Voorbeeldbestand: RapportageStramien.xlsx
Voorbeeldbestand: RapportageStramien.xlsx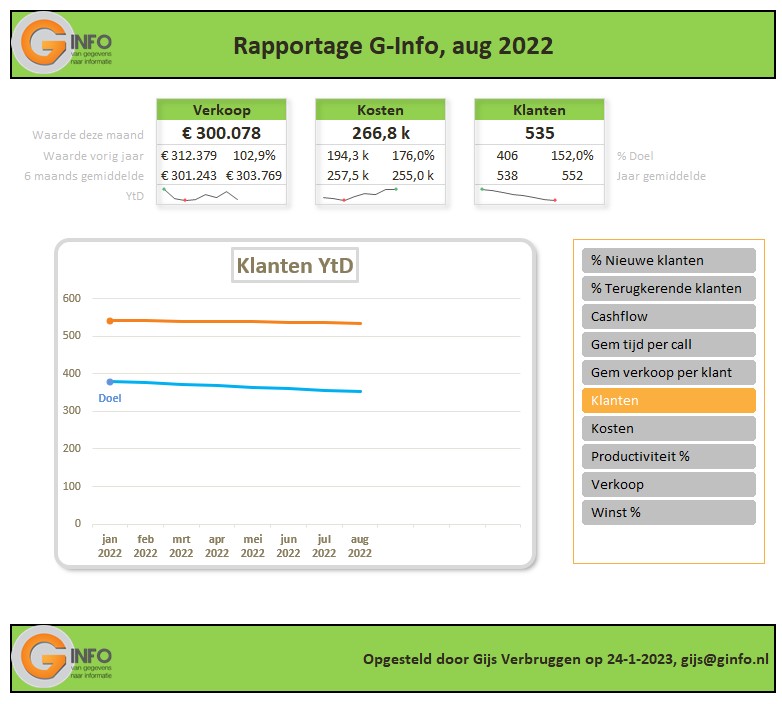
Binnen ieder bedrijf is het van belang om zoveel mogelijk processen te standaardiseren en vaak ook te automatiseren.
Ook wanneer we Excel als hulpmiddel bij ons werk gebruiken is het belangrijk om zoveel mogelijk handmatige handelingen, die regelmatig terugkomen, te vermijden. Power Query, draaitabellen, en VBA kunnen daarbij een grote rol spelen.
Voor diegene, die vaak verschillende rapportages moeten maken, is een andere invalshoek belangrijk. Ga niet voor iedere nieuwe rapportage weer opnieuw het wiel uitvinden, maar gebruik een flexibel stramien. Hoe dat in zijn werk gaat zullen we in dit artikel aan de hand van een direct inzetbaar Voorbeeldbestand laten zien.
Bedrijf
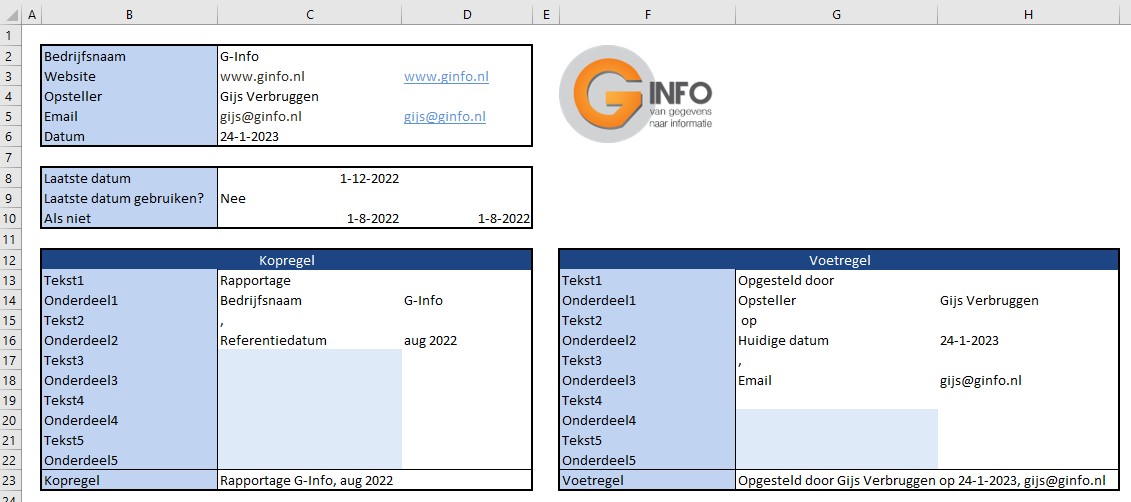
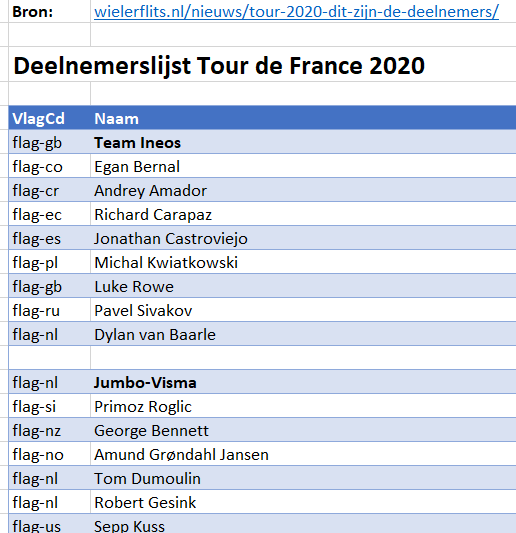
Het eerste tabblad van het Voorbeeldbestand, Bedrijf, bevat diverse bedrijfsspecifieke gegevens, inclusief een logo.
NB1 wanneer je dit logo vervangt (door er rechts op te klikken) zorg dan dat het nieuwe plaatje een transparante achtergrond heeft.
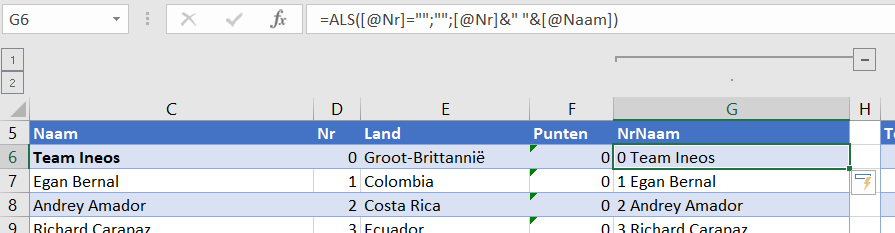
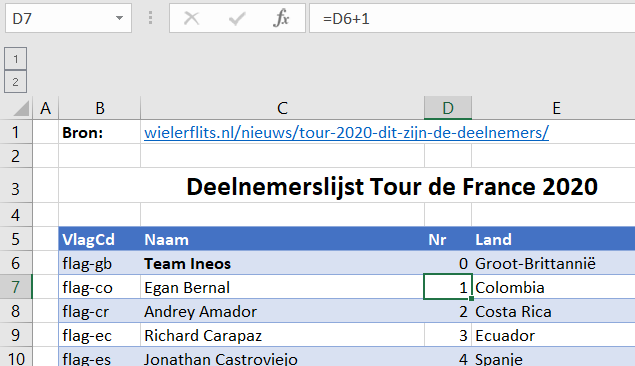
NB2 diverse cellen in dit tabblad (en ook op andere plaatsen in de werkmap) hebben een naam gekregen, die in de rest van het rapportage-stramien gebruikt worden. Cel C2 bijvoorbeeld heeft de naam BedrNaam.
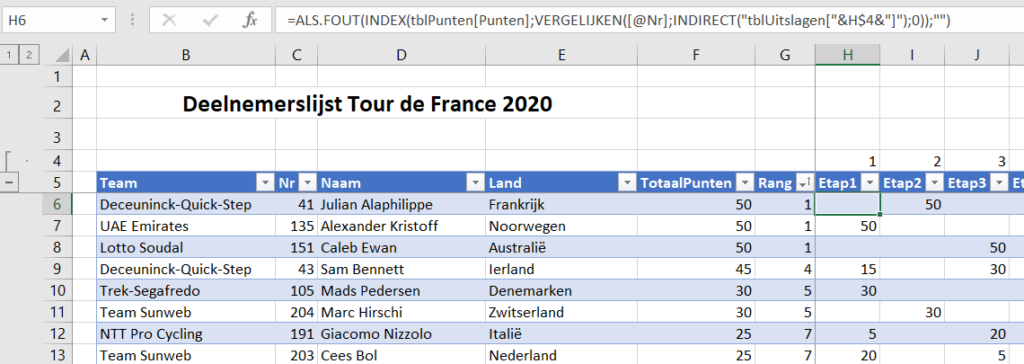
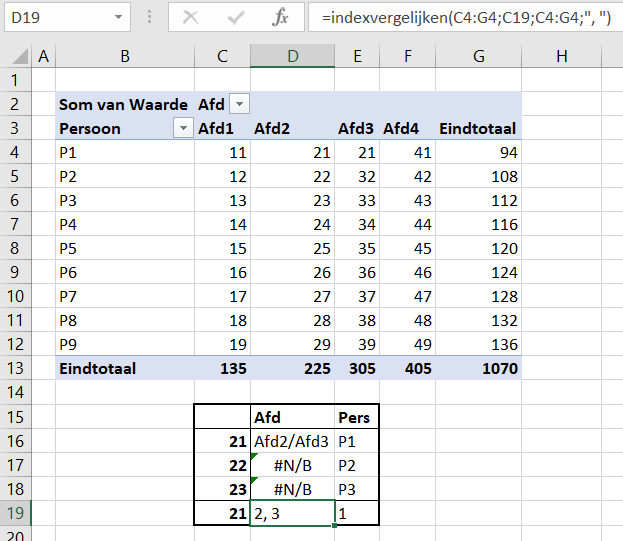
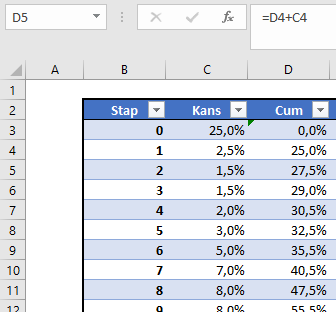
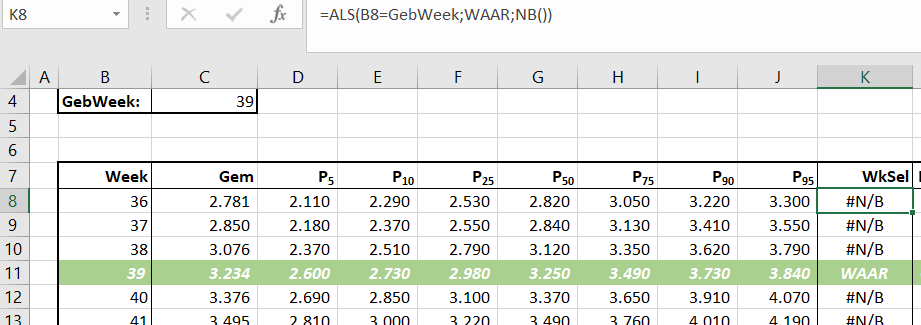
In cel C8 wordt de meest recente datum uit het Data-bestand (zie hierna) opgehaald met behulp van de functie MAX. De inhoud van cel C9 bepaalt of deze datum als referentie dient voor de rapportage of een andere (cel C10).
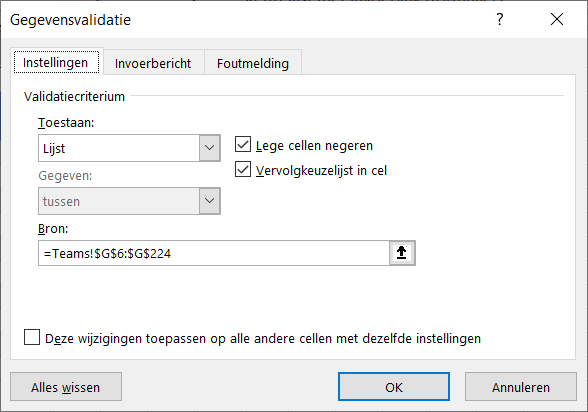
NB3 op diverse plaatsen in dit stramien zul je zien dat de invoer in cellen beperkt is met behulp van Gegevensvalidatie; zie bijvoorbeeld de cel C9 (alleen Ja en Nee zijn toegestaan).
In de regels 13 tot en met 22 kun je zelf de diverse onderdelen (en teksten) kiezen die in de kop- en voetregel van een rapportage moeten komen.
NB4 in cel G19 staat een spatie om er voor te zorgen dat de voetregel aan de rechterkant niet tegen de rand aan komt.
Experimenteer met de mogelijkheden en beoordeel het effect op de rapportages in de tabbladen Ovz1 en Ovz2.
Basis-instellingen
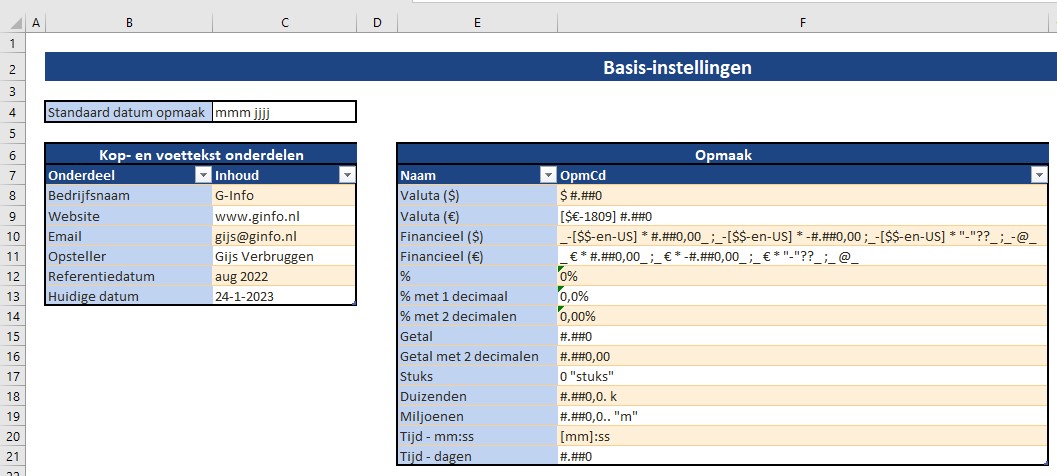
Daaronder staan 6 items die als onderdeel voor de kop- en voetregels kunnen dienen.
In het blok in de kolommen E en F staan diverse opmaak-omschrijvingen en -codes die bij het weergeven van gegevens in de rapportage gebruikt kunnen worden.
NB aangezien alle keuze-items in Excel-tabellen zijn opgenomen zal een gewenste uitbreiding van de opties direct overal in de werkmap geëffectueerd worden.
Overige instellingen
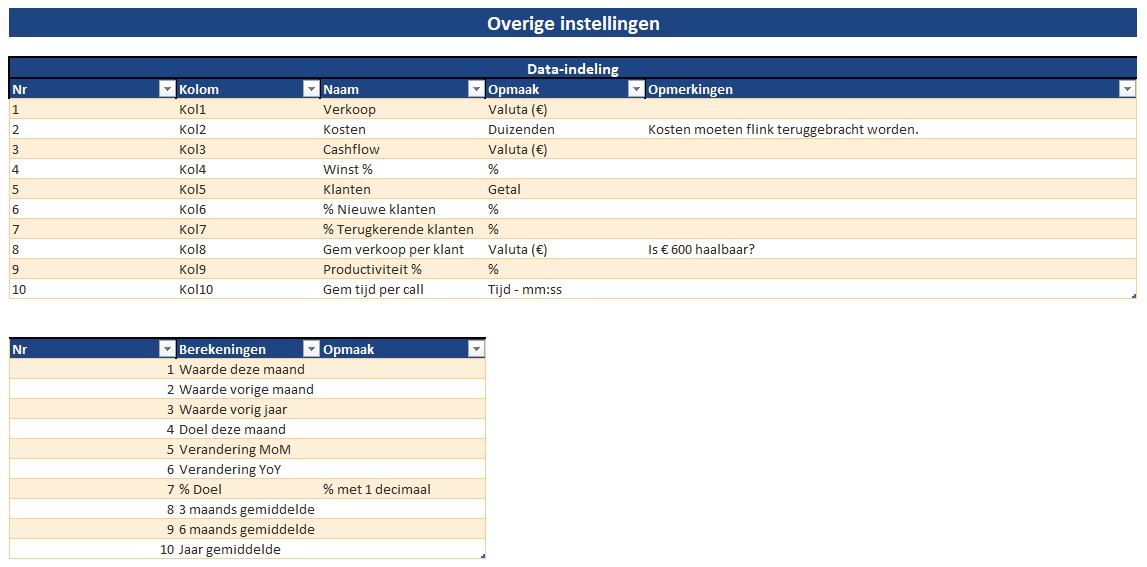
Voor uw eigen rapportage moeten/kunnen de kolommen Naam, Opmaak en Opmerkingen aangepast worden.
Daaronder staat een Excel-tabel met daarin de omschrijvingen van de berekeningen die op de gegevens kunnen worden toegepast. De berekeningen zelf staan op het tabblad Berekeningen. Ook hier zult u voor uw eigen rapportage aanpassingen moeten doorvoeren en wel in de tweede en derde kolom.
NB in het voorbeeld-stramien staan 10 berekeningen, maar dit mogen er ook meer (of minder) zijn.
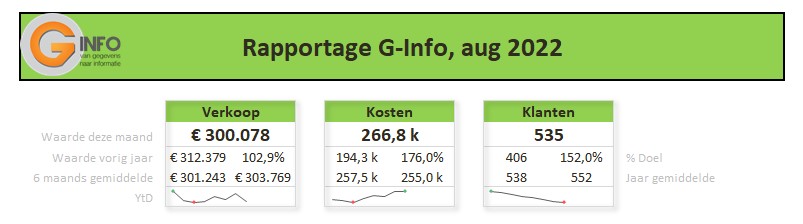
LET OP de opmaak van berekende items is standaard gelijk aan de opmaak van de onderliggende data; in het voorbeeld hierboven zal de opmaak van Waarde deze maand in het geval van Verkoop-cijfers gelijk zijn aan Valuta, maar die van Klanten heeft dus de opmaak Getal.
Maar bij berekening 7 (in dit geval) geven we aan dat alle items hiervan de opmaak % met 1 decimaal zullen hebben.
Als laatste geven we nog aan wat voor een soort rapportage het hier betreft.
Er zijn 2 mogelijkheden: alleen de data van het lopende jaar worden getoond (YtD = Year to Date) of altijd de laatste 12 maanden (YoY = Year on Year).
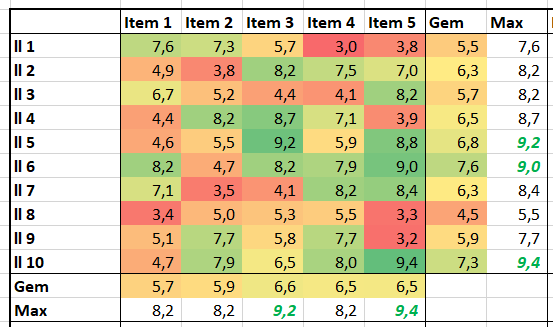
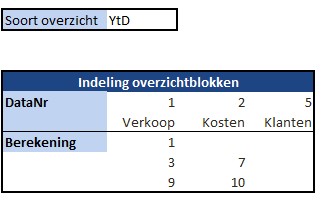
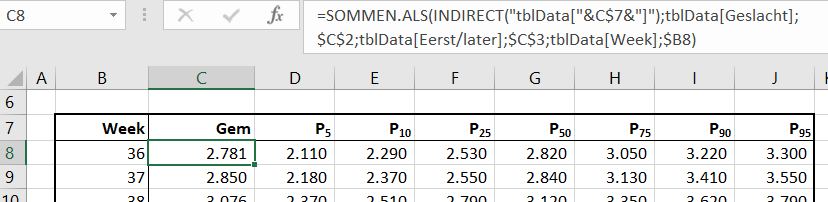
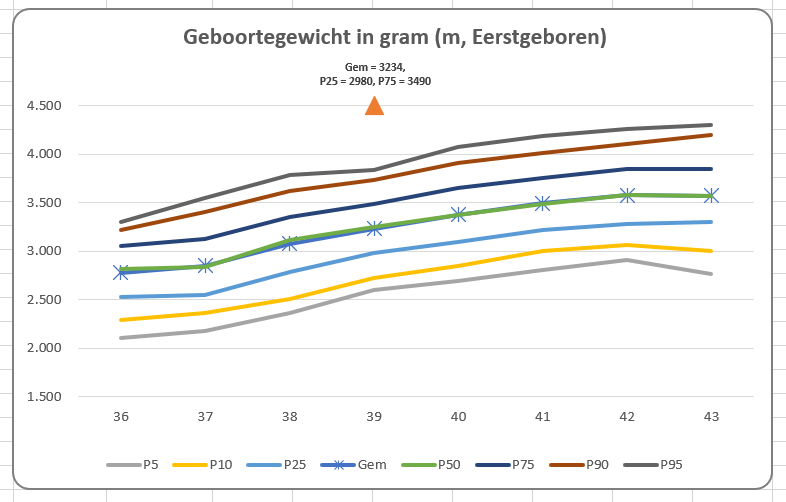
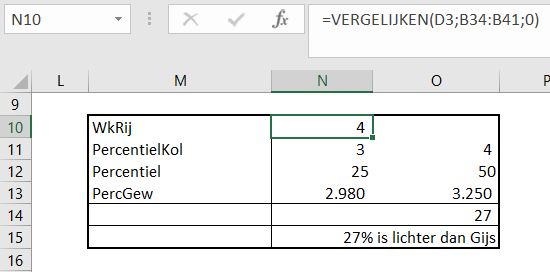
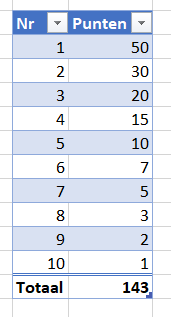
Iedere rapportage-pagina heeft bovenaan 3 blokjes met de belangrijkste gegevens/berekeningen.
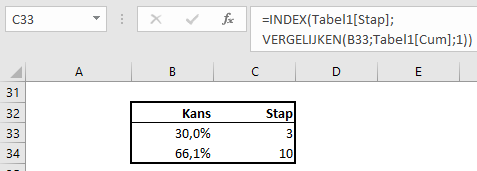
Bij Indeling overzichtsblokken wordt bij DataNr allereerst aangegeven welke 3 van de 10 items moeten worden getoond; bij Berekening kun je 5 opties kiezen die voor deze items moeten worden weergegeven.
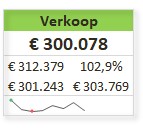
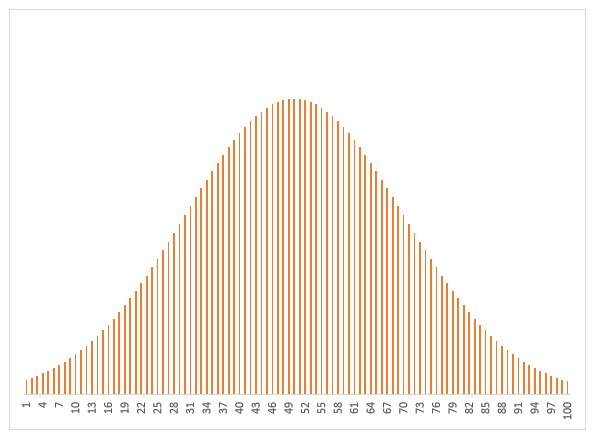
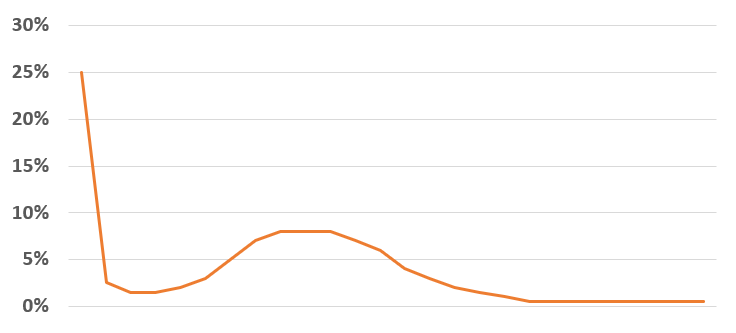
De sparkline daaronder geeft het verloop in de tijd weer van het betreffende item (YtD of YoY). Met de instellingen zoals hierboven is het resultaat:
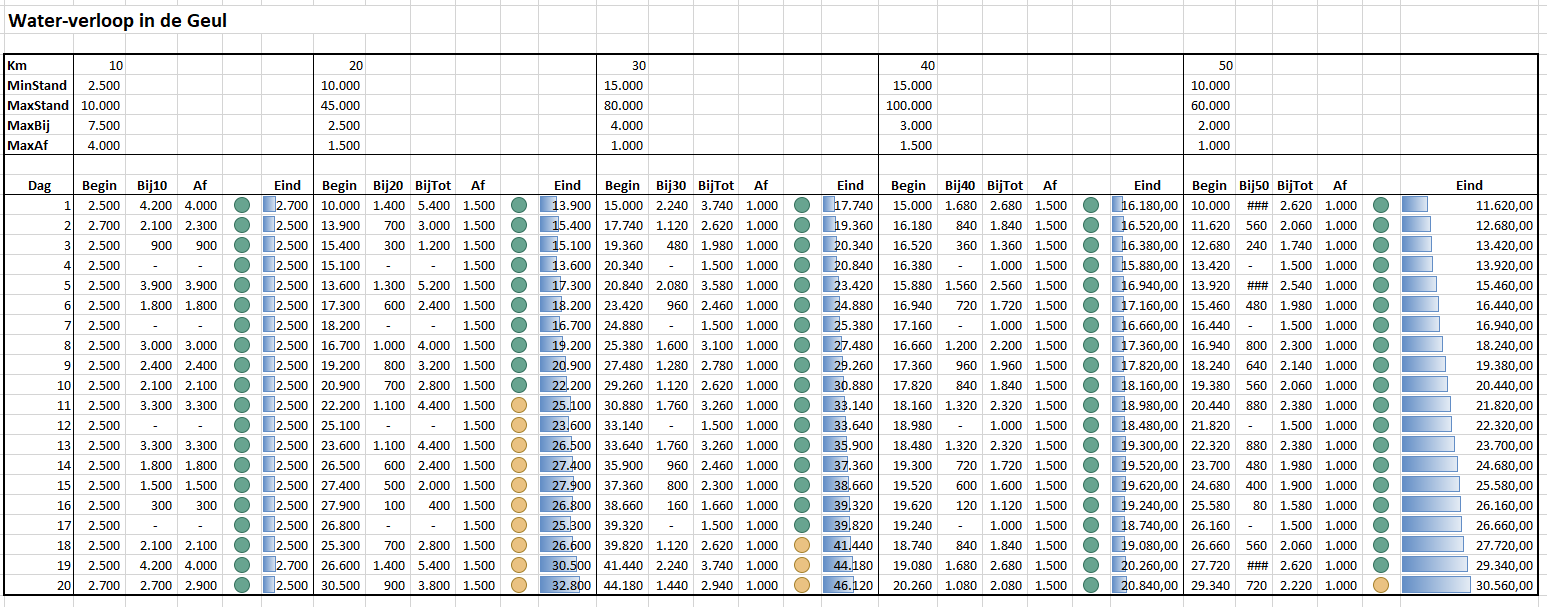
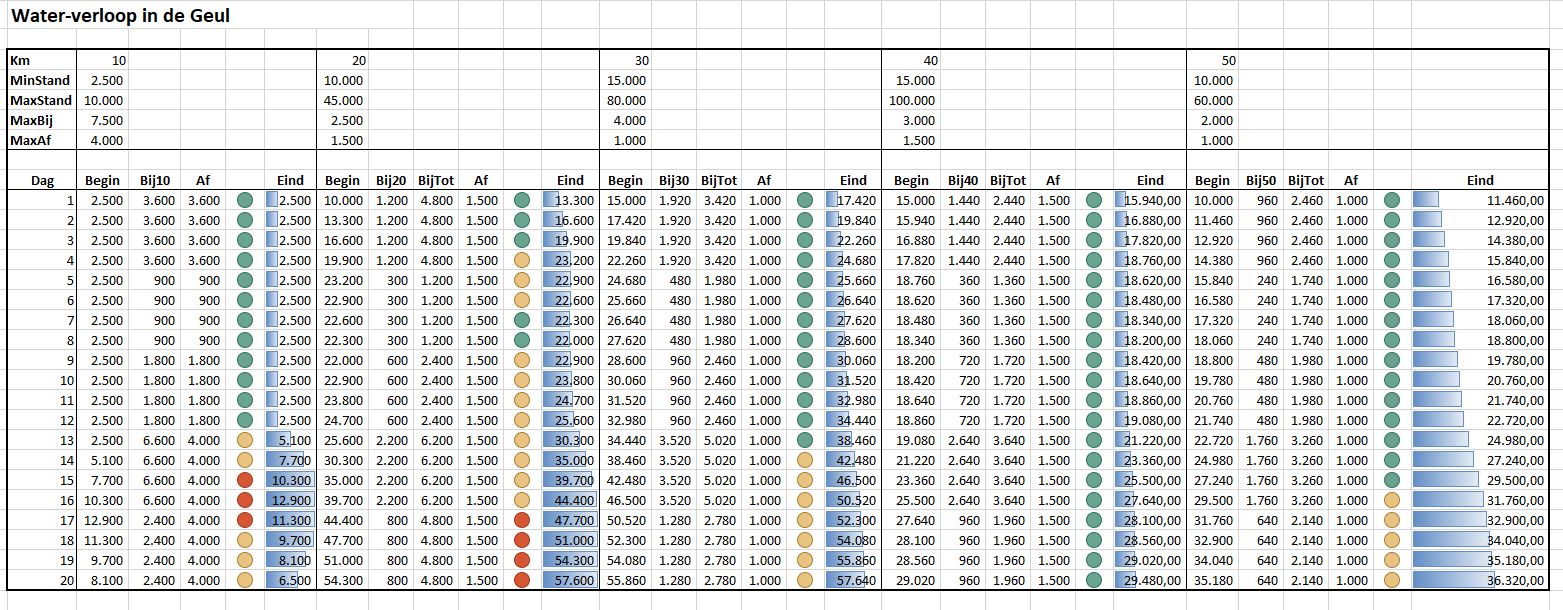
Data
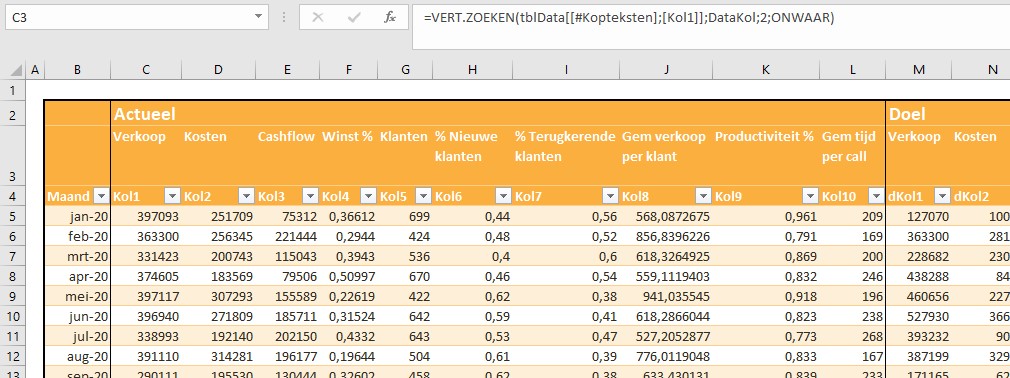
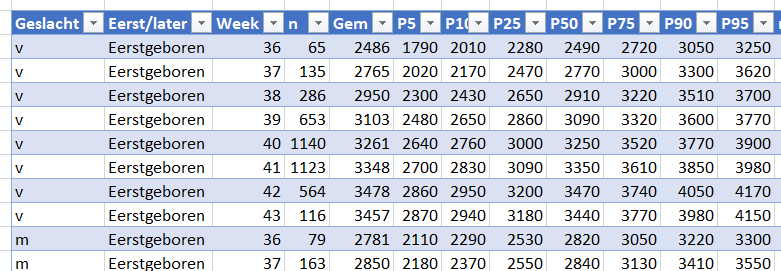
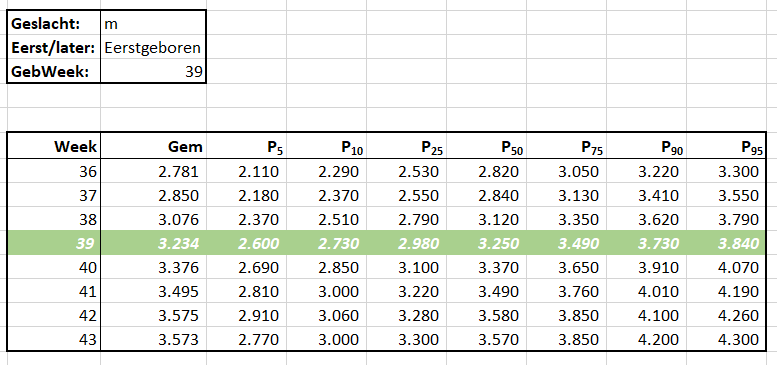
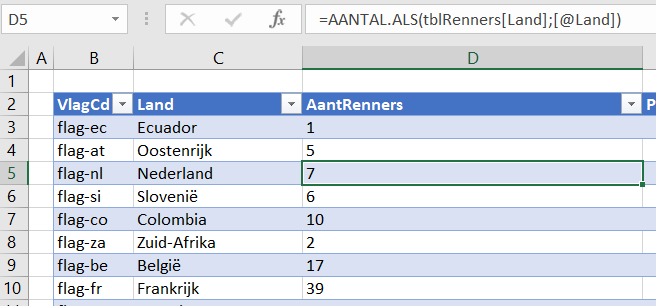
In het Voorbeeldbestand is het tabblad Data gevuld met fictieve gegevens. Het systeem is beperkt tot 10 kolommen met gegevens waarvan de namen vastliggen in het tabblad Instel.
Per maand dienen alle gewenste kolommen met de juiste data gevuld te worden. Gebruik je ook berekeningen waarbij de actuele gegevens afgezet worden tegen de beoogde resultaten dan dienen ook de Doel-kolommen gevuld te worden.
Berekeningen
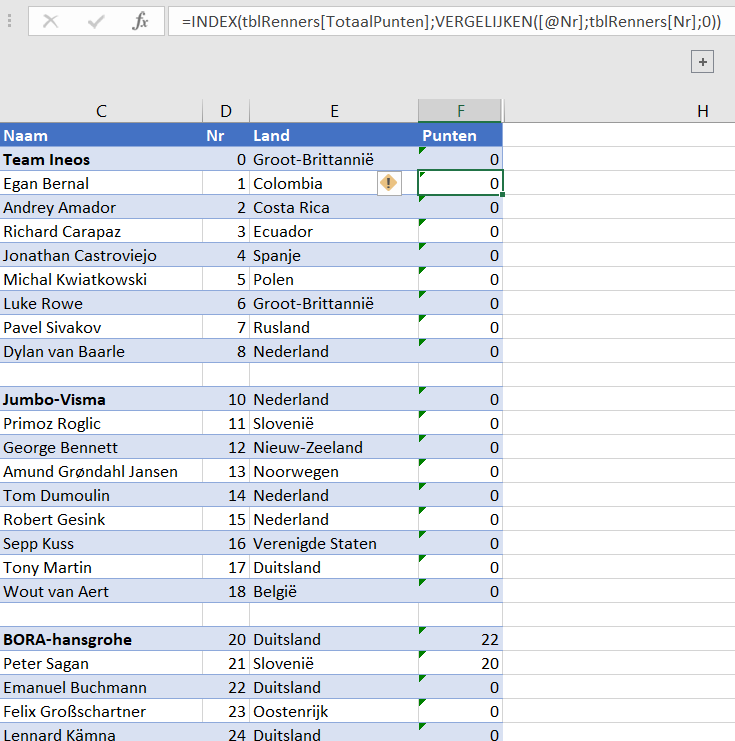
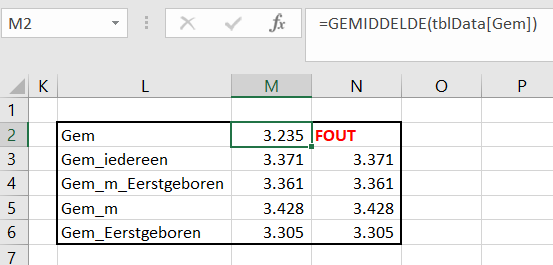
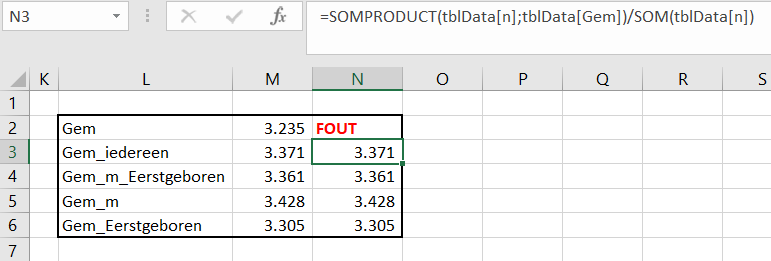
In het tabblad Berekeningen van het Voorbeeldbestand worden allereerst van alle 10 items (en de daarbij behorende doelen) de YoY-data opgehaald.
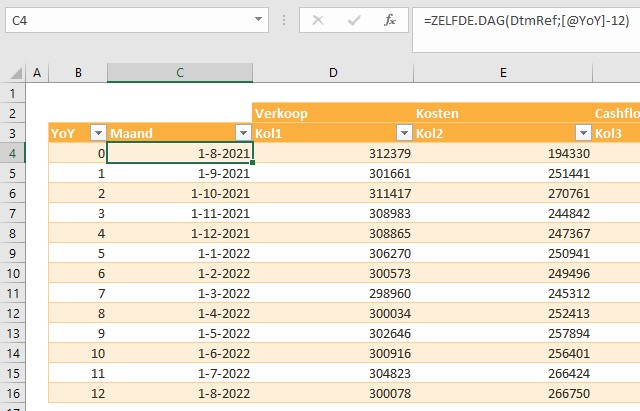

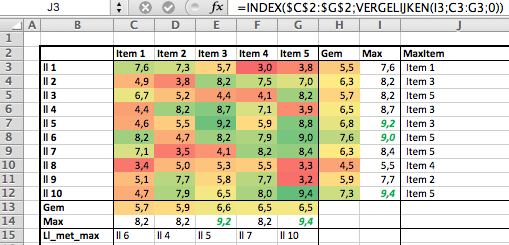
Daaronder wordt de opmaak van (nu) maximaal 16 berekeningen per item bepaald.
De betreffende formule is uitdagend te noemen:
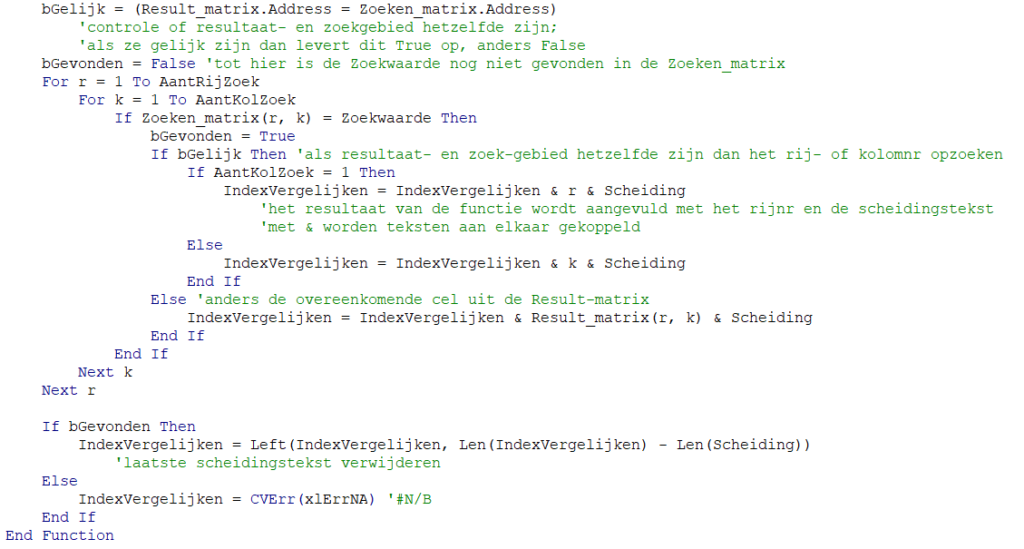
=ALS(INDEX(tblBerekOpties[Opmaak];[@Nr])=0;INDEX(tblOpmaak[OpmCd];VERGELIJKEN(INDEX(tblDataInd[Opmaak];VERGELIJKEN(tblYoY[[#Kopteksten];[Kol1]];tblDataInd[Kolom];0));tblOpmaak[Naam];0));INDEX(tblOpmaak[OpmCd];VERGELIJKEN(INDEX(tblBerekOpties[Opmaak];[@Nr]);tblOpmaak[Naam];0)))
In het derde blok worden de benodigde berekeningen gedefinieerd. In cel D41 staat een simpele verwijzing naar een cel uit het eerste blok.
De formule waarmee berekening 8 (het gemiddelde van de laatste 3 maanden) wordt uitgevoerd, is:
=GEMIDDELDE(VERSCHUIVING(D16;-2;0;3;1))
ofwel we gaan vanaf cel D16 2 regels omhoog en 0 kolommen naar rechts/links en kiezen dan een blok cellen, 3 hoog en 1 breed; van deze range wordt het gemiddelde bepaald.
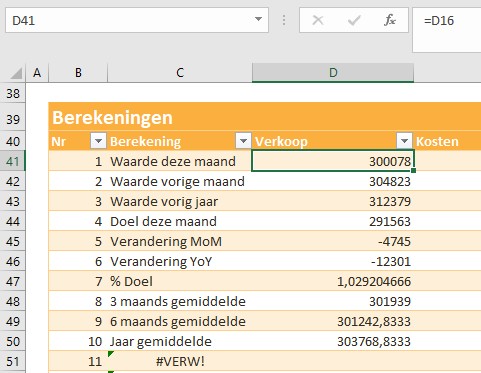

Nog even de vorige 2 stappen combineren met (in cel D61) de formule:
=ALS.FOUT(TEKST(D41;D21);0)
Dus met de functie TEKST wordt de inhoud van cel D41 opgemaakt met de inhoud van cel D21. Als dit onverhoopt een probleem oplevert, dan wordt de waarde 0 weergegeven.
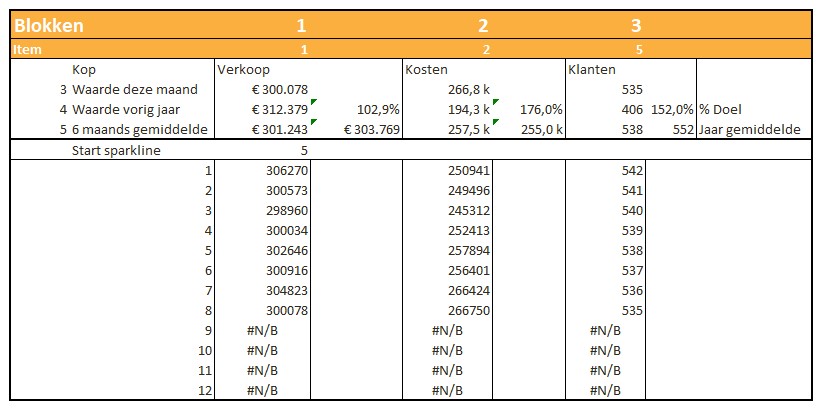
Met al dat voorwerk kunnen we nu de blokjes in de kop van de rapportages samenstellen. Ook de cijfers voor de sparklines worden klaar gezet.
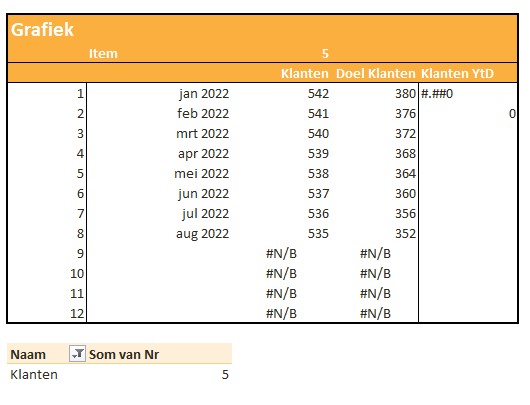
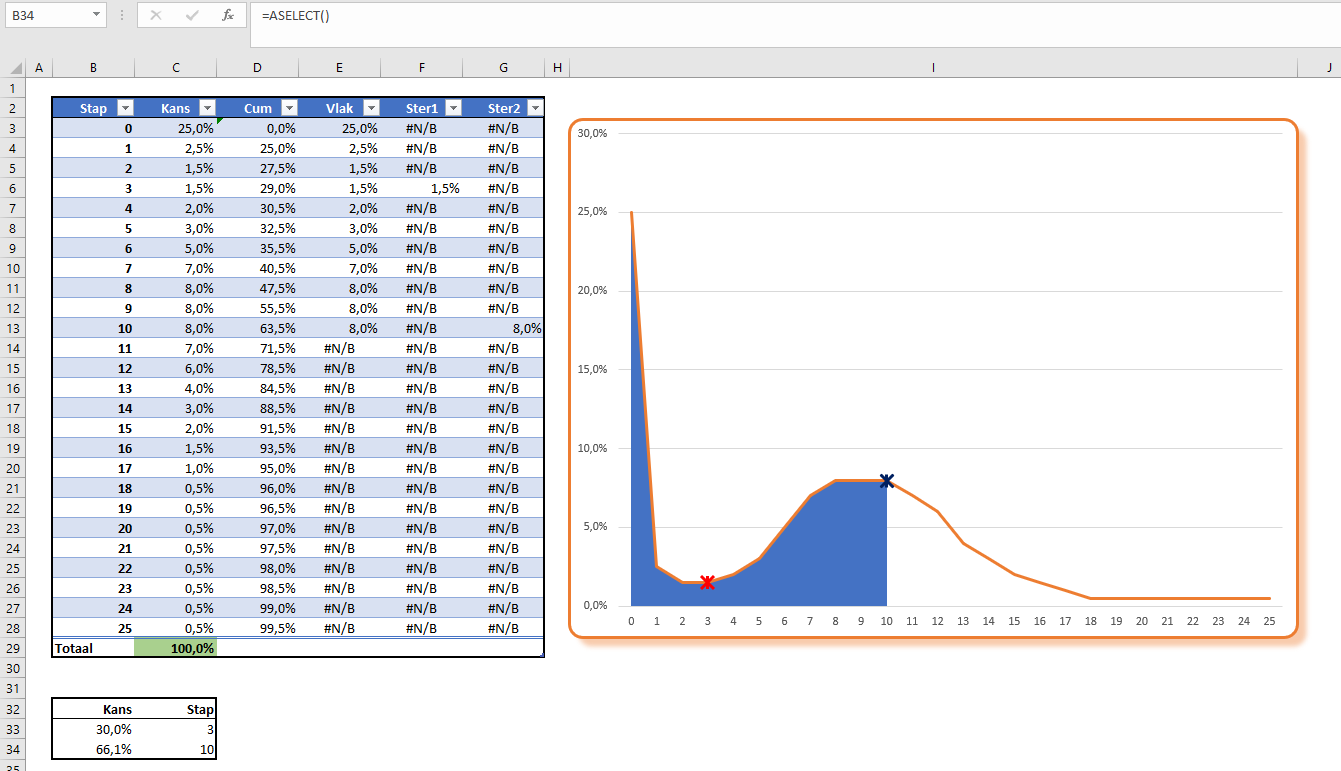
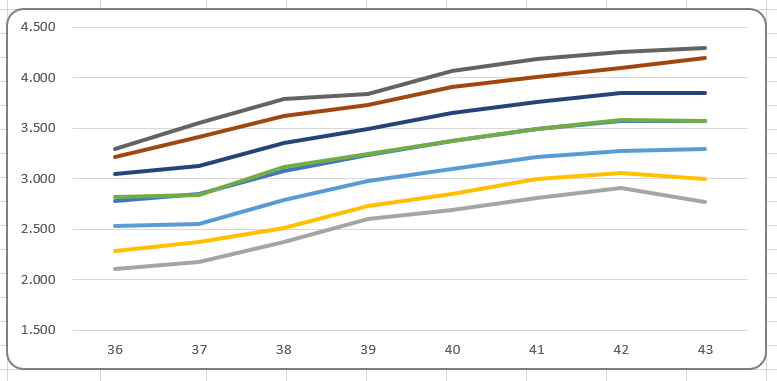
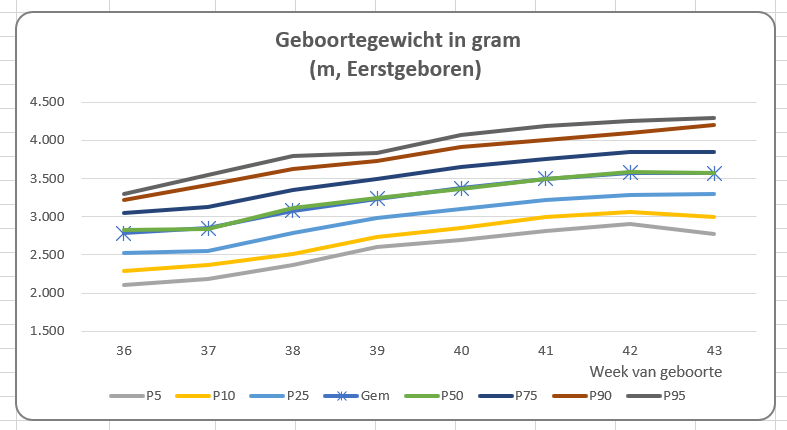
Omdat we ook een grafiek in de rapportage willen opnemen, moeten we de benodigde gegevens nog even klaar zetten.
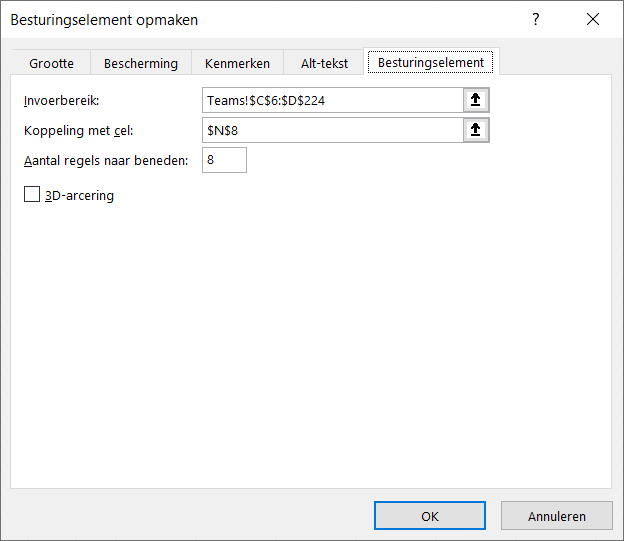
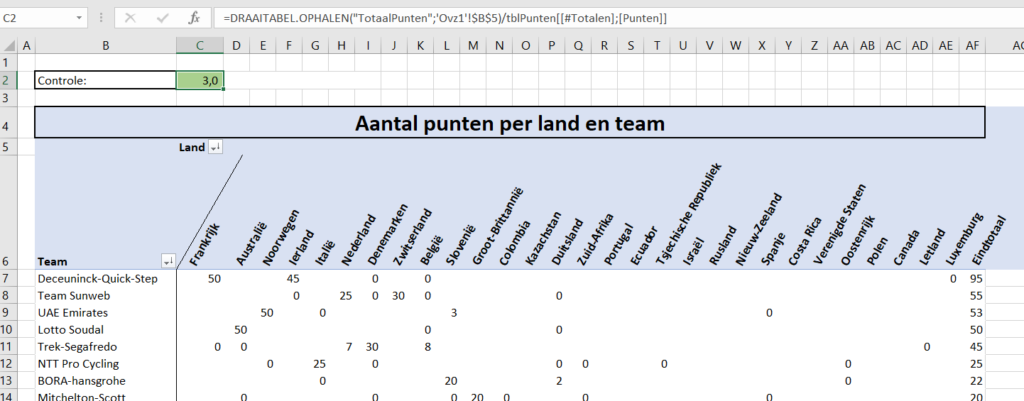
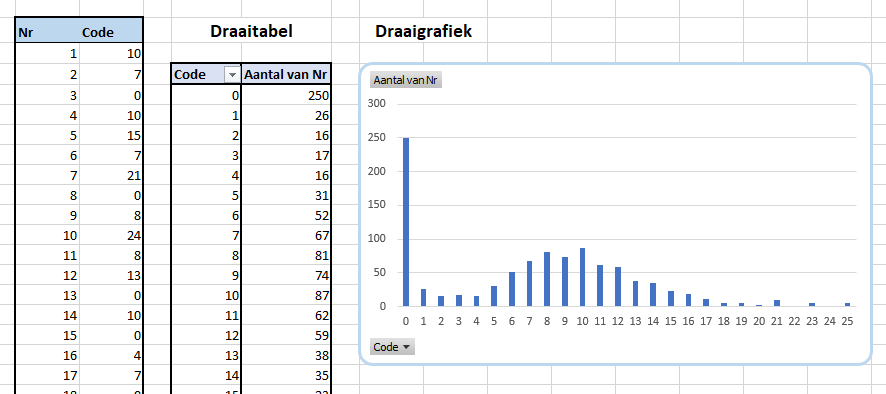
Onderaan staat een draaitabel. Een Slicer in de rapportage bepaalt welk item we willen weergeven. Het betreffende nummer gebruiken we in het grafiekblok.
Rapportage-pagina’s
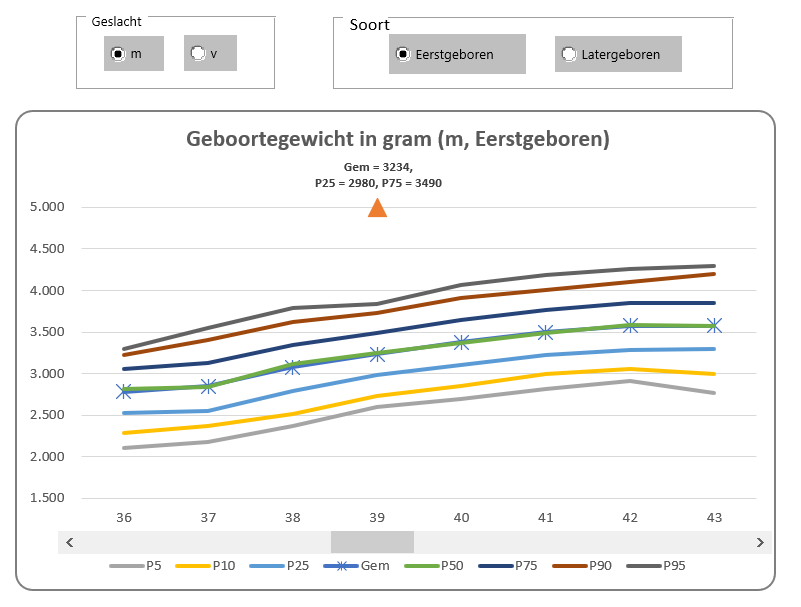
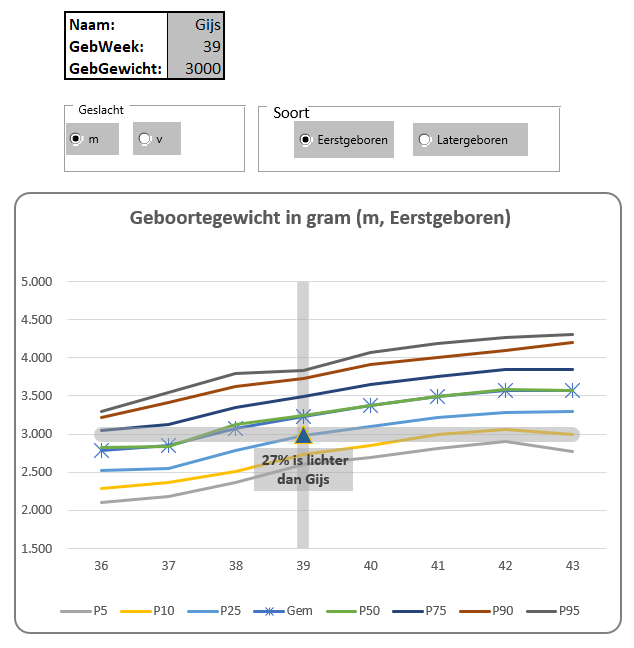
In het tabblad Ovz1 van het Voorbeeldbestand staat een eerste voorbeeld van een rapportage gebaseerd op alle berekeningen uit de rest van het werkblad. Wijzigingen in de diverse tabbladen hebben direct effect op het resultaat. Kies in de slicer aan de rechterkant van de grafiek een ander item en je krijgt de bijbehorende grafiek.
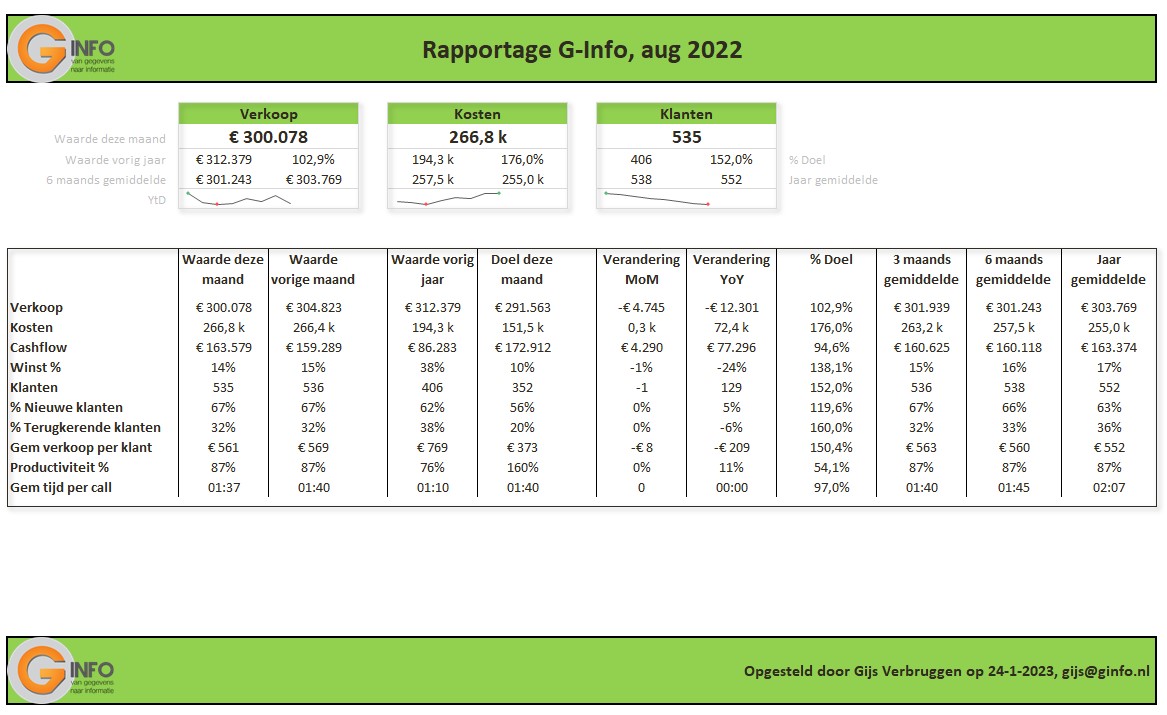
Wil je naast de drie belangrijkste items met de berekeningen in de blokjes aan de bovenkant van de pagina alle info in één oogopslag: zie het tabblad Ovz2 van het Voorbeeldbestand.
Uiteraard is dit nog geen totaal rapportage; ongetwijfeld kunt u nog andere invalshoeken vinden die van belang zijn. Kopieer een Ovz-tabblad en ga aan de slag!

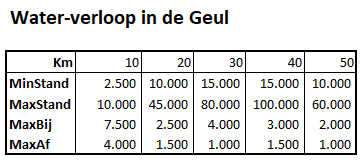
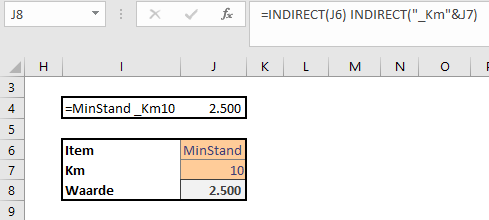
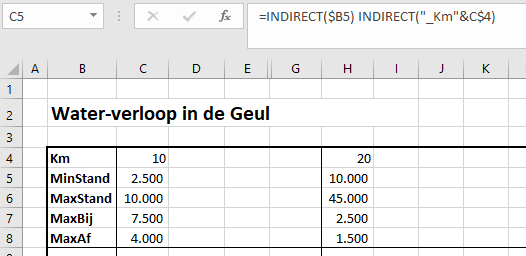
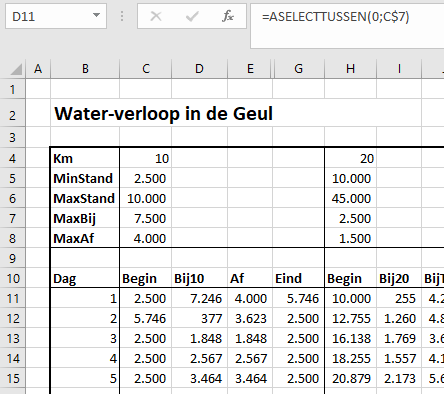
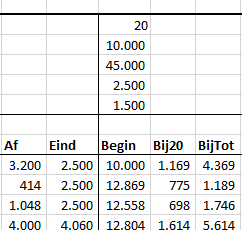
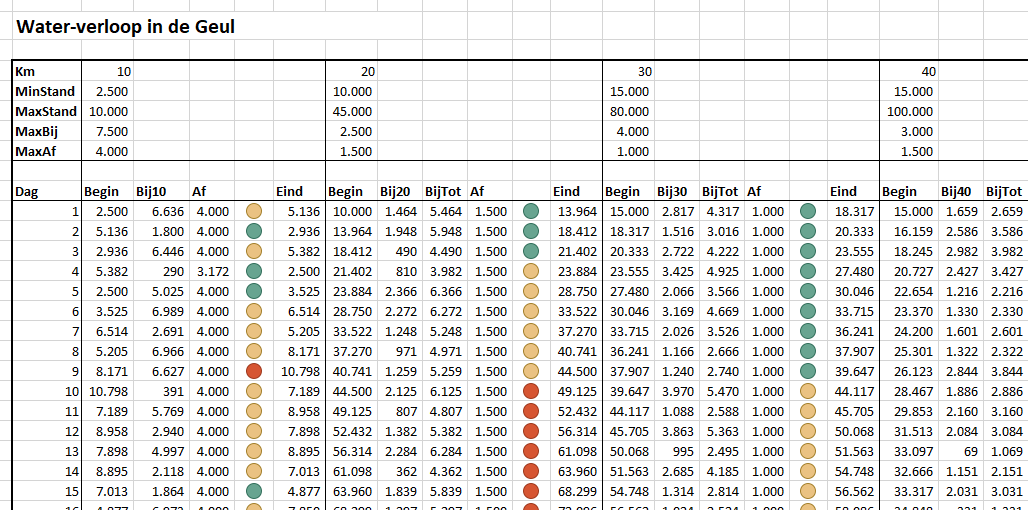
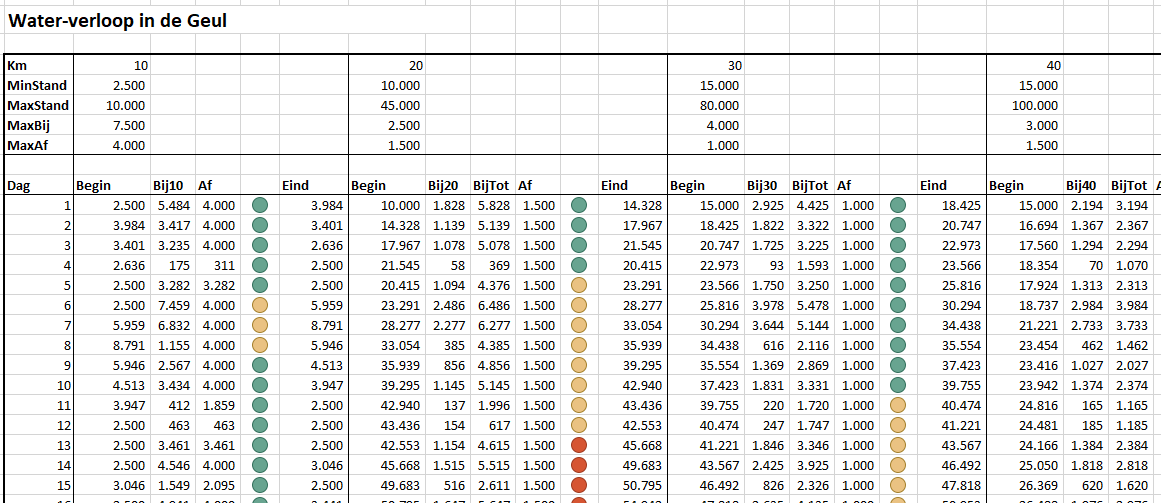
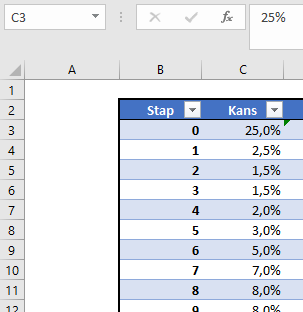

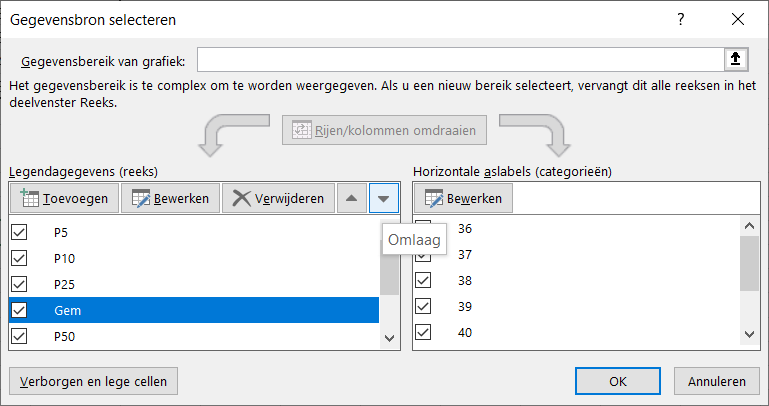




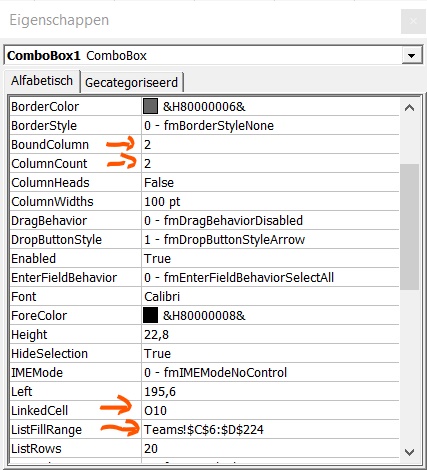
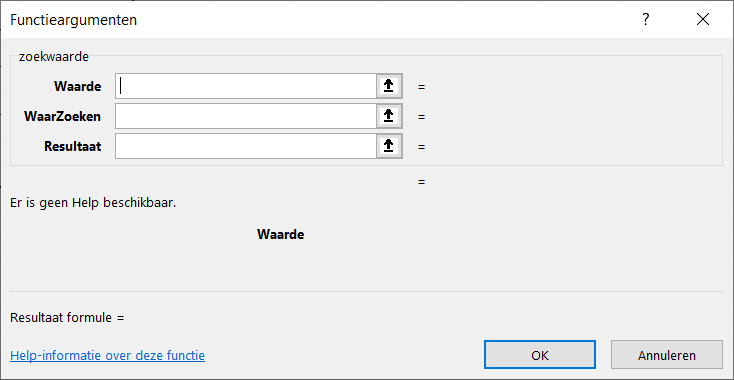
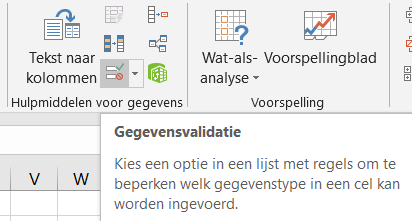 Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen:
Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen: