
Een niet-aaneengesloten bereik is een selectie van meerdere cellen waarbij ieder gedeelte uit één of meer cellen kan bestaan, maar waarbij die cellen niet allemaal op elkaar aansluiten.
Hieronder gaan we kijken hoe je dit soort bereiken kunt selecteren en wanneer je ze in formules wèl, maar zeker ook wanneer je ze niet kunt gebruiken. En uiteraard zoeken we ook oplossingen voor dat laatste.
Cellen selecteren
Een aaneengesloten gebied van cellen selecteren gaat het makkelijkst met behulp van het toetsenbord: gebruik de cursor-toetsen om de eerste cel te selecteren, hou Shift ingedrukt en gebruik dan weer de cursortoetsen om het hele gebied te selecteren.
Wanneer je een niet-aaneengesloten gebied wilt gebruiken dan zul je de muis ter hand moeten nemen:
- selecteer de eerste cel van het bereik door met de linker muisknop te klikken
- met de linkermuisknop ingedrukt kun je eventueel nog meer AANSLUITENDE cellen selecteren
- hou de Ctrl-toets ingedrukt en selecteer ergens anders één of meer aaneengesloten cellen
- herhaal punt 3 zoveel als nodig
Functies en niet-aaneengesloten bereiken
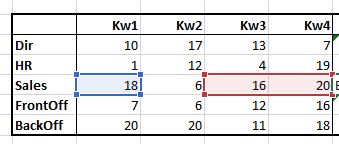
Op het tabblad SubTot van het Voorbeeldbestand vindt u een kwartaaloverzicht van enkele afdelingen.
In kolom G3 staat het jaartotaal van de afdeling Dir:
- tik in =som(
- klik met de linkermuisknop op cel C3
- ga, met de muisknop ingedrukt, naar cel F3
- druk op Enter
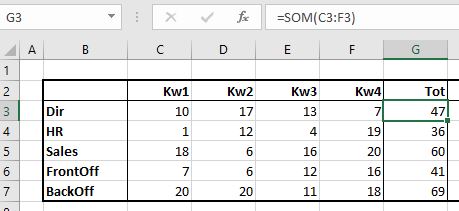
NB1 Excel vult automatisch het haakje-sluiten aan
NB2 tussen haakjes komt automatisch C3:F3, ofwel alle cellen van C3 tot en met F3
NB3 een snellere methode om van een naast-gelegen bereik de Som te bepalen: plaats de cursor in cel G3 en druk op de toetscombinatie Alt en =
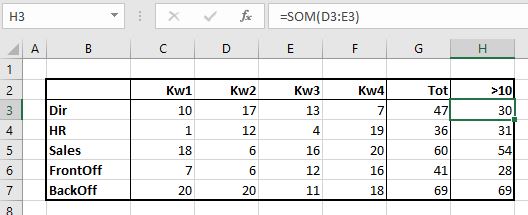
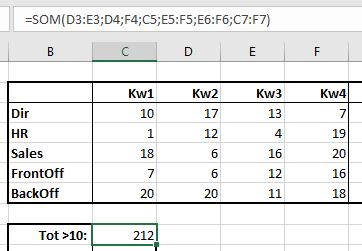
Maar wanneer we alleen de cellen opgeteld willen hebben waarvan de waardes groter dan 10 zijn dan wordt het lastiger:
- tik in cel H3 =som(
- klik met de linkermuisknop op cel D3
- ga, met de muisknop ingedrukt, naar cel E3
- druk op Enter
Nu voor cel H4:
- we beginnen weer met =som(
- klik op cel D4
- klik dan, met Ctrl ingedrukt, op cel F4
- druk op Enter
- het resultaat is: =SOM(D4;F4)
NB tussen haakjes staat nu een ; als scheidingsteken. Voor Excel betekent dit dat aan de functie 2 parameters worden meegegeven. In dit geval bestaat iedere parameter uit 1 cel.
Voor cel H5:
- start met =som(
- klik op cel C5
- klik dan, met Ctrl ingedrukt, op cel E5
- verschuif de cursor, nog steeds Ctrl ingedrukt, naar F5
- druk op Enter
- het resultaat is: =SOM(C5;E5:F5)
NB ook hier worden aan de Som-functie 2 parameters meegegeven; de eerste bestaat uit 1 cel, de tweede uit een bereik van meerdere cellen.
Op een vergelijkbare manier kun je ook het totaal van alle aantallen groter dan 10 bepalen (zie cel C9).
NB1 uiteraard is de berekening in cel C10 een stuk eenvoudiger: =SOM(H3:H7)
NB2 plaats de cursor achter de formule en je hebt een gekleurd controlemiddel om te zien of de juiste cellen zijn geselecteerd: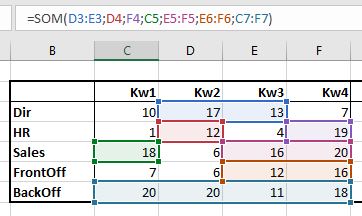
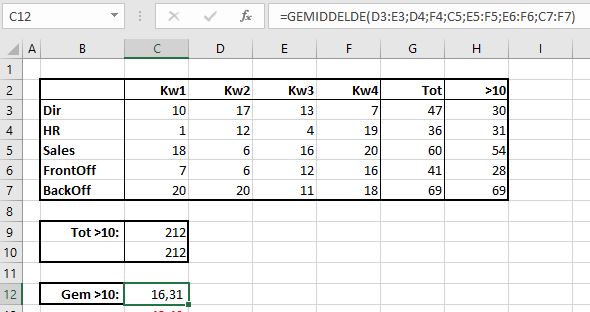
In cel C12 is te zien, dat ook de functie Gemiddelde met niet-aaneengesloten bereiken overweg kan.
LET OP: voor deze functie kun je NIET de kortere formule =GEMIDDELDE(H3:H7) gebruiken!
Maar …. bovenstaande formules werken alleen maar in een statische situatie. Wanneer de kwartaalcijfers nog kunnen wijzigen hebben we een probleem; dan moeten alle formules gecontroleerd en eventueel aangepast worden.
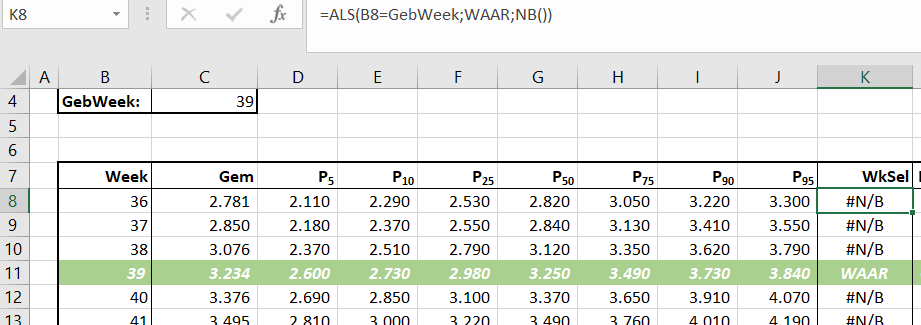
In het tabblad Aselect van het Voorbeeldbestand ziet u een formule waarbij wijzigingen in de brongegevens geen problemen meer opleveren:
=SOM.ALS(C3:F3;”>10″)
Ofwel: sommeer alle getallen in het bereik C3:F3 die groter dan 10 zijn.
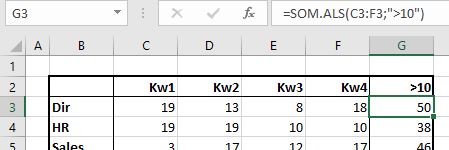
LET OP de voorwaarde waaraan de cellen moeten voldoen, moet tussen aanhalingstekens staan. Wel kan de voorwaarde in een cel worden opgenomen; dan blijven de aanhalingstekens achterwege; zie cel H3: =SOM.ALS(C3:F3;$G$2)
Het bepalen van de Som of Gemiddelde van alle waardes onder een voorwaarde is op deze manier ook een stuk eenvoudiger: =GEMIDDELDE.ALS(C3:F7;”>10″)
Bij voorgaande Als-formules was het bereik waar de voorwaarde op los gelaten moest worden aaneengesloten. Wanneer dat niet het geval is hebben we een probleem!
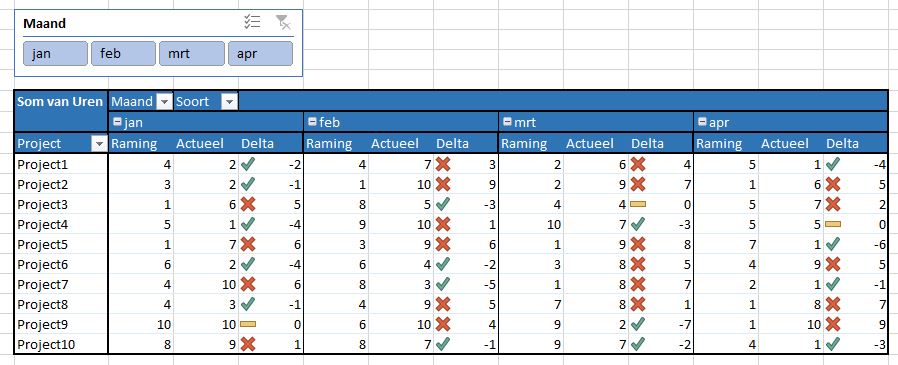
Probleem

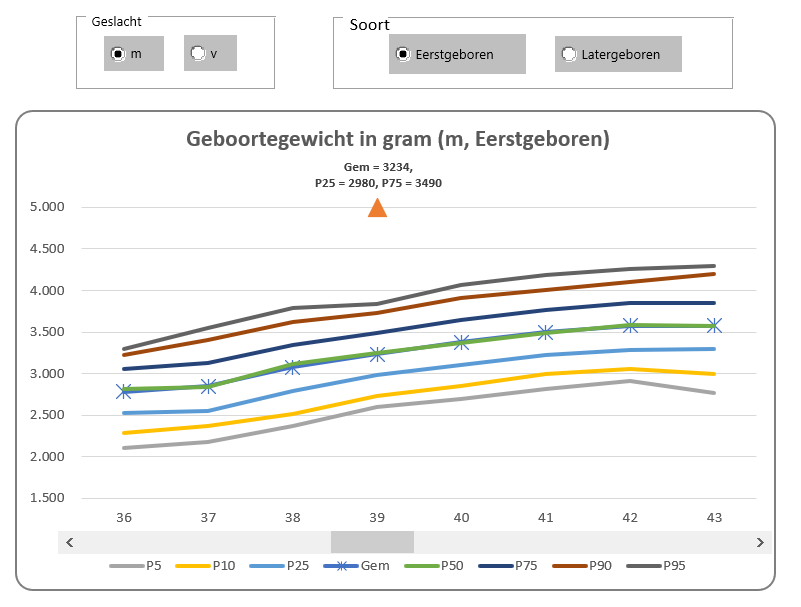
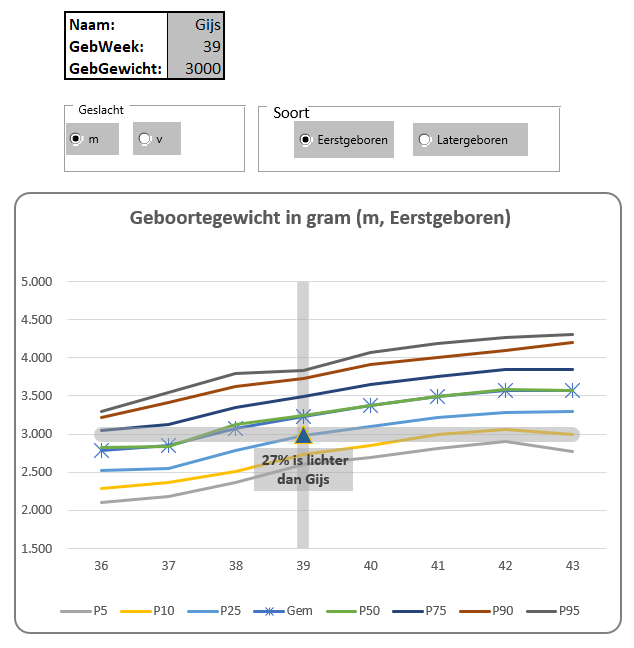
In het tabblad Probleem van het Voorbeeldbestand zien we een projectenoverzicht over de maanden. Per maand is er een Raming en een Actueel resultaat. Delta is het verschil tussen die twee (Actueel – Raming). Wanneer de Actuele stand kleiner is dan de Raming is dat gunstig (dus als Delta < 0 is).
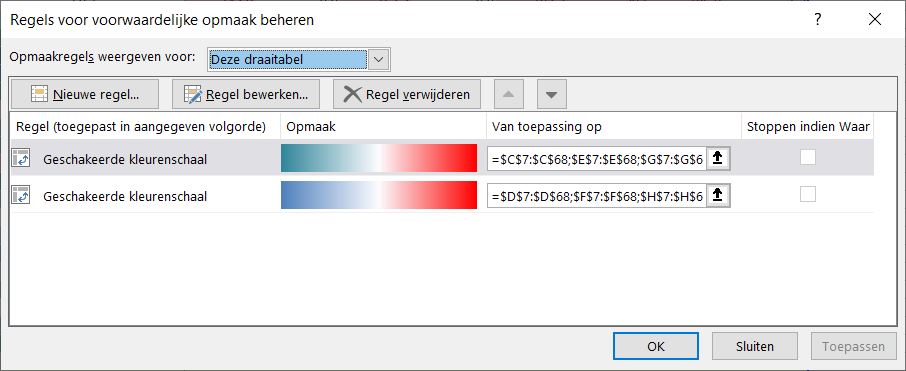
NB De Delta-kolommen hebben een voorwaardelijke opmaak gekregen.
Per project willen we het totaal van de negatieve Delta’s weten.
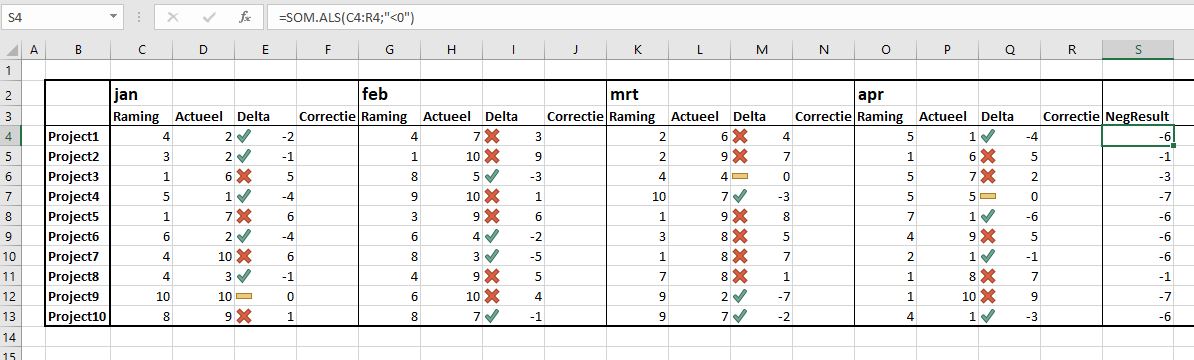
In cel S4 staat een formule, die dit probleem zou kunnen tackelen. De Raming en Actueel-kolommen zijn immers altijd positief (of 0): =SOM.ALS(C4:R4;”<0″)
Maar als we de Correctie-kolom gaan gebruiken en daar komen negatieve waardes voor, dan werkt de formule niet meer als verwacht/gehoopt.
We zouden dan iets willen gebruiken als =SOM.ALS( (E4;I4;M4;Q4) ;”<0″ )
Dus als eerste parameter geen aaneengesloten bereik, maar losse cellen.
Helaas! Excel raakt hier de weg kwijt. Deze functie is heel strikt: de eerste parameter moet een bereik zijn, de tweede moet de voorwaarde bevatten. En de tweede parameter begint achter de eerste punt-komma.
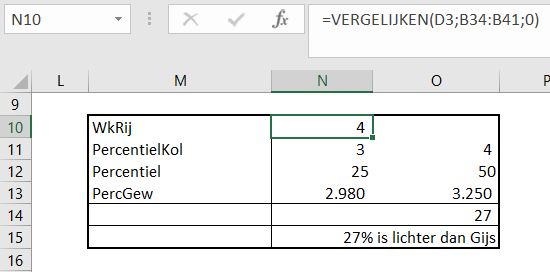
Gelukkig kunnen we dit probleem wel oplossen met de formule in T4:
=SOMMEN.ALS(C4:R4;C4:R4;”<0″;C$3:R$3;”Delta”)
Neem de Som van alle cellen uit C4:R4 (de eerste parameter), waarbij de cellen in C4:R4 (tweede parameter) kleiner zijn dan 0 en de cellen C3:R3 de waarde Delta bevatten.
LET OP bij de cellen C3:R3 is de rij-aanduiding absoluut gemaakt (zie $-tekens), zodat er bij het naar beneden kopiëren de formule naar de juiste rij blijft verwijzen.
Wat te doen, als de kopregel niet zo’n handige aanduiding van de betreffende kolommen heeft? Dan hebben we nog een ‘leuk’ alternatief (zie cel U4): 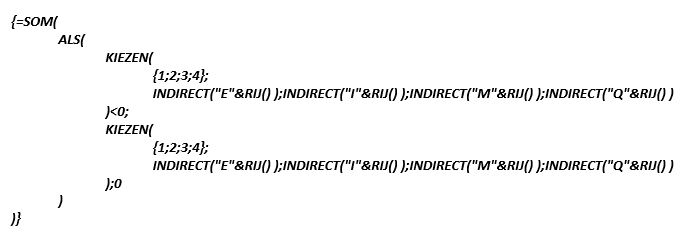
LET OP dit is een zogenaamde CSE-, array– of matrix-formule; deze wordt niet afgesloten door op Enter te drukken maar tegelijkertijd Ctrl-Shift-Enter. Excel plaats dan automatisch de accolades rond de formule.
Korte uitleg: door de CSE-methode ‘dwingen’ we Excel om (in dit geval) 4 keer de Als-functie uit te voeren; telkens met een andere kolom door middel van de Kiezen-functie.
Functies en niet-aaneengesloten bereiken (conclusie)
Wanneer kun je niet-aaneengesloten bereiken gebruiken binnen een functie?
Kort door de bocht: alleen bij de simpele rekenkundige functies als Som, Aantal, Gemiddelde etcetera.
Bij het invoeren van dit soort functies zie je dat je meer dan 1 dezelfde soort parameter kunt opgeven.
NB de rechte haken geven aan dat de tweede parameter optioneel (niet verplicht) is. De … geven aan, dat er nog meer parameters opgegeven kunnen worden.
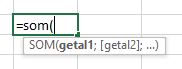

Bij andere functies zie je dat de verschillende parameters ieder een ‘andere’ rol vervullen. Logisch dat je dan niet een willekeurig aantal bereiken als 1 parameter kunt opgeven.
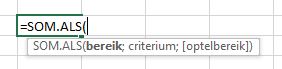
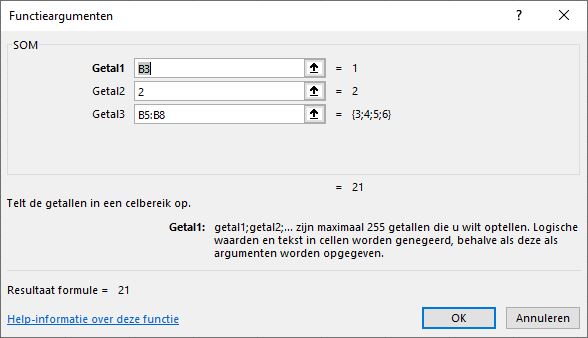
Vreemd eigenlijk: als je naar het scherm met Functieargumenten van Som kijkt (gebruik de button ![]() naast de formulebalk), dan zie je als toelichting dat je getallen als parameter kunt opgeven. Nergens een woord over bereiken!
naast de formulebalk), dan zie je als toelichting dat je getallen als parameter kunt opgeven. Nergens een woord over bereiken!
Waarschijnlijk toch de meest gebruikte optie van Excel.
Toetje
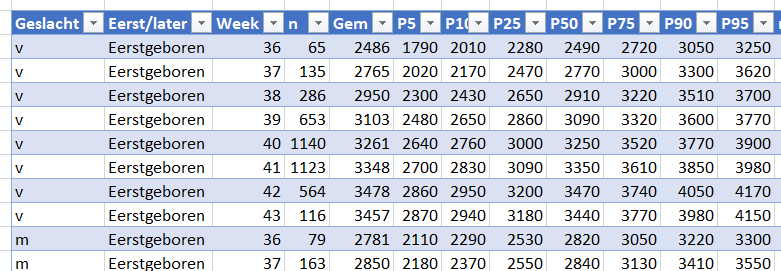
Voor de liefhebbers bevat het Voorbeeldbestand nog enkele sheets waarmee de opzet van de ‘Probleem’-sheet op een geheel andere wijze wordt aangepakt; de basisgegevens worden in een database-vorm ingevoerd. Het resultaat-overzicht wordt daardoor een stuk flexibeler.


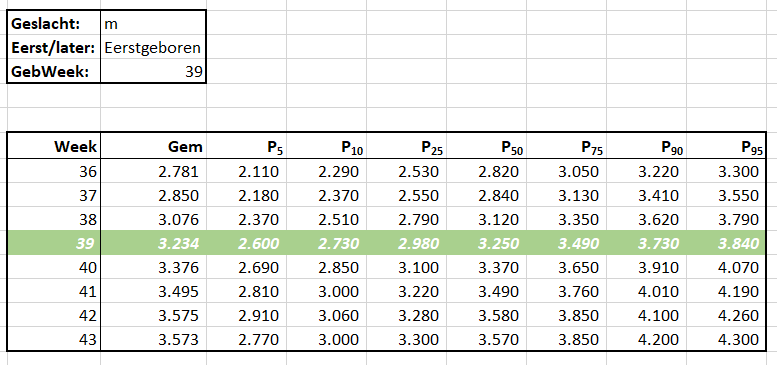
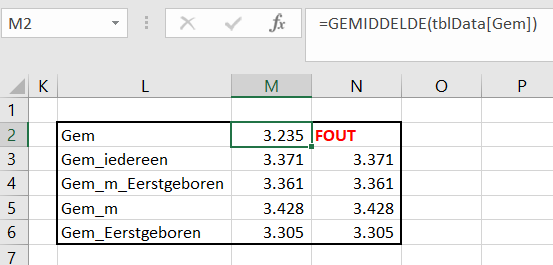
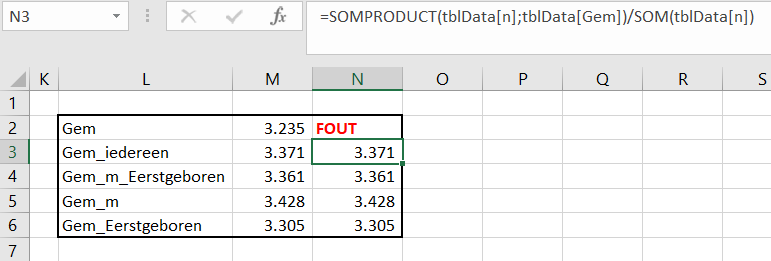
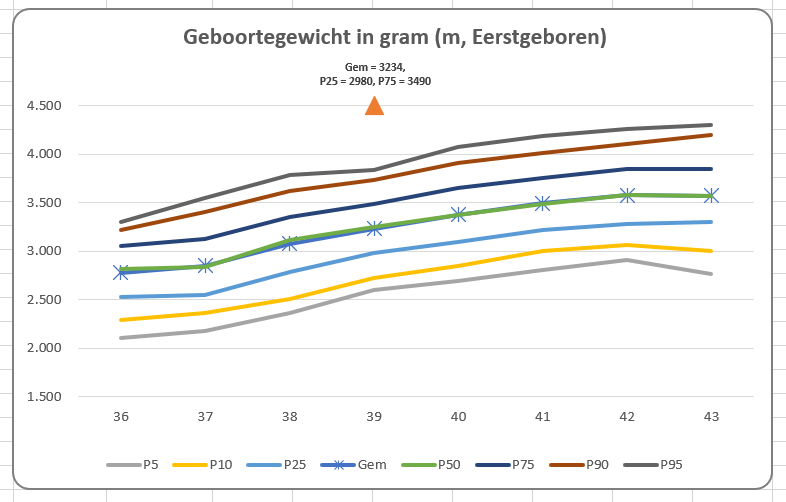


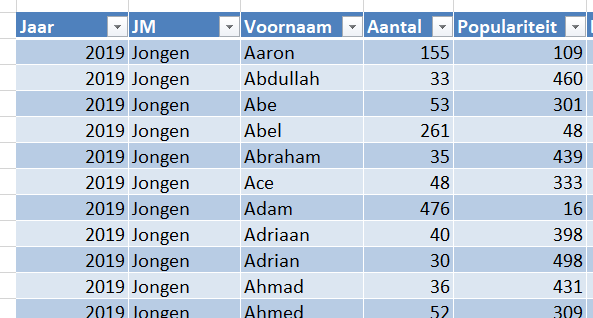
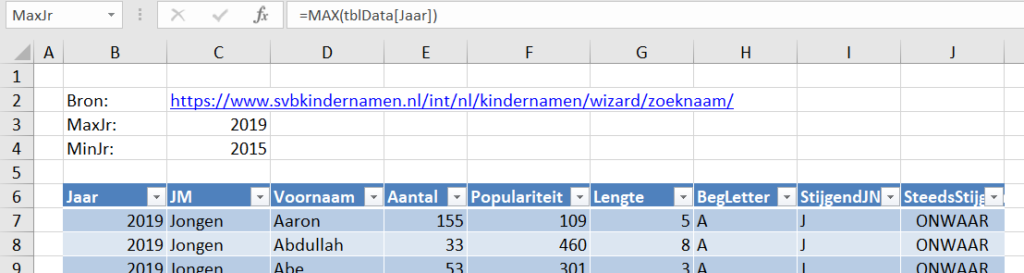
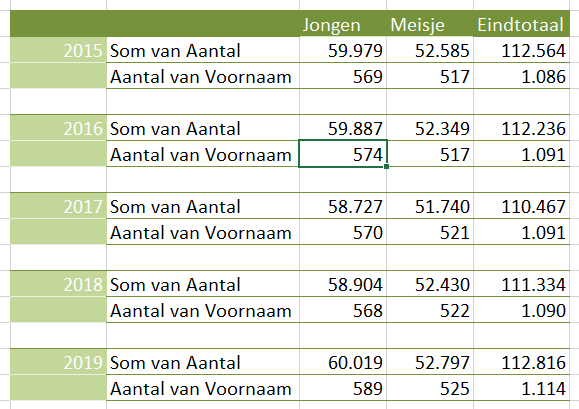
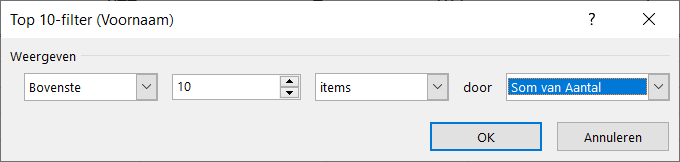
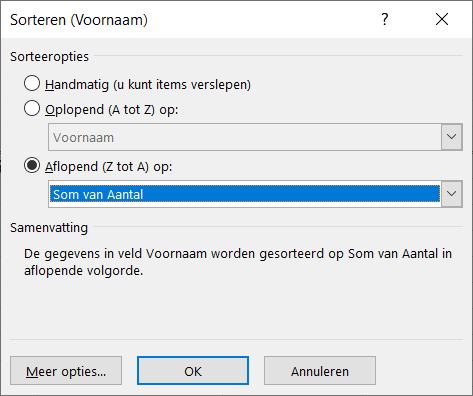
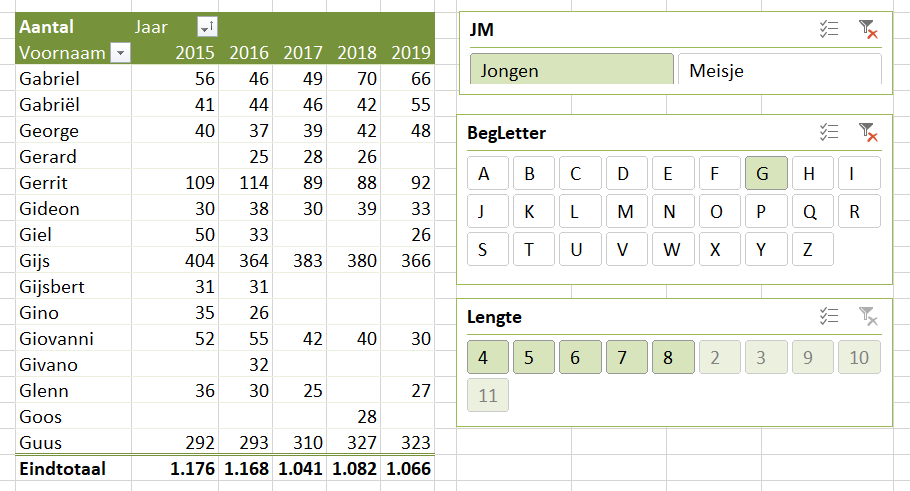
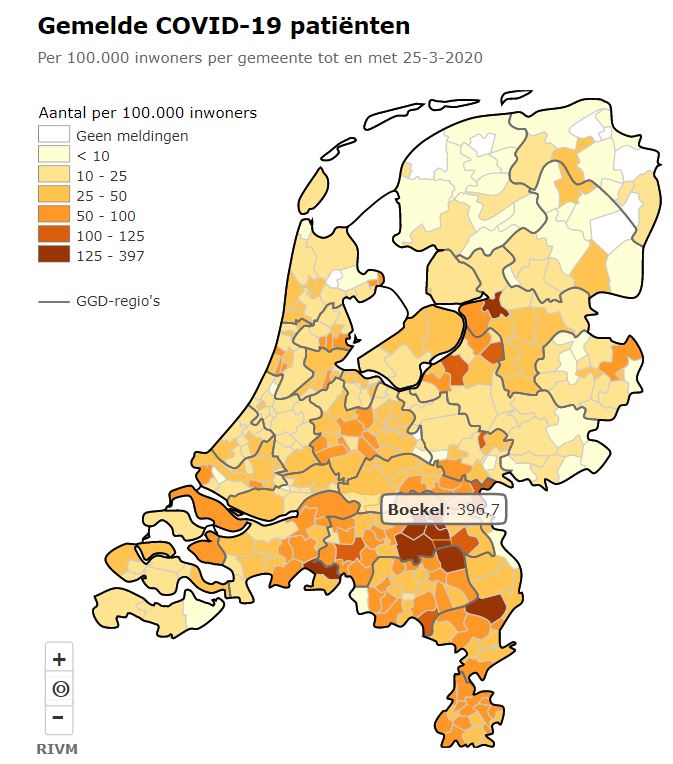

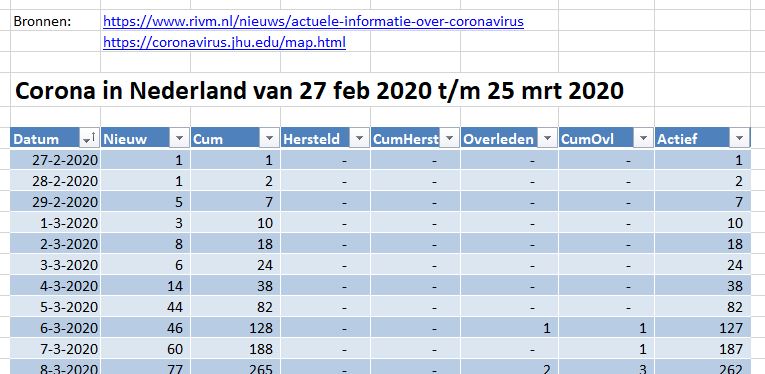

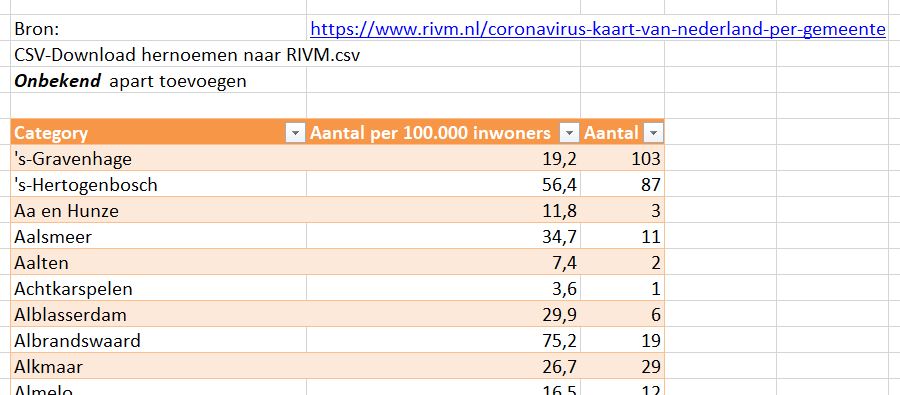
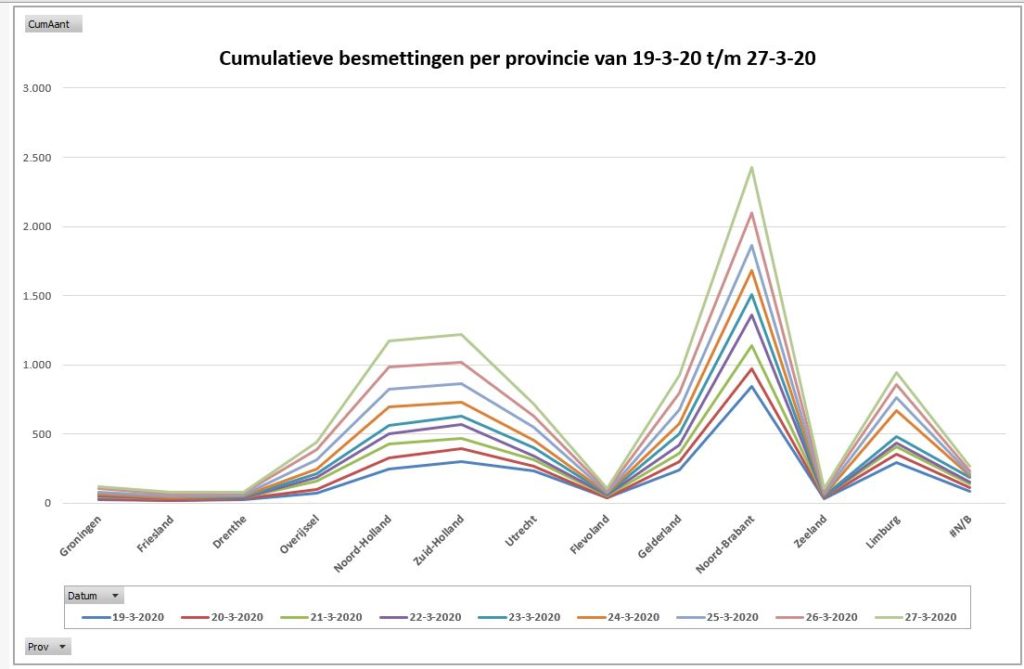
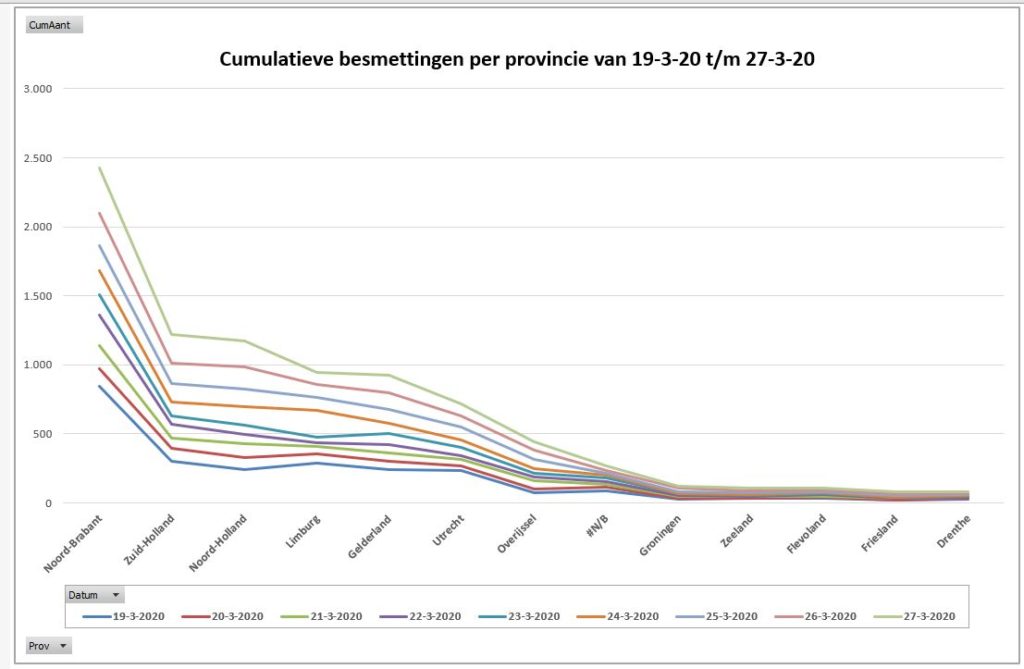
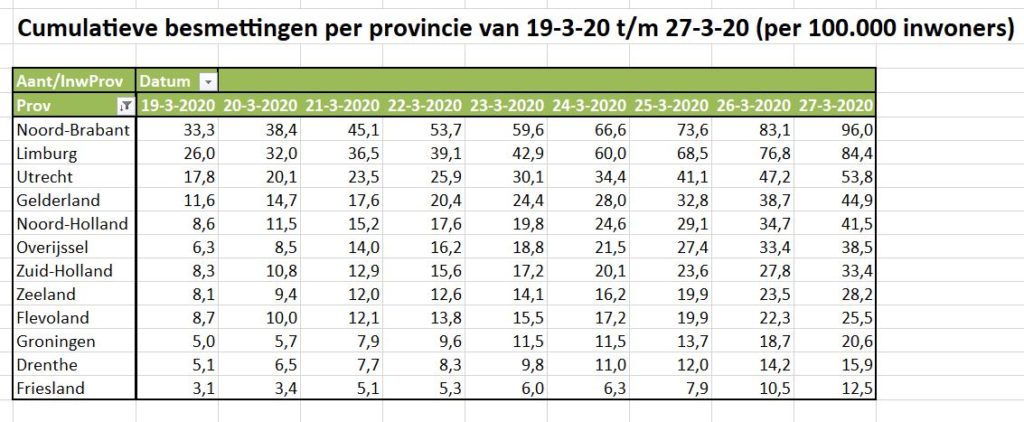
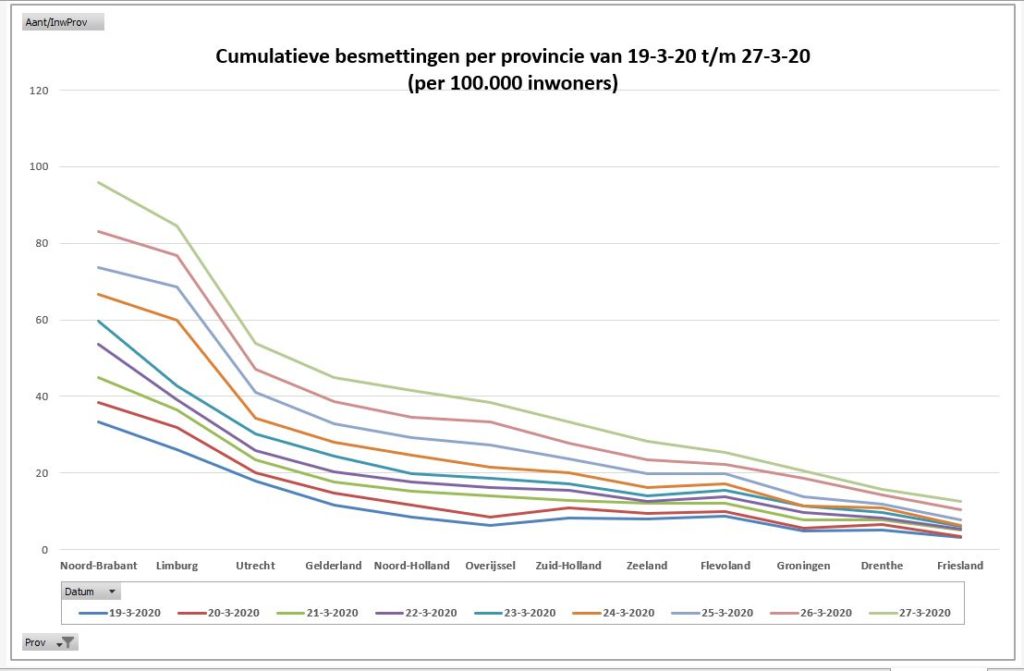

 Er bestaan nogal wat situaties, waarbij je wilt weten of items allemaal verschillend zijn of niet.
Er bestaan nogal wat situaties, waarbij je wilt weten of items allemaal verschillend zijn of niet.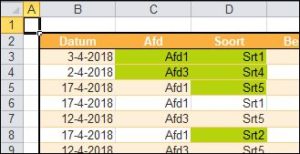 In het
In het 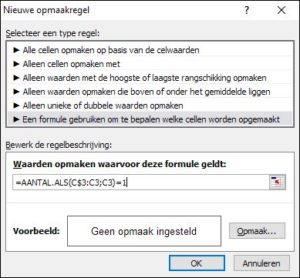 selecteer cel C3
selecteer cel C3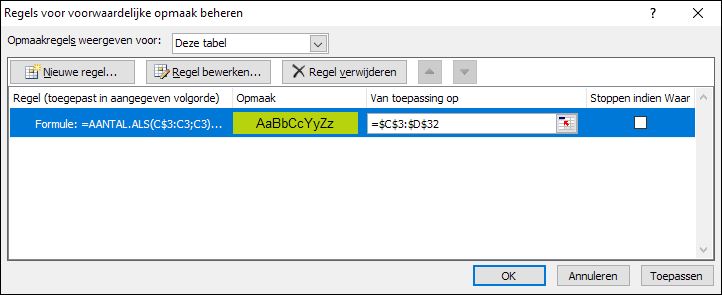
 NB1 het overzicht is een Excel-tabel. Daarom zal Excel, wanneer er een regel aan wordt toegevoegd, ook de Voorwaardelijke opmaak direct meenemen; het bereik wordt automatisch aangepast.
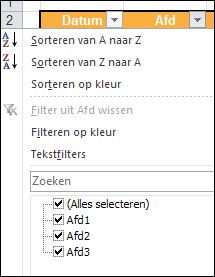
NB1 het overzicht is een Excel-tabel. Daarom zal Excel, wanneer er een regel aan wordt toegevoegd, ook de Voorwaardelijke opmaak direct meenemen; het bereik wordt automatisch aangepast.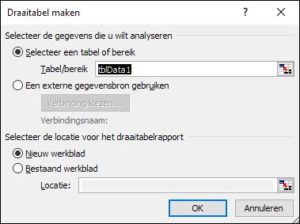 selecteer een cel in de tabel met gegevens, bijvoorbeeld B2
selecteer een cel in de tabel met gegevens, bijvoorbeeld B2
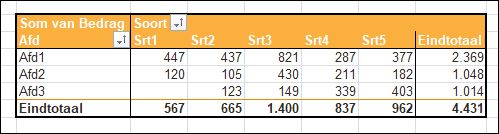
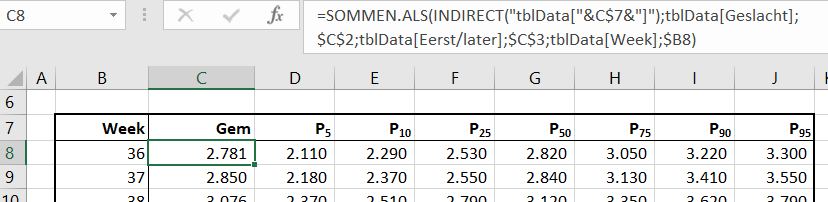
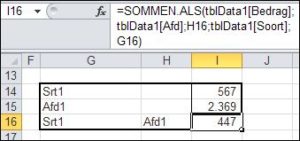 U moet dan de functie SOMMEN.ALS gebruiken.
U moet dan de functie SOMMEN.ALS gebruiken.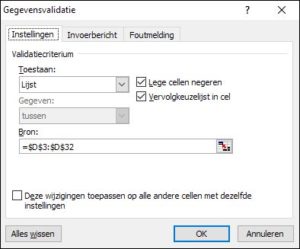 kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Gegevensvalidatie
kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Gegevensvalidatie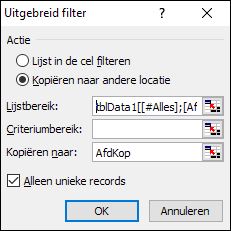 in het Uitgebreid filter kiezen we als Actie de optie Kopiëren naar andere locatie
in het Uitgebreid filter kiezen we als Actie de optie Kopiëren naar andere locatie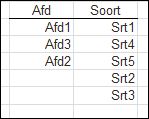 In het tabblad Data1 van het
In het tabblad Data1 van het 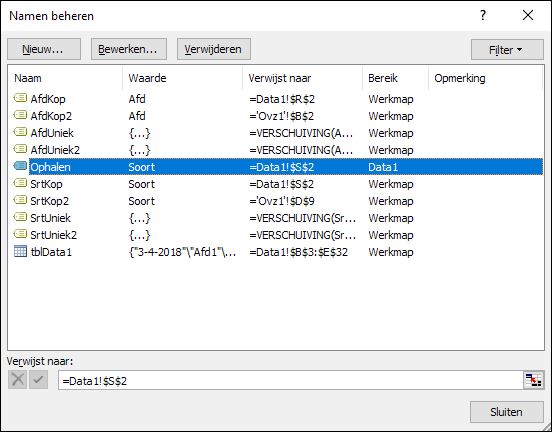 NB2 als er regels aan de bron-tabel worden toegevoegd dan moeten de ophaal-acties opnieuw worden uitgevoerd.
NB2 als er regels aan de bron-tabel worden toegevoegd dan moeten de ophaal-acties opnieuw worden uitgevoerd.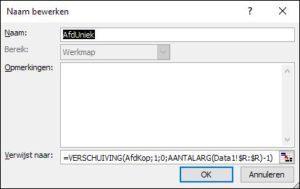 kies in de menutab Formules in het blok Gedefinieerde namen de optie Naam definiëren
kies in de menutab Formules in het blok Gedefinieerde namen de optie Naam definiëren