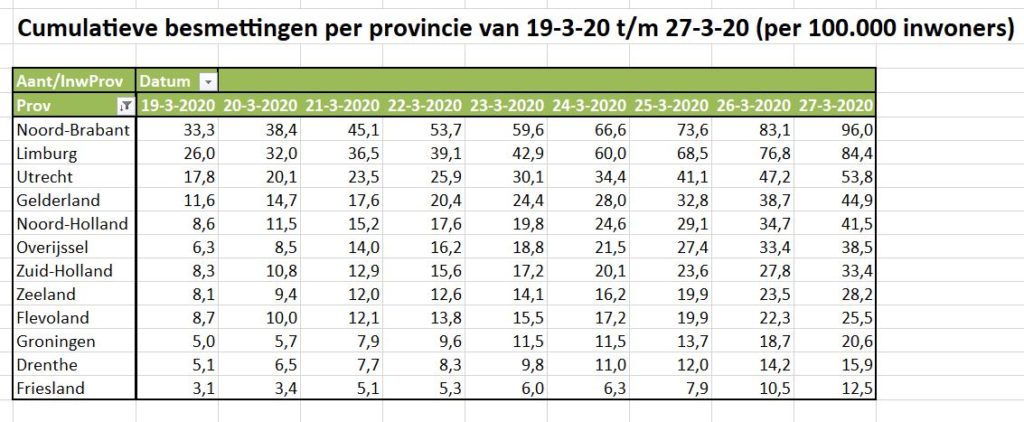
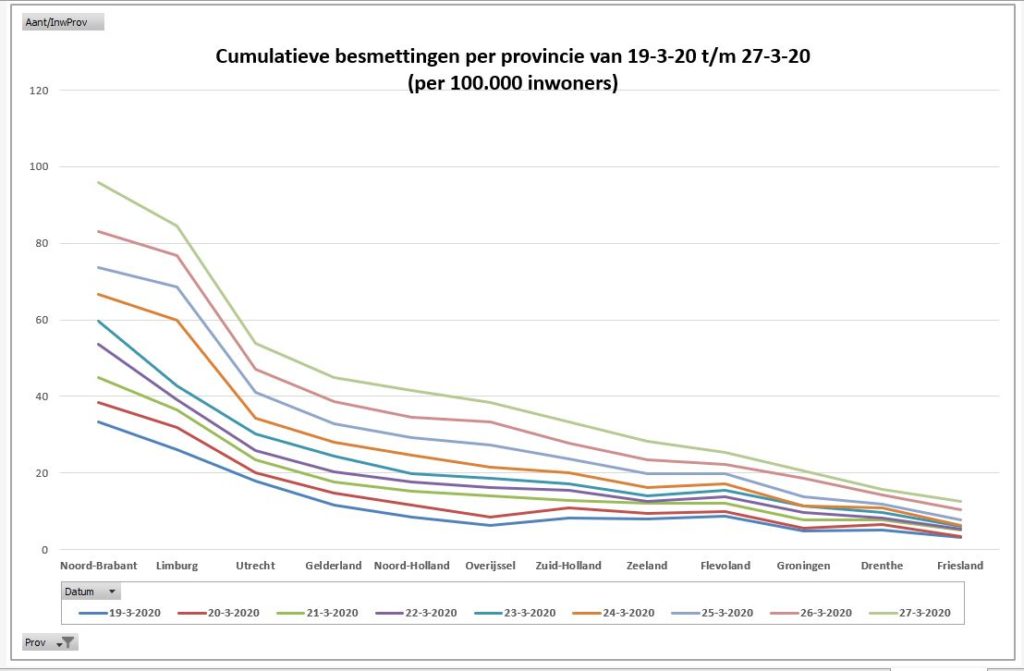
Maar als je provincies echt met elkaar wilt vergelijken moet je ook de verschillen in grootte daarbij betrekken. Op het tabblad OvzProv3 is daarom een draaitabel gemaakt van de genormaliseerde aantallen:
relatief zijn er dus in Brabant en Limburg de meeste besmettingen (toch gerelateerd aan Carnaval?)
we horen weinig over Utrecht, maar die komt in dit overzicht op de 3e plaats
Noord-Holland heeft relatief duidelijk meer besmettingen dan Zuid-Holland
de provincie Zeeland kende in het begin relatief evenveel besmettingen als Zuid-Holland; deze laatste vertoont echter in de loop van de tijd een grotere groei.
maar het virus moet ook in de ‘kleinere’ provincies niet onderschat worden
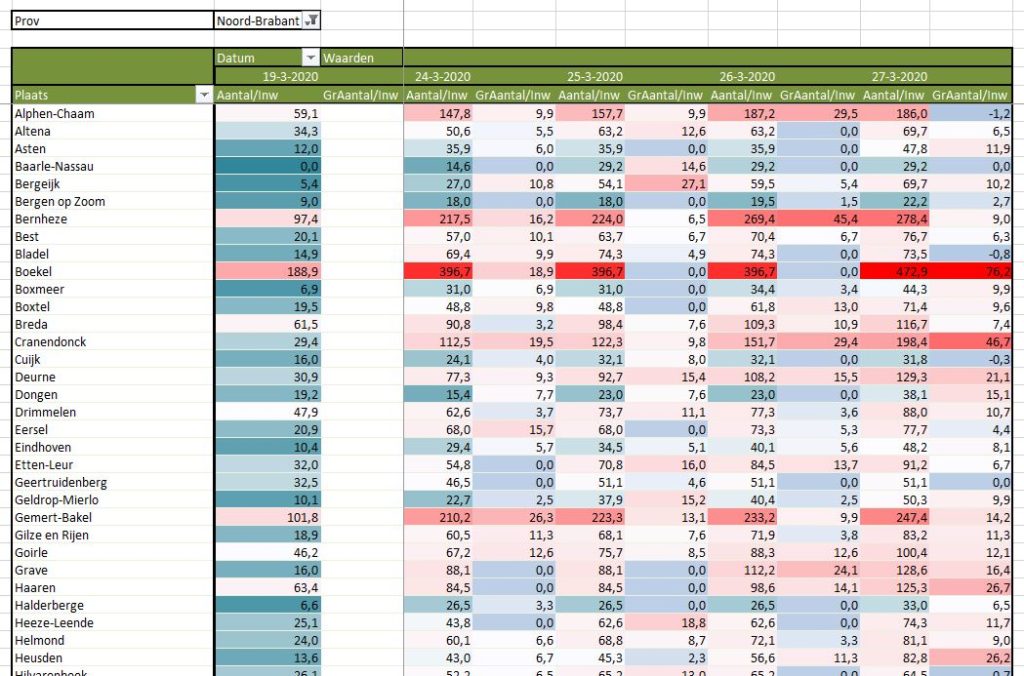
Overzicht per gemeente (1)
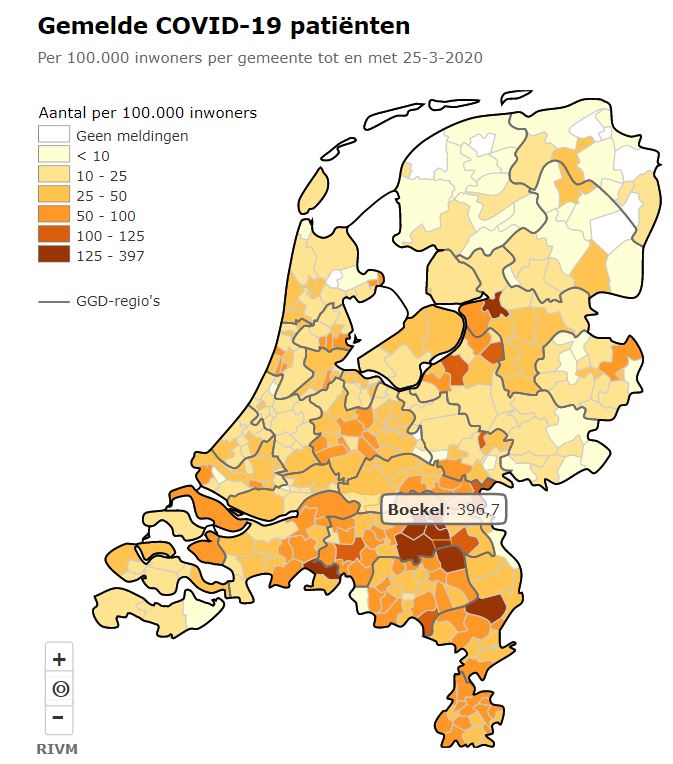
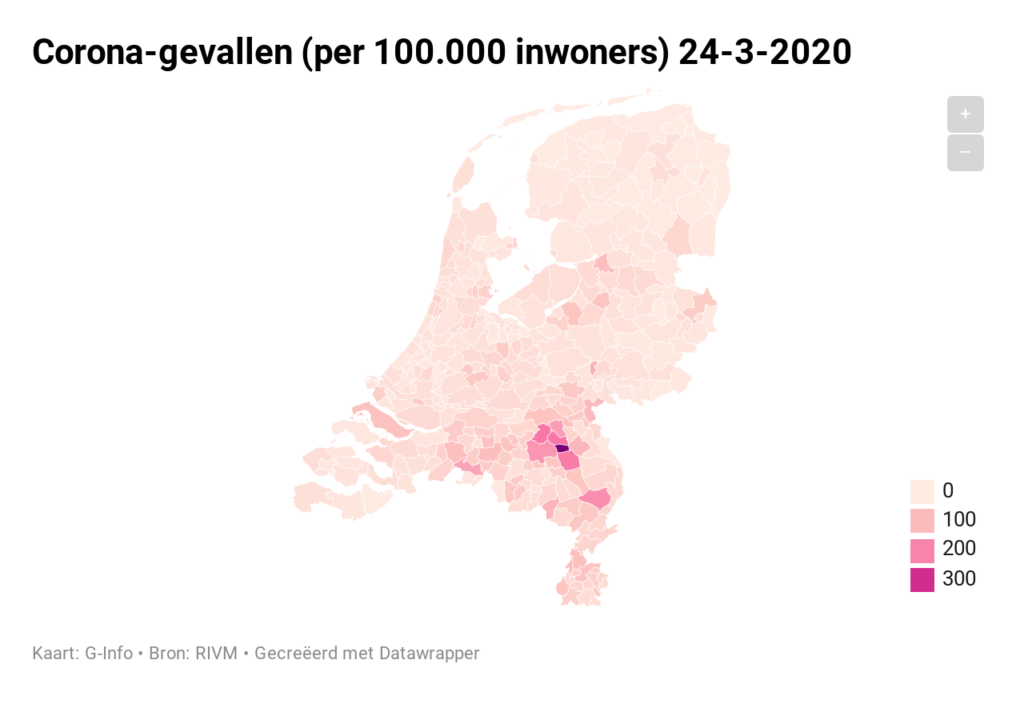
Voor diegene die nog wat ‘dieper willen kijken’ kunnen we op basis van de RIVM-cijfers op gemeenteniveau inzoomen. Het mooiste is natuurlijk om dit op een kaart zichtbaar te maken. De stand van 24 maart hebben we met behulp van Datawrapper.de ‘vertaald’:
Nieuwsgierig naar details? Klik op de afbeelding.
‘Uiteraard’ komen daarmee de grote plaatsen boven drijven. Dat is ook de reden, dat het RIVM vanaf het begin een genormaliseerde kaart heeft getoond. Dat hebben we voor 24 maart ook gedaan:
Klik op de afbeelding.
Op deze manier is beter te onderscheiden waar het virus zich vooral heeft verspreid. Naast de bekende plaatsen in Oost-Brabant zien we ook mogelijke haarden in Alphen-Chaam en Peel en Maas.
Aangezien bovenstaande methode nogal bewerkelijk is, zullen we voor een verdere detaillering gebruik maken van draaitabellen. Op het tabblad OvzGem1 van het Voorbeeldbestand ziet u per provincie de verdeling naar gemeente. Om goed zicht te krijgen op de groei per dag kunt u (handmatig) een sortering aanbrengen; in het voorbeeld is dit op de laatste kolom uitgevoerd.
Vooral in de plaatsen aan de oost-kant van Brabant is het aantal besmettingen weer fors toegenomen. Op 27 maart kent ook Boekel weer 9 nieuwe gevallen, terwijl de dagen daarvoor de groei nul was.
NB1 in het voorbeeld hierboven zijn enkele dagen niet zichtbaar; via Beeld/Blokkeren is in cel E7 een Titelblokkering geplaatst.
NB2 wilt u een andere provincie zien? Maak een keuze in cel C2.
Overzicht per gemeente (2)
Grote steden kennen in absolute zin al snel veel besmettingen. Het effect daarvan kunnen we bekijken op het tabblad OvzGem2 van het Voorbeeldbestand.
Overzicht per gemeente (3)
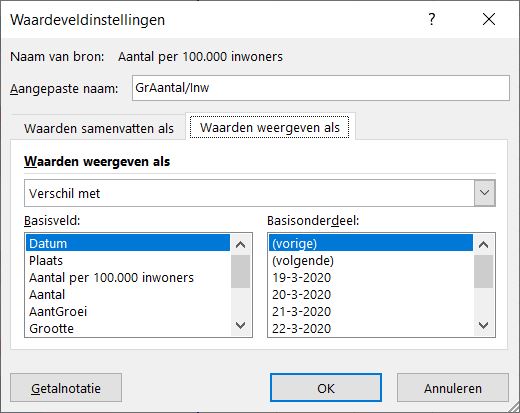
Maar pieken zijn duidelijker te zien wanneer we de genormaliseerde aantallen in een draaitabel zetten (zie tabblad OvzGem3 in het Voorbeeldbestand):
In deze draaitabel is 2 keer het veld Aantal per 100.000 inwoners geplaatst.
Door rechts te klikken op de 2e kolom kunnen de Waardeveldinstellingen aangepast worden. Zoals u hiernaast kunt zien, zal Excel het Verschilmet de VorigeDatum berekenen.
NB De kolomnamen zijn handmatig aangepast.
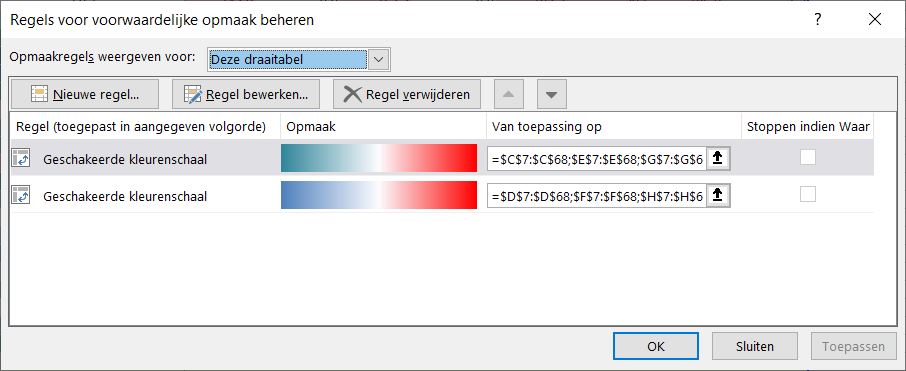
Voor allebei de waardevelden is een Voorwaardelijke opmaak ingesteld zodat uitschieters snel zichtbaar worden. Kijk in de menutab Start in het blok Stijlen bij Voorwaardelijke opmaak/Regels beheren.
LET OP wanneer er gegevens van een nieuwe datum bij zijn gekomen dan moet ook voor de nieuwe kolommen de Voorwaardelijke opmaak ingeregeld worden in de kolom Van toepassing op.
Zolang als Excel al bestaat, wordt het niet alleen als rekentool gebruikt maar ook voor rapportage-doeleinden. Waar in de beginperiode meestal door middel van cijfers werd gerapporteerd, zijn daar later ook grafieken bij gekomen.
Microsoft heeft ons in de afgelopen jaren met diverse soorten grafieken verblijd. In iedere nieuwe versie van Excel verschijnen er weer nieuwe; in dit artikel aandacht voor de Treemap en de waterval-grafiek.
NB in oudere versies van Excel en in menige MAC-versie werken de voorbeelden niet.
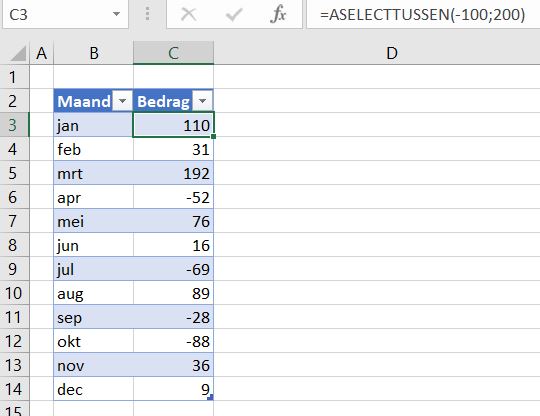
Basisgegevens
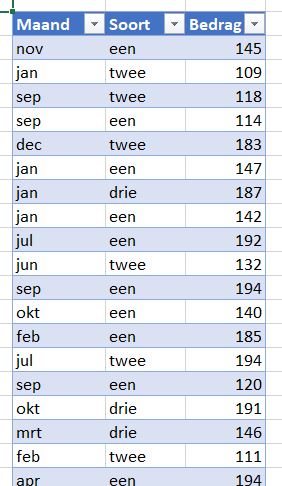
Om een grafiek te kunnen maken hebben we natuurlijk basisgegevens nodig. In het Voorbeeldbestand staat in het tabblad DataTree een overzicht van Bedragen uitgesplitst naar Maand en Soort.
NB door middel van de functie Aselecttussen worden de data door Excel willekeurig gekozen; bij iedere wijziging in de werkmap zullen dus nieuwe gegevens gegenereerd worden. Op deze manier kun je snel de impact op de grafieken zien.
De gegevens zijn opgeslagen in een Excel-tabel met de naam tblDataTree. Uitbreidingen aan deze tabel (of verwijderingen) zullen daardoor automatisch doorwerken in de overzichten en grafieken die daar op gebaseerd zijn.
Draaitabel en -grafiek
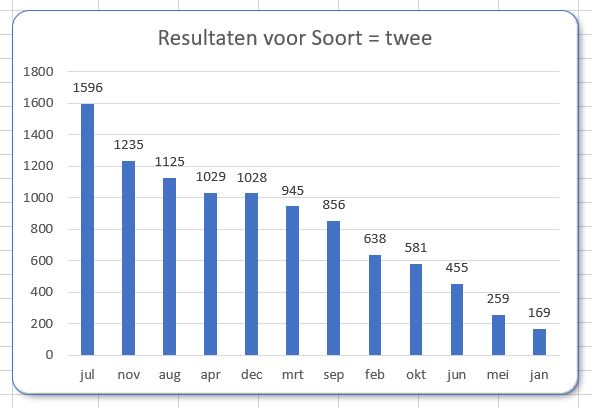
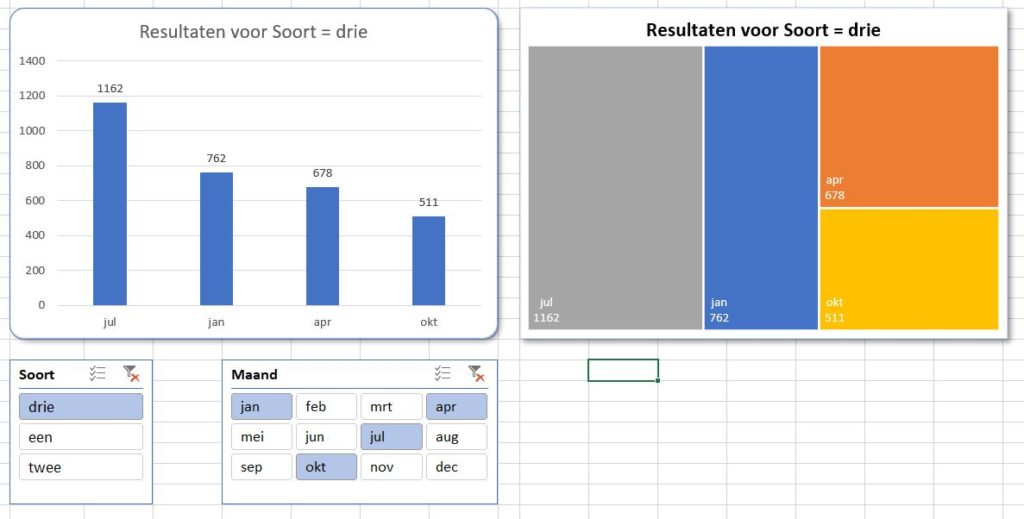
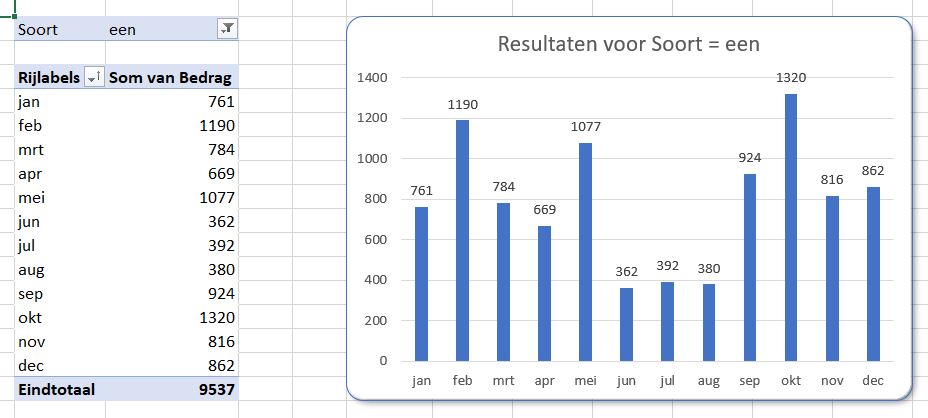
De gegevens uit het tabblad DataTree zijn in een draaitabel samengevat op het tabblad OvzTree. In dit geval is de Soort in het Filter-veld geplaatst, de Maand in de Rijen en het Bedrag in het Waarden-gebied. Deze draaitabel kan direct vertaald worden naar een grafiek:
klik ergens in de draaitabel
op dat moment komt er een nieuwe menu-tab bij, Hulpmiddelen voor Draaitabellen
klik daarbinnen op de menutab Analyseren en dan in het blok Extra op Draaigrafiek
na enkele cosmetische aanpassingen ontstaat bovenstaande grafiek
NB de grafiektitel is dynamisch: wanneer in het Filter een andere Soort wordt gekozen past de titel zich automatisch aan. In cel C19 wordt de basis daarvoor gelegd. U wijzigt een grafiektitel als volgt: klik in de bestaande titel, daarna in de formulebalk, voer het =-teken in, klik dan op cel C19 en druk op Enter. In de formulebalk verschijnt =OvzTree!$C$19.
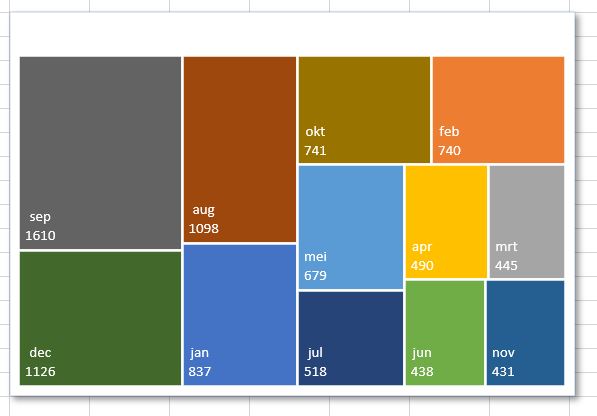
Niet altijd is in deze grafiek duidelijk welke maanden in welke mate bijdragen tot het totaal (klik rechts in de Draaitabel en kies Vernieuwen). Aangezien de basisgegevens telkens opnieuw worden gegenereerd zal de Draaitabel (en dus ook de Draaigrafiek) dienovereenkomstig worden bijgewerkt. Door de maanden anders te rangschikken kunnen de onderlinge verhoudingen duidelijker worden gemaakt:
klik op het keuzevinkje achter Rijlabels
kies Meersorteeropties
klik op het keuzerondje vóór Aflopend
kies dan daaronder als sorteervolgorde niet voor Maand maar voor Som van Bedrag
klik op OK
Bekijk het effect als je de draaitabel vernieuwd.
Treemap
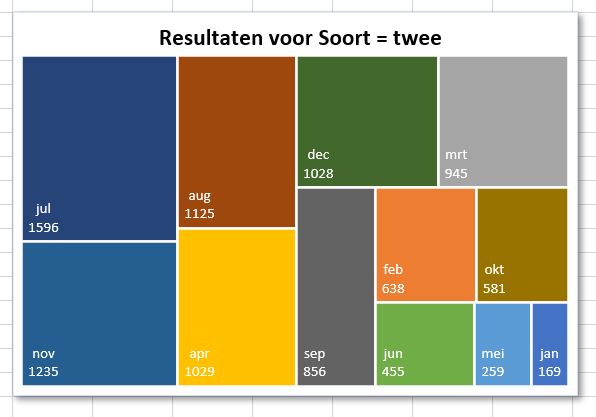
Maar niet iedereen vind het lezen/interpreteren van bovenstaande grafiek makkelijk. Waarschijnlijk zijn deze mensen meer gebaat bij een zogenaamde Treemap, bedoeld om hiërarchie in resultaten te verduidelijken.
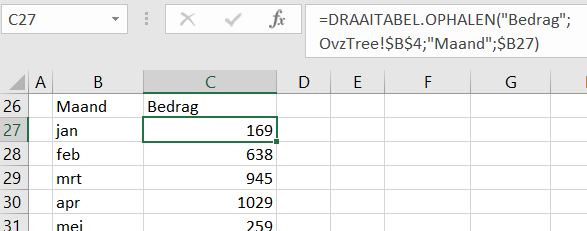
Helaas is de Treemap niet beschikbaar als de bron een draaitabel is. Daarom is in het tabblad OvzTree van het Voorbeeldbestand een hulptabel gecreëerd, die de gegevens van de draaitabel repliceert.
In cel C27 wordt, afhankelijk van de corresponderende waarde in kolom B, het Bedrag opgehaald in de draaitabel rond cel B4.
Het maken van een Treemap is dan een peuleschil:
klik op één van de cellen in het brongebied, bijvoorbeeld cel C27
kies in de menutab Invoegen in het blok Grafieken voor de optie Hiërarchiegrafiek
kies daar de optie Treemap
uiteraard zijn diverse eigenschappen, zoals legenda nog aanpasbaar
NB Blijkbaar komt dit grafiektype van een andere software-maker; niet alle eigenschappen van een grafiek zijn beschikbaar. De mooie ronde hoeken bijvoorbeeld zijn niet meer terug te vinden. Ook een dynamische grafiektitel is niet op dezelfde manier, als hiervoor aangegeven, in te voeren. In dit geval (zie het tabblad OvzTree van het Voorbeeldbestand) heb ik er voor gekozen om een Tekstblok in te voegen en daar dan de verwijzing naar cel C19 te plaatsen.
Om het instellen van keuzemogelijkheden te vereenvoudigen zijn ook 2 Slicers toegevoegd: eentje voor het instellen van de Soort en een andere om bepaalde Maanden te kunnen selecteren.
Waterval-grafiek
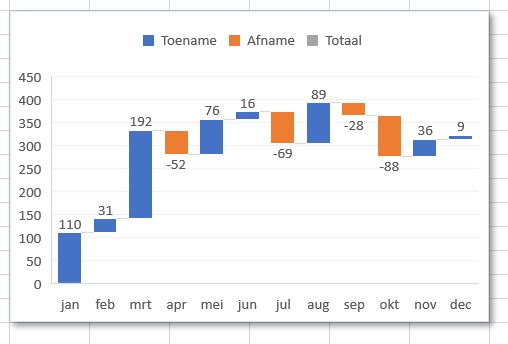
Is niet zozeer de onderlinge verhouding van belang, maar wil je weten hoe ieder onderdeel bijdraagt aan het geheel, dan is een ander type grafiek meer voor de hand liggend, de Waterval-grafiek.
NB Ook deze grafiek in niet beschikbaar als een draaitabel de brongegevens bevat.
In het tabblad Waterval van het Voorbeeldbestand is daarom een nieuwe bron-tabel (met de naam tblDataWater) ingevoerd. Per Maand wordt hier een willekeurig Bedrag gegenereerd tussen -100 en +200.
Ook het maken van een Watervalgrafiek is dan ‘kinderspel’:
klik op één van de cellen in het brongebied, bijvoorbeeld cel C3
kies in de menutab Invoegen in het blok Grafieken voor de optie Waterval-, trechter-, ….
kies daar de optie Waterval
uiteraard zijn diverse eigenschappen, zoals legenda nog aanpasbaar
NB ook voor dit type grafiek geldt het voorbehoud, dat niet alle (standaard-)instellingen beschikbaar zijn.












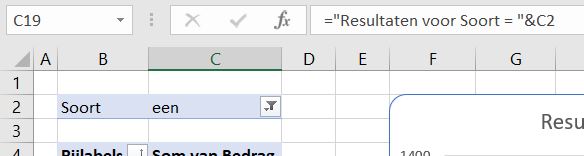 In cel C19 wordt de basis daarvoor gelegd. U wijzigt een grafiektitel als volgt: klik in de bestaande titel, daarna in de formulebalk, voer het =-teken in, klik dan op cel C19 en druk op Enter. In de formulebalk verschijnt =OvzTree!$C$19.
In cel C19 wordt de basis daarvoor gelegd. U wijzigt een grafiektitel als volgt: klik in de bestaande titel, daarna in de formulebalk, voer het =-teken in, klik dan op cel C19 en druk op Enter. In de formulebalk verschijnt =OvzTree!$C$19.