Vorige week werd duidelijk dat het bedrag aan belastingkorting voor de fossiele industrie in Nederland, vaak ook fossiele subsidies genoemd, veel groter is dan tot nu gedacht/ berekend.
(Foto: Joris van Gennip voor de Volkskrant)
Milieudefensie e.a. hebben op basis van een internationale definitie, opgesteld door de Wereldhandelsorganisatie (WHO), een nieuwe berekening gemaakt. De Nederlandse overheid hanteert dezelfde definitie en methodologie.
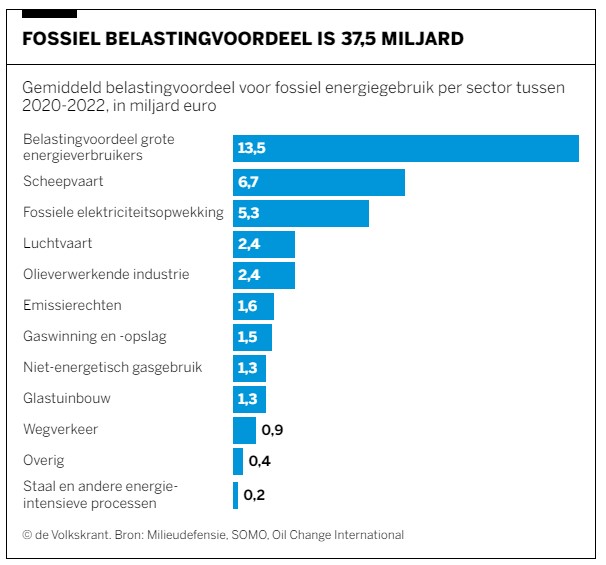
De totale omvang van de subsidies (een gemiddelde over de jaren 2020-2022) wordt in het betreffende rapport geraamd op ruim 37,5 miljard euro per jaar.
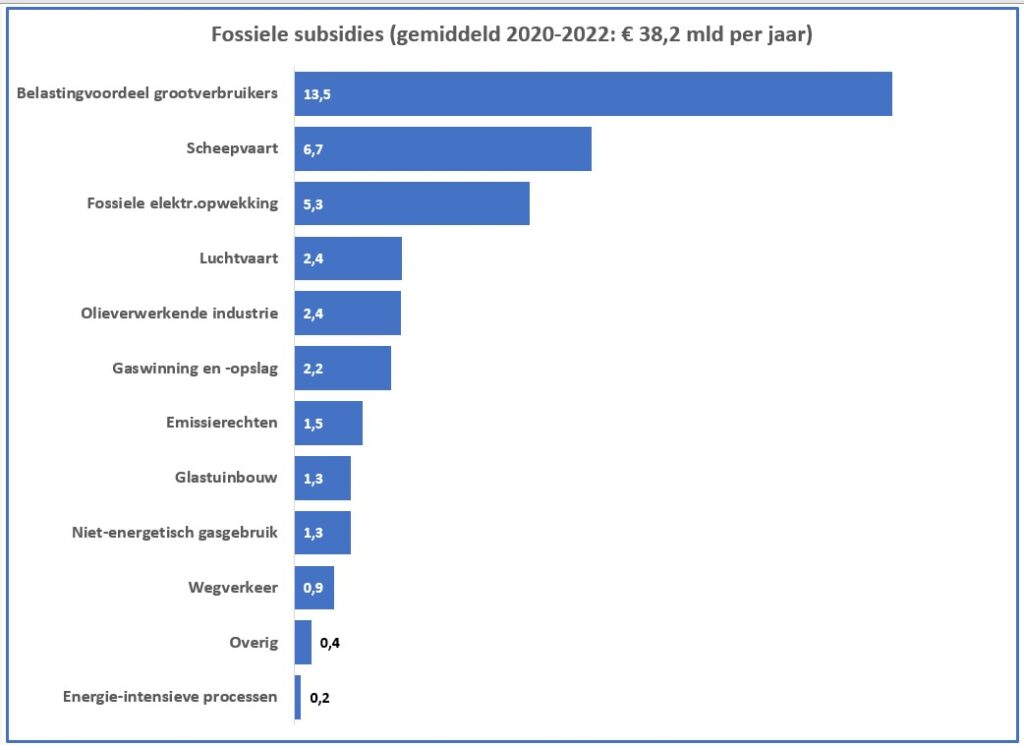
Bij bestudering van de onderliggende cijfers moeten we echter constateren, dat dit bedrag zelfs nog te laag is. Na correctie van een foutieve berekening komen we uit op een totaal van € 38,2 mld.
Hierna zullen we eens kijken naar de gehanteerde methode, de fout in de berekening en hoe je snel enkele soorten grafieken kunt maken die inzicht geven in de verhouding tussen de diverse soorten “subsidies”.
Basis-gegevens
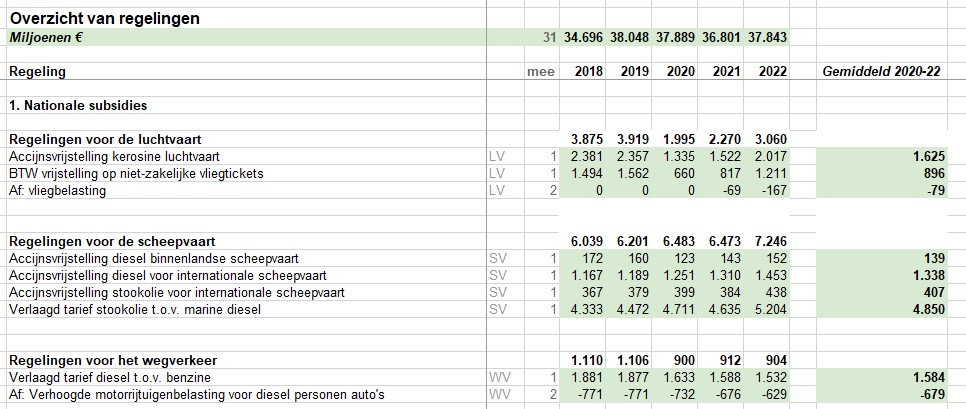
In het tabblad Docu van het Voorbeeldbestand ziet u enkele verwijzingen naar onderliggende documenten. Via de derde link kunt u een spreadsheet downloaden met daarin op detailniveau de gehanteerde berekeningen en bronnen. Transparanter kan niet!
De gemiddelden over 2020-22 uit dit spreadsheet zijn overgenomen in het tabblad Data van het Voorbeeldbestand.
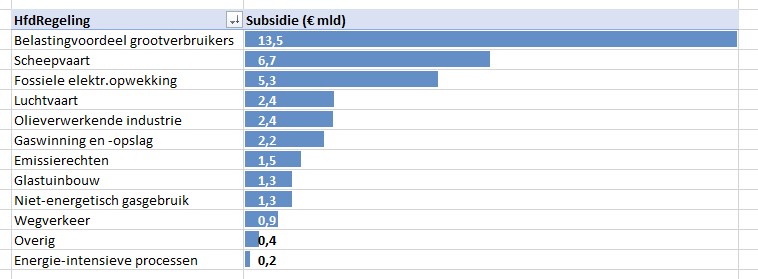
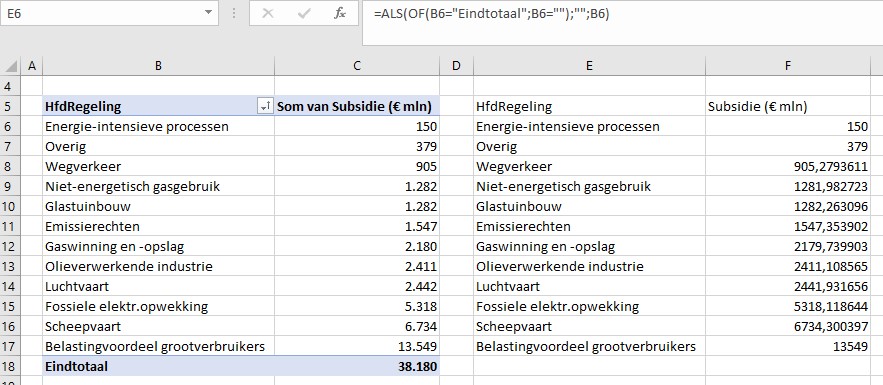
Maken we een overzicht daarvan met behulp van de draaitabel-optie van Excel (zie het tabblad Draai) dan zien we dat dit optelt tot € 38,2 mld en niet 37,5 zoals het rapport aangeeft (en dat door alle media is overgenomen).
We zien dat de post ten voordele van de grootgebruikers het grootste is. In het rapport wordt die hoofdcategorie Regelingen sectoroverstijgende energiebelasting genoemd.
NB wilt u de onderliggende details van een subsidie-bedrag zien? Dubbelklik in de draaitabel op dat bedrag en Excel opent een nieuw tabblad met daarin de betreffende regeling-bedragen.
Afwijking in berekening
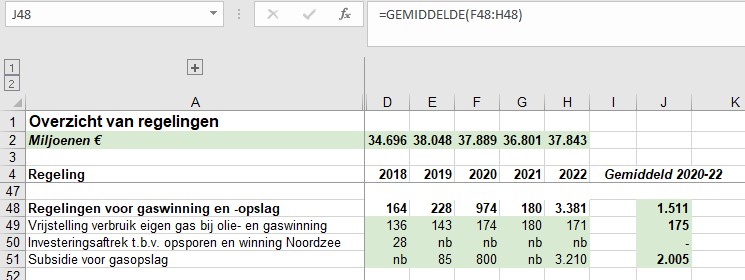
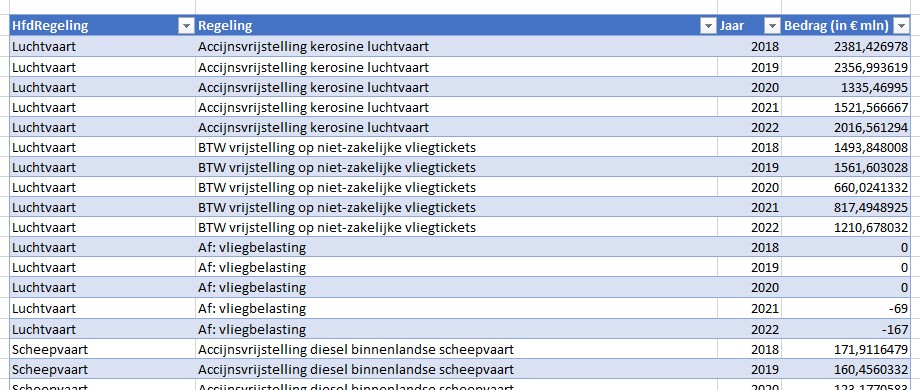
Waar komt het verschil in de totale subsidie-berekening nu vandaan? Hierboven staat een klein gedeelte van de door Milieudefensie e.a. gebruikte cijfers. In cel J48 wordt het gemiddelde over 3 jaar van de categorie gaswinning en -opslag bepaald. Maar dat is niet gelijk aan de som van de onderliggende gemiddeldes! Dat wordt veroorzaakt door de nb in cel G51. Bij het berekenen van het gemiddelde in die regel wordt die cel door Excel (terecht) niet meegenomen; bij het bepalen van het gemiddelde in cel J48 is (impliciet) de nb meegeteld als 0, waardoor dit bedrag lager uitkomt.
LET OP: wanneer je gemiddelden wilt berekenen (of dit nu in Excel is of niet) en er ontbreken basisgegevens, bedenk dan in welke volgorde de berekeningen moeten worden uitgevoerd.
Staafdiagram
Een eerste grafiek, die goed laat zien in welke mate de diverse subsidies bijdragen aan het totaal-bedrag is het zogenaamde staafdiagram (zie het tabblad Graf in het Voorbeeldbestand):
klik ergens in de draaitabel op het tabblad Draai van het Voorbeeldbestand
kies in de menutab Hulpmiddelen voor draaitabellen in het blok Analyseren op Draaigrafiek
kies de optie Staaf
zorg dat in de draaitabel de bedragen gesorteerd staan van laag naar hoog (via rechts-klikken)
selecteer bij Grafiekelementen de optie Gegevenslabels
klik rechts op één van de gegevenslabels en kies Gegevenslabels opmaken
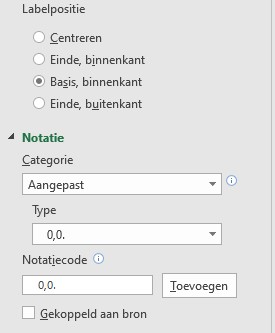
pas de Labelpositie aan en maak een aangepaste Notatie: 0,0. Dus een paar spaties, een nul, een komma, weer een nul en dan een punt. Excel zal de getallen dan van extra spaties aan de voorkant voorzien, zorgen dat er 1 decimaal wordt weergegeven en, door de punt achter de cijfers, dat hij moet afronden op duizendtallen.
de positie van de onderste 2 gegevenslabels zijn gewijzigd door nog een keer extra op deze labels te klikken en de opmaak aan te passen (Einde, buitenkant)
pas ‘naar smaak’ nog wat extra opmaak toe
De grafiek is ook voorzien van een dynamische titel:
klik ergens in de grafiektitel
tik in de formulebalk het volgende in: =Draai!$E$2
op het tabblad Draai staat in cel E2 de formule: =”Fossiele subsidies (gemiddeld 2020-2022: € “&TEKST(DRAAITABEL.OPHALEN(“Subsidie (€ mln)”;$B$5);”0,0.”)&” mld per jaar)”
Staafdiagram 2
Een vergelijkbare grafiek kun je ook direct in de draaitabel maken (zie het tabblad Draai2 in het Voorbeeldbestand):
klik op één van de cellen in de bedragenkolom van de draaitabel
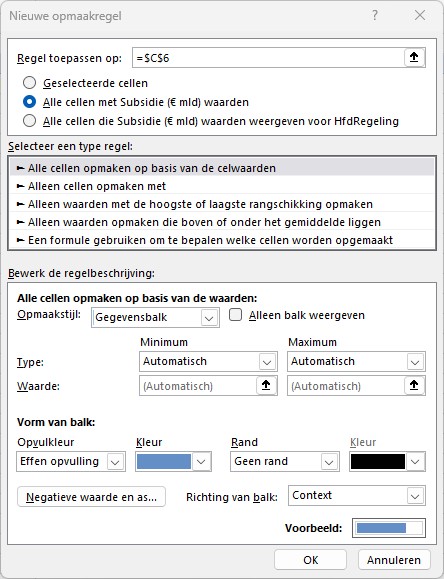
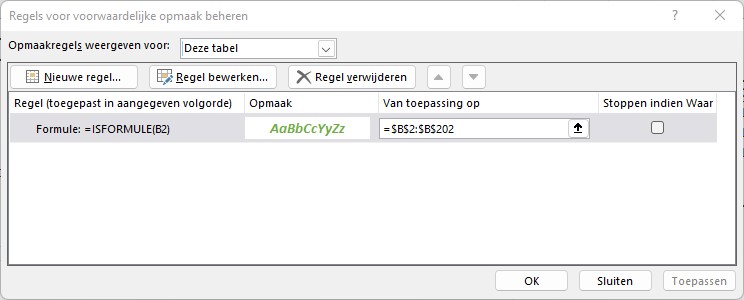
klik in de menutab Start in het blok Stijlen op Voorwaardelijke opmaak en kies de optie Nieuwe regel
vul het tussenscherm in, zoals hiernaast. Het keuzerondje zorgt er voor dat als de draaitabel later uitgebreid wordt, de nieuwe gegevens ook deze opmaak krijgen.
klik rechts op één van de bedragen en kies de optie Getalnotatie. Ook hier zorgen we weer voor een aangepaste notatie: 0,0.
de kop van de bedragenkolom moeten we nog veranderen, want er worden nu geen miljoenen meer weergegeven maar miljarden.
NB wilt u nog wat tips voor het opmaken van draaitabellen kijk dan op het tabblad Docu van het Voorbeeldbestand; daar staat een verwijzing naar een internet-artikel en naar een ‘spiekbriefje’.
Treemap
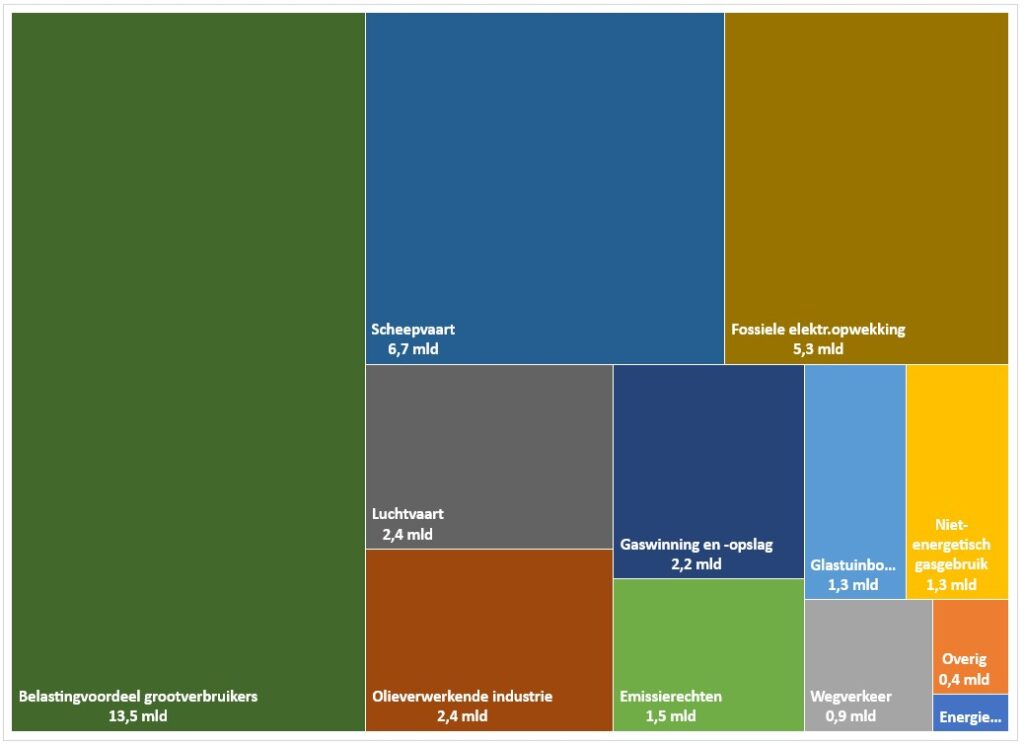
Het tabblad Tree1 van het Voorbeeldbestand bevat een ander soort grafiek, waarmee de verhouding tussen de onderdelen goed zichtbaar gemaakt kan worden, een zogenaamde Treemap.
Helaas kan die niet als Draaigrafiek rechtstreeks op een draaitabel gebaseerd worden (tenminste niet in mijn Excel-versie 2019). We hebben een tussenstap nodig (zie het tabblad Draai):
Naast de draaitabel maken we dus een verwijzing naar die gegevens. Selecteer de betreffende kolommen en kies in de menutab Invoegen in het blok Grafiek de optie Hiërarchiegrafiek. Daar vindt u de Treemap-optie. De treemap is op een grafiekblad Graf geplaatst, zodat we een grafiek overhouden zonder ‘afleiding’ daar omheen. Excel schikt de diverse categorieën zodanig dat er een mooi gevulde rechthoek ontstaat. Helaas: bij het verder opmaken van de grafiek zult u merken dat het niet mogelijk is om een dynamische titel toe te voegen. En ook de oplossing met een Tekstvak gaat hier niet werken.
Dezelfde treemap staat ook op een gewoon Excel-blad (zie het tabblad Tree2). Nu kun je wel een tekstvak toevoegen en daarin een verwijzing maken naar cel E2 in het tabblad Draai.
Een ander voordeel van het plaatsen op een gewoon Excel-blad is dat je de vorm van de rechthoek kunt aanpassen aan je eigen wensen:
Extra data
Voor de liefhebbers heb ik met behulp van Power Query uit de bron wat meer details opgehaald (zie het tabblad Data2 in het Voorbeeldbestand):
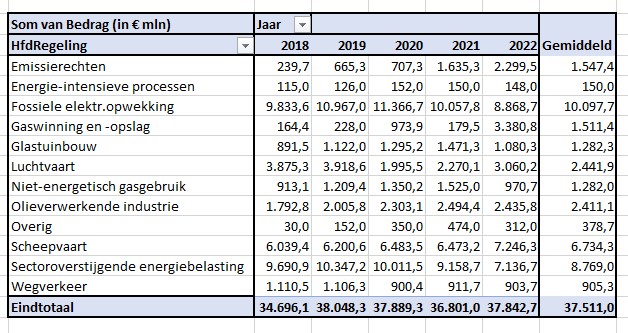
Op basis van deze data kun je diverse overzichten genereren, bijvoorbeeld een draaitabel op hoofdregeling-niveau over de jaren:
LET OP: het probleem met het middelen zoals hierboven aangegeven, steekt hier ook weer de kop op!
LET OP: na het downloaden de extensie wijzigen in xlsb
In het vorige artikel (Grenzen aan de groei – 1) hebben we beloofd dat we een poging zouden wagen om het model uit het rapport van de Club van Rome in Excel te implementeren, althans een vereenvoudigde versie daarvan. In dat artikel is te lezen hoe we dat zouden willen doen en aan de hand van wat vingeroefeningen hebben we laten zien dat het (in theorie) mogelijk zou moeten zijn.
Die laatste conclusie staat nog steeds, maar helaas hebben we wel moeten constateren dat de hoeveelheid verbanden tussen de diverse variabelen en de daarbij behorende parameters zo groot is dat een totale implementatie heel erg veel tijd gaat kosten. Dus deze keer vormt het Voorbeeldbestand geen afgerond project. In dit artikel zullen we laten zien hoe ver we gekomen zijn en welke Excel-opties daarbij zijn gebruikt.
Voor eenieder de uitdaging om de ‘handdoek in de ring’ weer op te rapen en het model verder uit te werken!
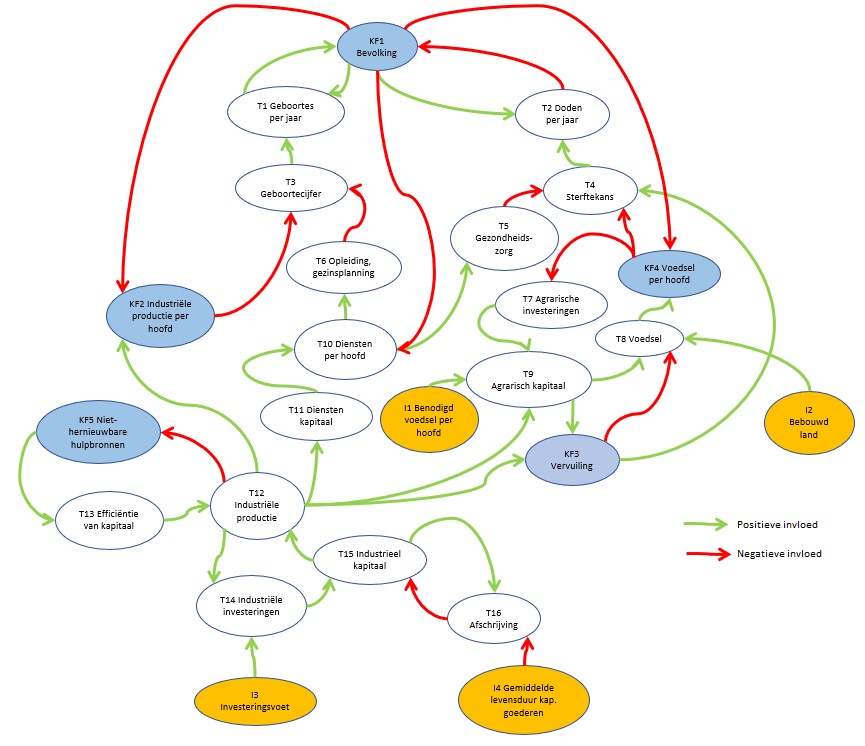
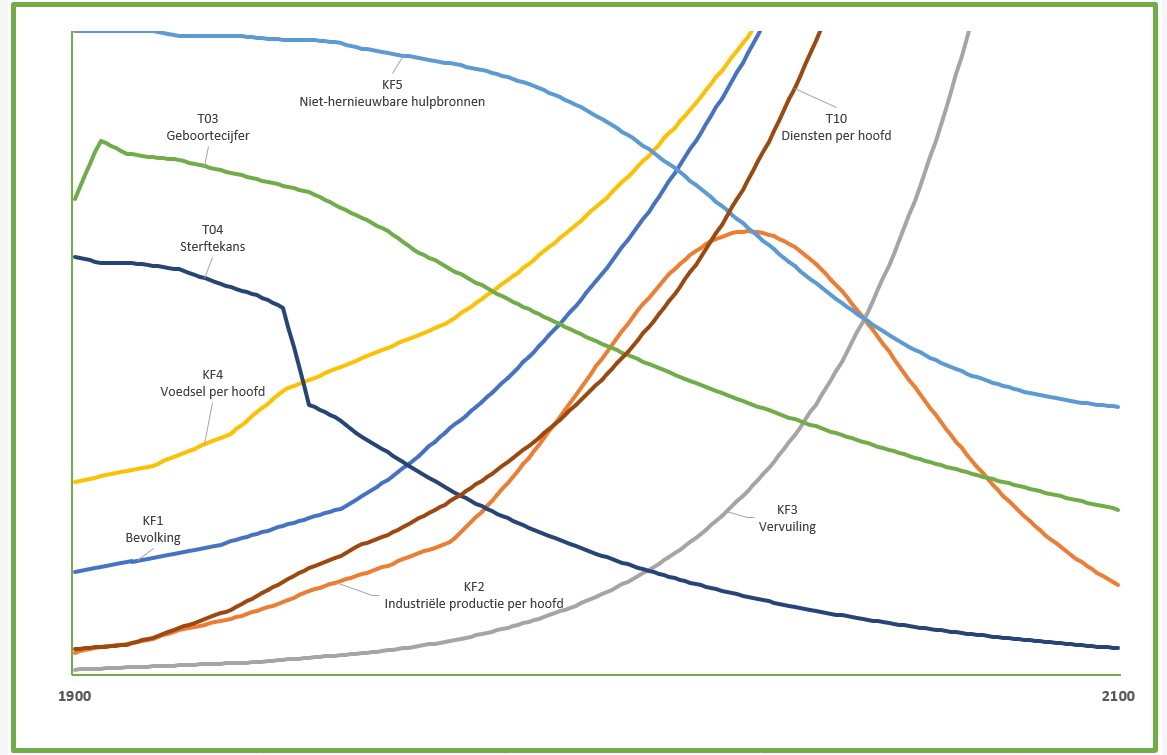
Dit is een schematische weergave van het (vereenvoudigde) ‘Club van Rome’-model; voor nadere uitleg zie het vorige artikel.
Belangrijk om te weten is het volgende:
de pijlen geven aan welke relaties er tussen de variabelen zijn onderkend
de pijlen laten zien in ‘welke richting’ de beïnvloeding loopt
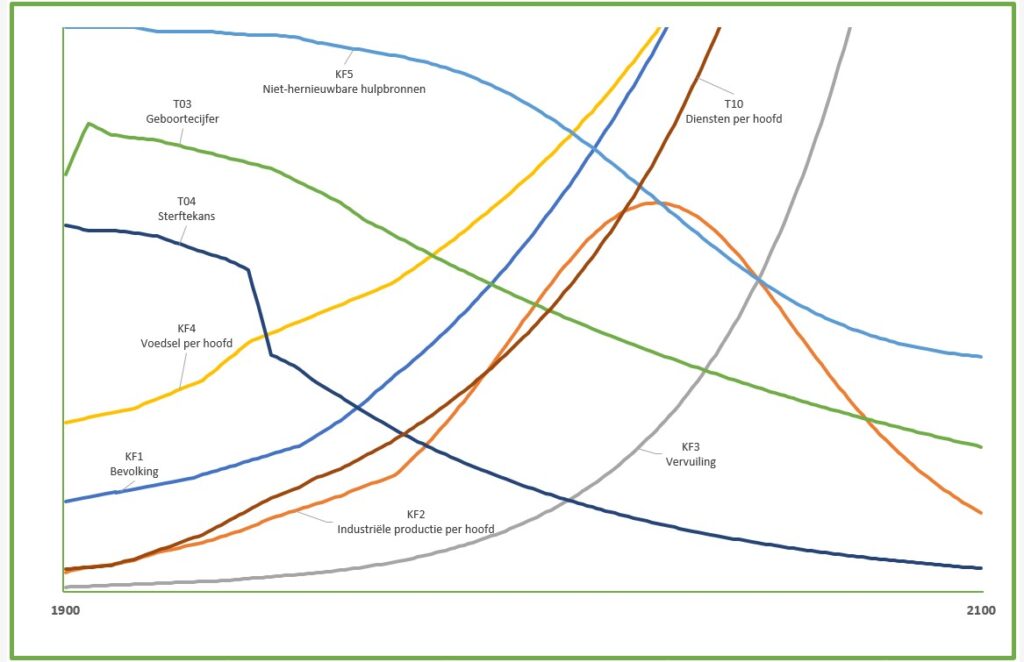
we onderkennen in het model 3 soorten variabelen: de Inputs, de Kritische Factoren en de Tussen-variabelen. De Input-variabelen worden niet beïnvloed door de omgeving, maar kunnen wel in de loop van de jaren variëren. De KF’s zijn die 5 variabelen die in alle grafieken van het rapport terugkomen. Alle overige vallen onder de categorie Tussen-variabelen.
het rapport van de Club van Rome is in 1972 gepubliceerd; waar in dit artikel naar het verleden wordt verwezen bedoelen we dan ook de periode van 1900 tot en met 1970.
voor diverse variabelen is in de literatuur (zie het tabblad Docu van het Voorbeeldbestand) te achterhalen wat de waardes in het verleden zijn geweest. Dit is de eerste basis van de implementatie van het model.
bij de verdere implementatie heeft iedere variabele een eigen tabblad gekregen (behalve de Inputs; zie hierna). Alle aannames voor de berekening van een variabele staan in het betreffende tabblad vermeld. Vaak is daar ook een grafiek opgenomen van die variabele om snel het resultaat van de aannames te controleren.
Tabblad T15
Implementatie
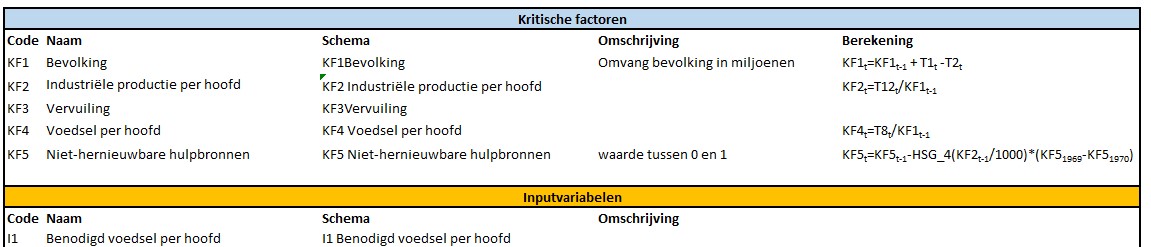
Tabblad Beschr
In dit tabblad van het Voorbeeldbestand staat een overzicht van alle gebruikte variabelen met daarbij (zover al uitgezocht) de meest relevante berekening:
De betekenis van de Code en de Naam moge duidelijk zijn; de kolom Schema bevat de tekst zoals die op het tabblad SystemDynamics wordt gebruikt. In de kolom Omschrijving staat in het kort een nadere toelichting op de variabele en de laatste kolom bevat de (belangrijkste) formule voor de berekening van die variabele.
NB de codes onder de 10 voor de Tussenvariabelen hebben een extra 0 gekregen; dit om bij standaard-sorteringen altijd direct de juiste volgorde te hebben (anders zou bijvoorbeeld T10 vóór T2 komen).
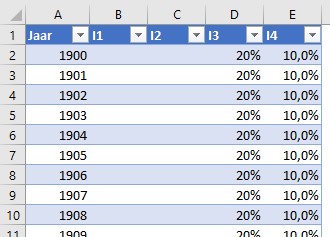
Tabblad Inputs
Dit tabblad bevat de gegevens van de 4 Input-variabelen. Deze vormen samen de Excel-tabel tblInputs.
Op dit moment zijn alleen de I3 en I4 gevuld en per kolom hebben alle jaren dezelfde waarde. De juiste interpretatie van deze variabelen vergt nog onderzoek.
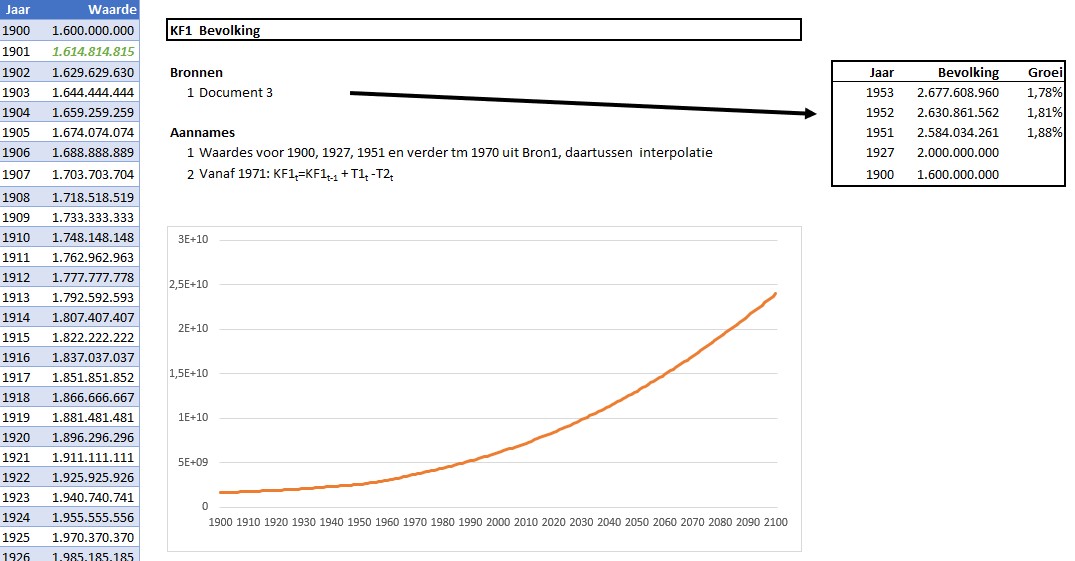
De KF-tabbladen
Zoals gezegd hebben alle KF’s (en ook de Tussen-variabelen) een eigen tabblad. Deze bladen hebben allemaal dezelfde structuur: de eerste kolom bevat de jaren en de tweede kolom de daarbij behorende waarde. Samen vormen deze 2 kolommen een Excel-tabel met een overeenkomende naam (in bovenstaand voorbeeld tblKF1).
NB de waarde-kolom heeft een voorwaardelijke opmaak: wanneer een cel een formule bevat dan wordt de inhoud in het groen, vet en cursief weergegeven.
In de volgende kolommen staat altijd de code en naam van de variabele, eventueel gebruikte bronnen en de diverse aannames. De rest van het tabblad wordt gebruikt om zo nodig extra berekeningen uit te voeren, de aannames toe te lichten etcetera.
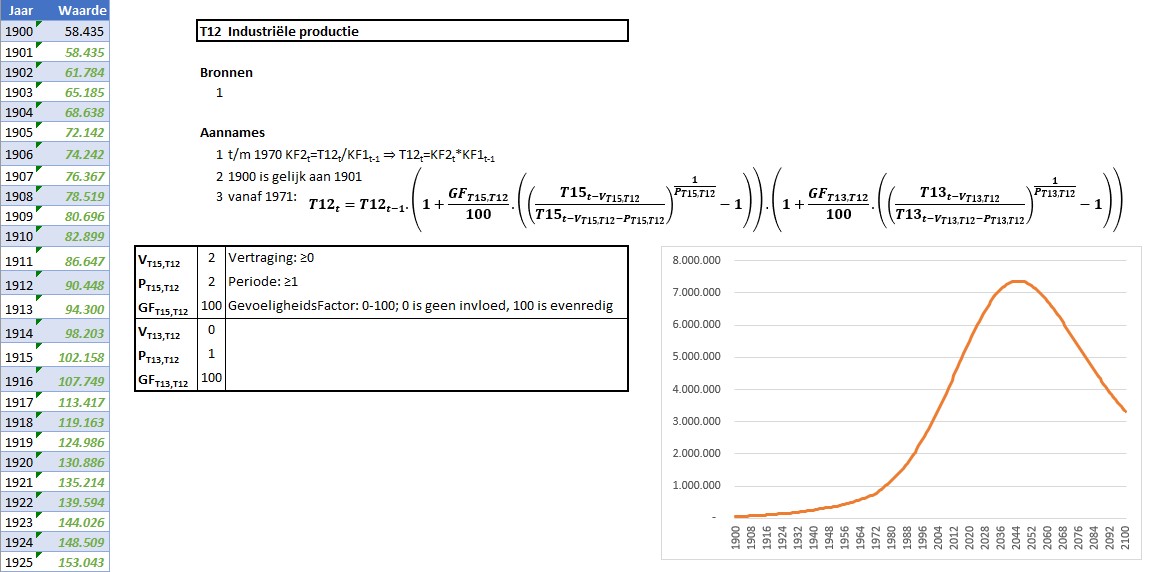
Zoals aangegeven hebben deze tabbladen dezelfde structuur als de KF’s. In het voorbeeld hierboven is te zien dat voor T12 een formule wordt gebruikt, waarbij de gevoeligheid (GF) voor de invloed van een variabele kan worden ingesteld. Daarnaast kan aangegeven worden of de beïnvloeding een vertraging V kent en of er over een periode P gemiddeld moet worden (zie het artikel Grenzen aan de groei – 1).
LET OP in dat artikel hebben we, bij het gebruik van een periode, een rekenkundig gemiddelde gebruikt. Dat is, theoretisch gezien, niet juist. Hoewel dat in dit model, bij niet te grote ontwikkelingen in de tijd, niet echt relevant is, hebben we toch de betere methode gehanteerd waarbij het gemiddelde wordt bepaald met behulp van de Pde-machts wortel (ofwel tot de macht 1/P).
Resultaten
In principe zijn de resultaten van het model bekend als alle tabbladen zijn gevuld met waardes en formules. Door ’te spelen’ met de aannames, en vooral met de eventuele GF-, V– en P-waardes kan het model gefinetuned worden.
We zijn gestart met de onderkant van het model, het gedeelte rond de Industriële productie. De bovenkant is op de uitkomsten daarvan gebaseerd. Het implementeren van deze onderkant heeft heel wat hoofdbrekens gekost (wat is de betekenis van de variabelen, hoe zijn deze variabelen van elkaar afhankelijk, hoe kunnen we de afhankelijkheid modelleren, welke GF-, V– en P-waardes geven een zo getrouw mogelijk beeld van de werkelijkheid etcetera).
Door tijdgebrek moet G-Info het verder vullen van het model dan ook aan anderen overlaten.
Wel zullen we hieronder nog laten zien op welke manier de resultaten in Excel gemakkelijk kunnen worden weergegeven.
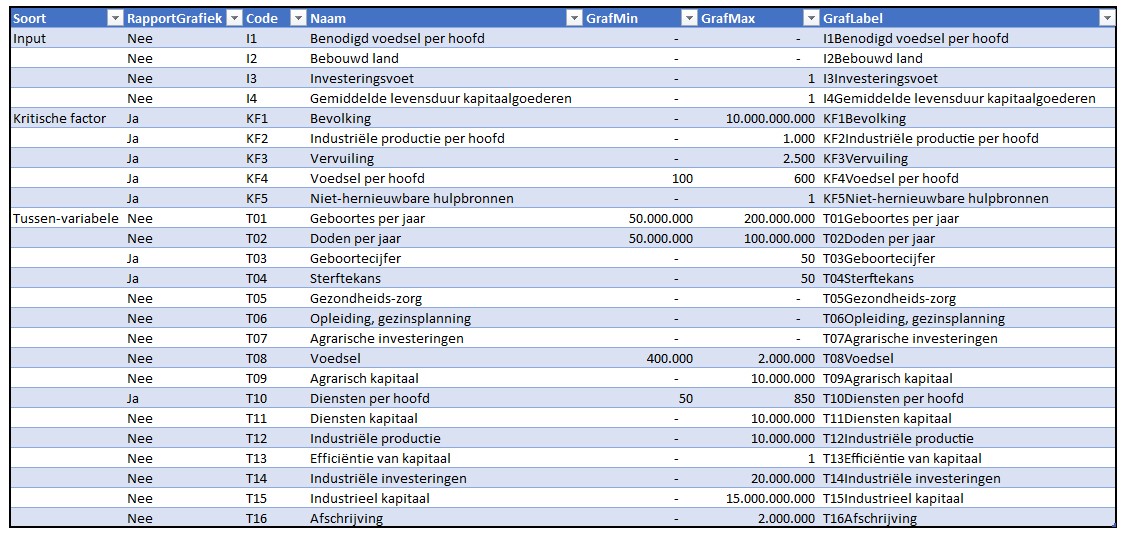
Tabblad Variabelen
Op dit tabblad in het Voorbeeldbestand staan de 25 variabelen van het model nogmaals in een overzicht. Maar ditmaal met aanvullende gegevens, waarmee we de lay-out van de output kunnen sturen:
in de eerste kolom staat aangegeven welk soort variabele het betreft: Input, KF of Tussen
de tweede kolom geeft aan of de betreffende variabele in de standaard-grafieken van het rapport van de Club van Rome is opgenomen
in dat rapport wordt een variabele altijd op dezelfde (onzichtbare) schaal weergegeven. Dat kunnen we nabootsen door aan te geven welke waarde van de variabele overeenkomt met de onderkant van het grafiekgebied (de kolom GrafMin) en welke waarde met de bovenkant (GrafMax)
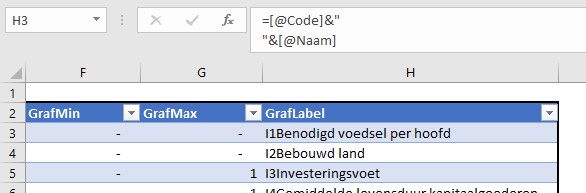
in de laatste kolom staat een formule waarmee het label bij de betreffende lijn in de grafiek wordt bepaald. Standaard is het een combinatie van de 3e en 4e kolom, gescheiden door een ‘harde return’:
Dit overzicht is een Excel-tabel met de naam tblVar.
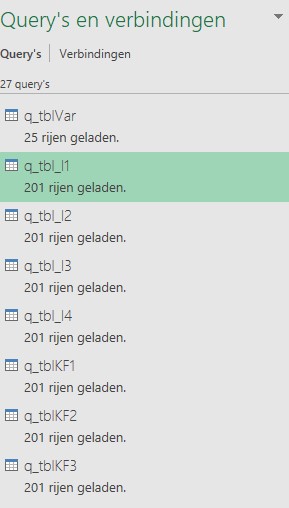
Query’s en verbindingen
Alle resultaten moeten nu nog geschaald worden. Dit kan uiteraard op de diverse tabbladen zelf door extra kolommen toe te voegen, maar we hebben er voor gekozen om dit met behulp van Power Query te implementeren.
NB1 Ziet u de Excel-verbindingen aan de rechterkant van het scherm niet, kies dan in de menutab Gegevens de optie Query’s en verbindingen.
Voor alle Excel-tabellen is een verbinding gemaakt. Wil je bekijken hoe die er uit ziet? Klik rechts op een verbinding en kies de optie Bewerken (of dubbel-klik op een query-naam).
NB2 de Input-query’s zijn iets ingewikkelder omdat daar één specifieke kolom uit de input-tabel moet worden opgehaald.
Bij het bewaren van de query’s is de optie Alleen verbinding maken gekozen en is de optie Toevoegen aan gegevensmodel aangevinkt. Die laatste optie zorgt er voor dat de query’s in het gegevensmodel van deze Excel-sheet worden opgeslagen.
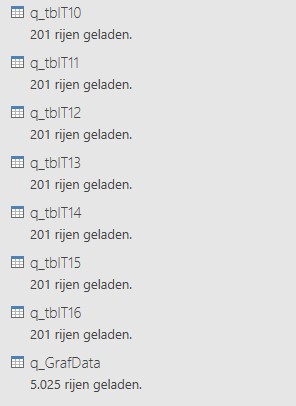
Het gegevensmodel bevat nog één extra query, q_GrafData. Deze combineert alle andere verbindingen tot één database. Deze database vormt de basis voor een draaitabel en een daarbij behorende grafiek. Ook deze query is opgeslagen met de eigenschappen Alleen verbinding en Toevoegen aan gegevensmodel.
Bekijk de query door dubbelklikken op de naam.
Tabblad GrafData
Op het tabblad GrafData van het Voorbeeldbestand staat een draaitabel, gebaseerd op de query q_GrafData. Hoe genereer je zo’n draaitabel?
selecteer een lege cel, waar de draaitabel moet komen
kies in de menutab Invoegen in het blok Tabellen de optie Draaitabel
in het pop-up scherm ziet u dat Excel het gegevensmodel zal gaan gebruiken:
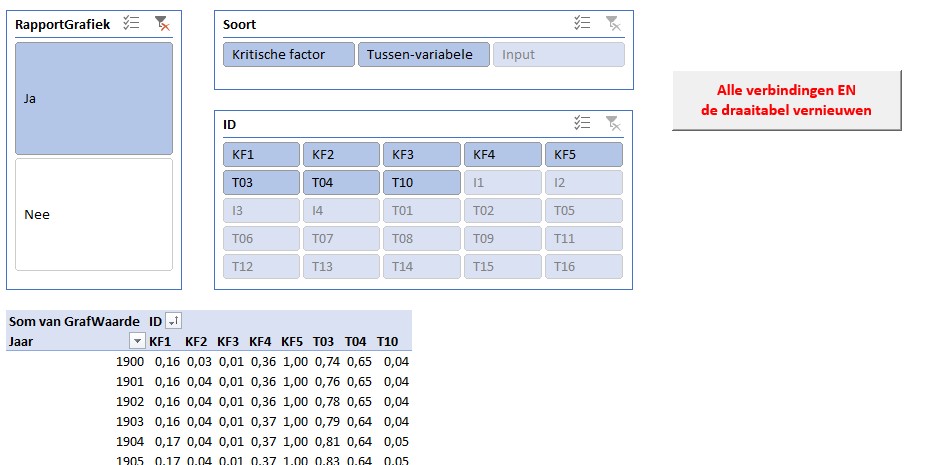
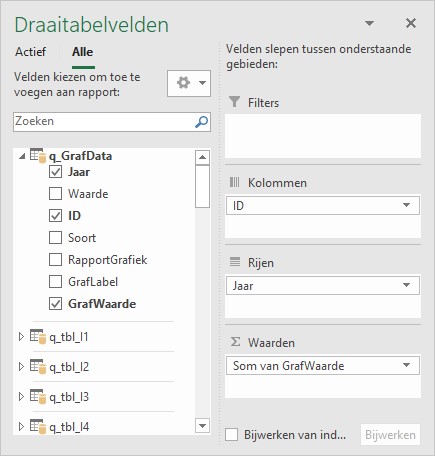
klik op het driehoekje vóór de gewenste query uit het gegevensmodel en sleep de benodigde velden naar de juiste plaats:
In het voorbeeld hebben we ook 3 slicers toegevoegd waarmee het maken van keuzes vergemakkelijkt wordt. Hierboven hebben we met een klik op Ja in de eerste slicer alleen die variabelen geselecteerd, die ook in het rapport van de Club van Rome in de standaard-grafieken voorkomen.
LET OP als er iets aan de parameters van het model wordt gewijzigd dan worden de gegevens op het betreffende tabblad direct gewijzigd. Ook resultaten van formules op andere tabbladen kunnen daardoor wijzigen. De query’s en de draaitabel wijzigen niet automatisch mee! Alles zal vernieuwd moeten worden. Op het tabblad GrafData wordt met één klik op de betreffende button een VBA-routine gestart die deze totale verversing van het Excel-systeem voor zijn rekening neemt. Dit kan wel enkele minuten duren!
Tabblad Grafiek
Het tabblad Grafiek van het Voorbeeldbestand bevat een draaitabelgrafiek. Dit is de grafische weergave van de gegevens van de draaitabel van het tabblad GrafData. Dus: ook keuzes gemaakt met de slicers worden in deze grafiek meegenomen.
Duidelijk is te zien dat de implementatie van het model nog lang niet klaar is. De industriële productie en de hulpbronnen geven bijvoorbeeld wel al een verwacht verloop, terwijl de blijvende toename van de bevolking of voedsel per hoofd niet reëel is. Het model in het Voorbeeldbestand is dan ook nog maar voor een klein gedeelte geïmplementeerd. Zoals gezegd: tijdgebrek noopt ons om de rest aan andere Excel-liefhebbers over te laten.
Binnen Excel, maar beter gezegd binnen alle Office-onderdelen, is het mogelijk om allerlei nuttige, mooie en/of grappige Symbolen in te voegen.
Maar niet alleen symbolen, ook (wat Microsoft noemt) Vergelijkingen. Daarmee wordt het opzetten van een documentatie-tabblad in Excel of een technisch artikel in Word a-piece-of-cake 😉.
In dit artikel zoomen we in op de diverse mogelijkheden om symbolen in te voegen en op het maken van Vergelijkingen. We maken daarbij gebruik van Excel, maar in de andere Office-onderdelen is de werkwijze vergelijkbaar.
Ook zullen we aandacht besteden aan de zogenaamde ASCII– en Unicodering.
Symbolen-1
Er zijn allerlei manieren om symbolen in te voeren. De eerste die we hier behandelen is het invoegen van Speciale tekens. Kies in de menutab Invoegen in het blok Symbolen de optie Symbool:
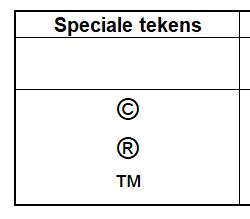
In de pop-up selecteert u het tabblad Speciale tekens. Kies bijvoorbeeld het copyright-teken en klik op Invoegen (of dubbelklik op het teken).
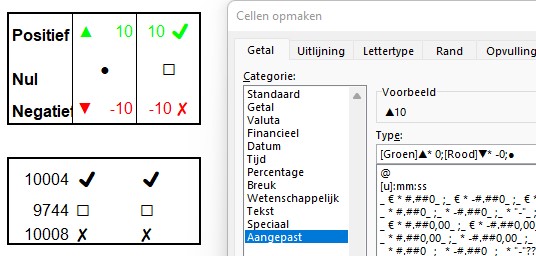
Op het tabblad Symbolen van het Voorbeeldbestand ziet u het resultaat.
LET OP wat er op het scherm wordt weergegeven is afhankelijk van het gekozen lettertype voor de cel. Wijzig het lettertype voor de range B4:B6 in Wingdings en het resultaat is
Symbolen-2
Wanneer bovengenoemde pop-up tevoorschijn komt, is altijd automatisch het tabblad Symbolen geactiveerd. NB1 maak het pop-up-scherm groter om een beter overzicht van alle mogelijkheden te krijgen.
Selecteer het gewenste symbool en klik op Invoegen.
NB2 De meeste lettertypes bevatten veel meer symbolen dan je zou denken. Zorg ervoor dat onderaan bij van: de optie Unicode (hex) is gekozen; je kunt dan diverse deelverzamelingen kiezen:
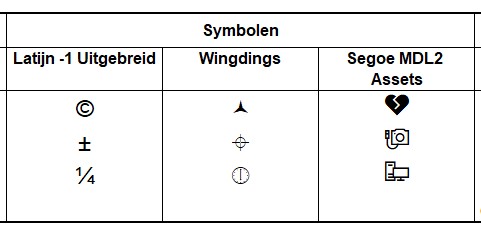
In het tabblad Symbolen van het Voorbeeldbestand zijn op bovenstaande manier symbolen ingevoegd. De symbolen in de eerste kolom komen uit de deelverzameling Latijn-1; als achteraf het lettertype van deze kolom gewijzigd wordt, dan zullen de symbolen er vaak nog hetzelfde uitzien met slechts typografische verschillen.
Maar kies je bijvoorbeeld als lettertype Wingdings dan is de inhoud ineens anders (zie 2e kolom)! Dit is dan ook een lettertype vol met vreemde symbolen. Er is standaard ook nog een tweede en derde versie van dit font. Het lettertype Segoe MDL2 Assets zit vol met verrassingen (zie kolom 3). Ook met het lettertype Webdings kun je veel mooie symbolen tevoorschijn toveren.
LET OP niet iedere Windows-versie kent dit tweede font; soms kom je Segoe-symbol tegen.
ASCII versus Unicode
Voordat we verder gaan over symbolen moeten we aandacht besteden aan de coderingen van letters en andere symbolen. In het begin van het computertijdperk is de ASCII-codering bedacht. Ieder teken werd door 1 byte voorgesteld (eigenlijk pas later in de Extended ASCII) met als consequentie dat er maar 256 mogelijkheden waren. Dat was toen geen probleem: alle hoofd- en kleine letters, cijfers en leestekens passen daar in. Zoals hierboven te zien is was er ook voorzien in de meest gangbare breuken, Griekse letters en letters met diakritische tekens. Later zijn daar de Unicodes bijgekomen; in versie 2.0 is er plaats voor een miljoen tekens. Ruim voldoende voor diverse talen en andere nuttige symbolen.
Wat kunnen we zelf met die codes? Uiteraard zijn die niet (allemaal) te onthouden. Maar natuurlijk wel van symbolen die we vaak nodig hebben; dan is het lastig als je iedere keer in die hele serie symbolen moet gaan zoeken.
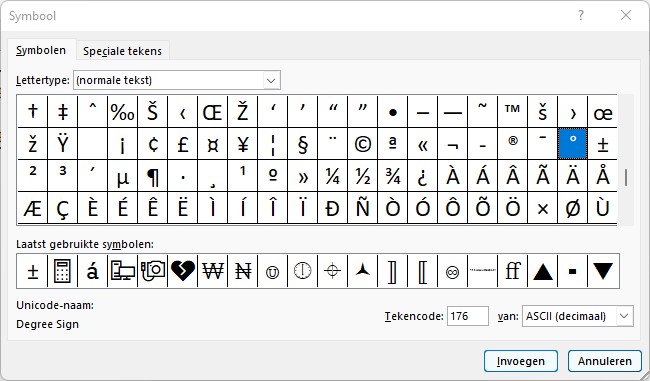
Laten we een voorbeeld nemen; het graden-teken.
Even zoeken maar dan hebben we hem; onderaan de pop-up is te zien dat dit symbool in ASCII de (decimale) code 176 heeft. Kiezen we voor de optie Unicode (hex) dan is de code 00B0:
Hebben we nu weer het graden-teken nodig: open het pop-up-scherm, kies een van de 2 coderingen en voer bij Tekencode de overeenkomende code in en klik op Invoegen.
Symbolen-3
Als een lettertype/font symbolen kent die binnen de ASCII-codes voorkomen (en dus een Tekencode hebben in de soort ASCII) dan kunnen deze symbolen nog veel sneller ingevoerd worden (zie het tabblad Symbolen):
tik in een cel de tekst Het is nu 19 (inclusief de spatie achter de 9)
hou de Alt-toets ingedrukt en tik op het numerieke toetsenbord de code 0176 in.
tik in C en druk op Enter.
NB1 deze Alt-invoer kan alleen met de numerieke toetsen aan de rechterkant van het toetsenbord; zorg wel dat de NumLock aanstaat.
LET OP ASCII-codes vanaf 128 moeten bij dit type invoer voorafgegaan worden door een 0 (nul).
Symbolen-4
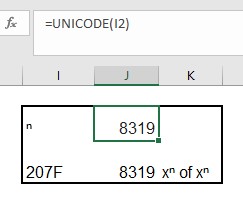
Wanneer je de Unicode van een symbool weet kun je deze ook nog op een andere manier gebruiken. Stel dat we de n (superscript-n) willen gebruiken (zie het tabblad Symbolen van het Voorbeeldbestand).
Via bovenstaande methode kunnen we zien dat deze de Unicode 207F heeft (een hexadecimaal getal). In cel J2 gebruiken we de Excel-formule Unicode om de code van het symbool in I2 op te halen. Het resultaat is nu 8319; dit is de decimale code.
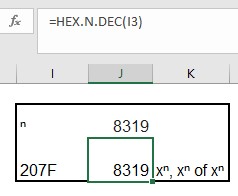
In cel J3 zien we dat dit klopt; hier is de hexadecimale code omgezet naar een decimaal getal met behulp van de Excel-formule Hex.n.dec.
In cel K3 gebruiken we 3 verschillende methoden om xn te schrijven: =”x”&UNITEKEN(J3)&”, x”&UNITEKEN(HEX.N.DEC(I3))&” of x”&I2
Op het tabblad Unicode van het Voorbeeldbestand ziet u een groot overzicht van allerlei symbolen met de daarbij behorende code.
Ook laten we daar zien hoe je symbolen in een Gegevensvalidatie gebruikt, inclusief het gebruik van de codes in een Voorwaardelijke opmaak.
Symbolen-5
Misschien nog wel de makkelijkste methode om symbolen in te voegen is kopiëren-plakken! Kijk of je ergens het gewenste symbool kunt vinden (bijvoorbeeld op www.vreemdetekens.nl) , selecteer het met de muis, Ctrl-C, ga naar de gewenste plaats in Excel en Ctrl-V.
Op het tabblad Symbolen hebben we deze methode gebruikt om een aangepaste getal-opmaak te definiëren in de kolommen N en O.
Symbolen-6
Als laatste een methode die overal in Windows werkt (vanaf Windows-10): druk de Windows-toets () in, hou vast en druk dan op de punt-komma-toets.
Onderstaande pop-up opent waarna u de beschikking hebt over een arsenaal aan nuttige (?) symbolen.
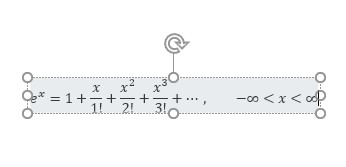
Excel kent ook een menu-optie Vergelijking; ook te vinden via de menutab Invoegen in het blok Symbolen. Achter het vinkje zit een serie standaard-formules. Fijn, maar het is wel een paar weken geleden dat ik een Fourier-reeks nodig heb gehad 😁.
Laten we maar aannemen dat ze als voorbeeld bedoeld zijn. Klik op één van deze voorbeelden en het resultaat komt in Excel terecht:
Via de hendels kunt u het formule-blok verschuiven, de grootte wijzigen en via de menutab Hulpmiddelen voor tekenen/Opmaak, die nu beschikbaar is gekomen, kunnen diverse opmaak-opties ingesteld worden. Wilt u de lettergrootte aanpassen? Gebruik de mogelijkheden in de menutab Start.
NB het lettertype wordt automatisch ingesteld op Cambria Math; dit is niet te wijzigen.
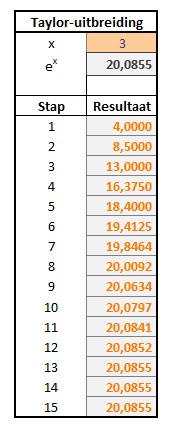
Op het tabblad Verg1 van het Voorbeeldbestand staan enkele standaard-formules. Ook hebben we daar even gecontroleerd of de Taylor-uitbreiding voor het berekenen van exwel klopt😉
De standaard-formules kunnen wel gebruikt worden als basis om andere formules te ‘schrijven’, want alle formules zijn nog aanpasbaar.
Vergelijkingen (handmatig)
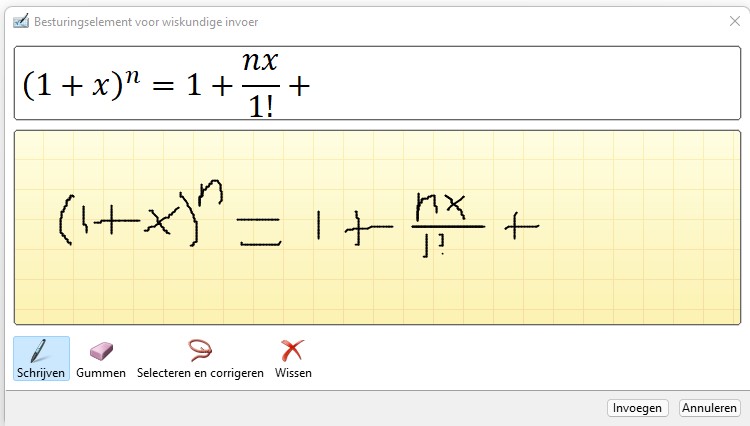
Over schrijven gesproken: je kunt de gewenste formule/vergelijking handmatig invoeren: kies in de menutab Invoegen in het blok Symbolen het vinkje achter Vergelijking. Helemaal onderaan staat dan de optie Handgeschreven vergelijking.
Met wat proberen, Gummen, Selecteren en corrigeren en opnieuw Schrijven kom je al snel een heel eind. Maar het lukte mij niet om de komma tussen de 1 en de 2 te krijgen; ook het extra streepje achter de a in de noemer kreeg ik niet weg.
Gelukkig: na het kiezen van Invoegen in de pop-up kan de door Excel gegenereerde formule nog gewijzigd worden:
Vergelijking (kwadratische formule)
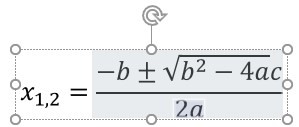
In de standaard-vergelijkingen van Excel komen ook de stelling van Pythagoras en de kwadratische formule voor (zie het tabblad Verg2 van het Voorbeeldbestand). De laatste wordt in het wiskundeonderwijs meestal de abc-formule genoemd.
In de standaardformule (rood omcirkeld) staat voor het =-teken alleen x. Meestal gebruiken we x1,2 om aan te geven dat er in principe 2 oplossingen zijn van een 2e graadsvergelijking; de eerste krijgen we door de + voor het wortelteken, de tweede door de wortel af te trekken van -b.
De ‘groene’ formule is veel beter leesbaar dan
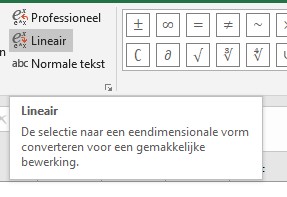
Dit is de zogenaamde Lineaire vorm (in tegenstelling tot de vorige die Professioneel wordt genoemd). Je kunt als volgt switchen tussen de twee verschijningsvormen
selecteer een formule door er op te klikken
er verschijnt een nieuwe menutab Hulpmiddelen voor vergelijkingen
klik daar op het tabblad Ontwerpen
in het blok Extra vooraan ziet u de 2 opties
Het voordeel van de Lineaire variant is, dat deze soms makkelijker te corrigeren is.
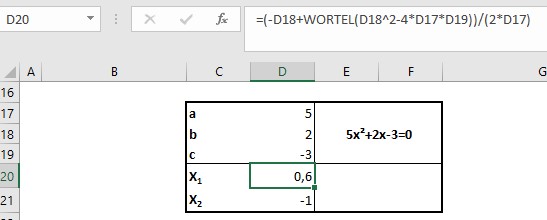
In het tabblad Verg2 gebruiken we de abc-formule om de oplossingen van 2e graadsvergelijkingen te vinden.
Wanneer we de cellen D17:D19 namen geven is de formule veel beter leesbaar: =(-b+WORTEL(b^2-4ac_))/(2*a)
NB voor cel D19 kunnen we niet de naam c gebruiken (een gereserveerde code voor Excel), vandaar de underscore erachter.
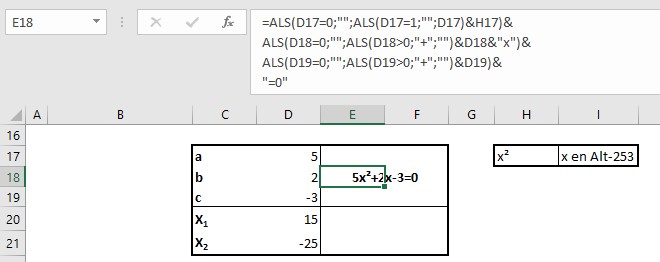
In de formule in E18 wordt gebruik gemaakt van de inhoud van cel H17. Deze bevat een x met het symbool 2 (Alt-253).
NB de overgangen naar een nieuwe regel in de formule zijn voor de leesbaarheid; druk op Alt-Enter.
Vergelijking (hypotheek)
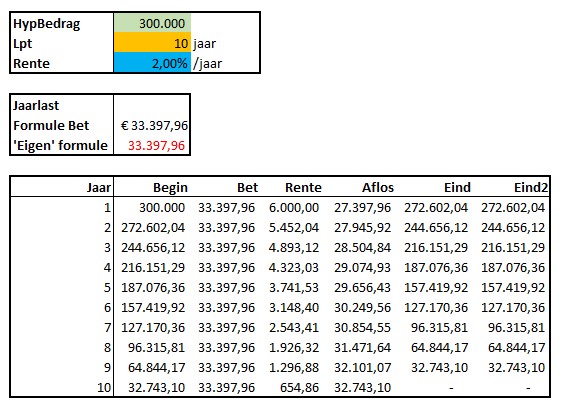
In het tabblad Hyp staat een voorbeeld van een hypotheekberekening. Excel kent daarvoor de standaard-functie Bet, maar zoals je hierboven kunt zien kun je ook een ‘eigen’ formule gebruiken.
Door gedeeltes van de toelichtende vergelijking dezelfde kleuren te geven als de overeenkomende cellen wordt snel het verband duidelijk:
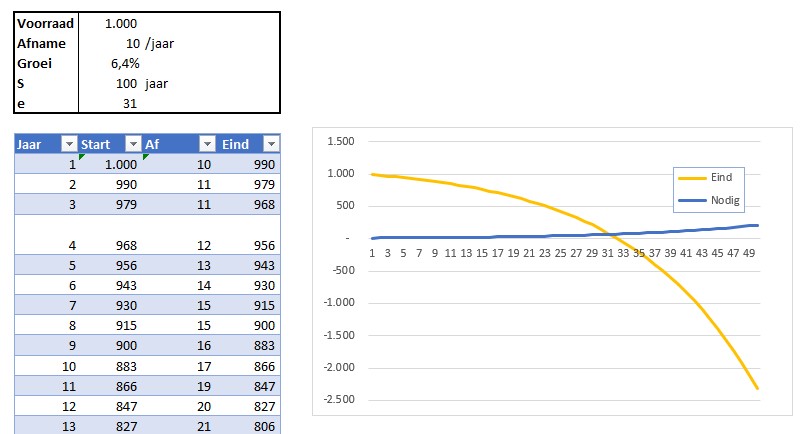
Grenzen aan de groei
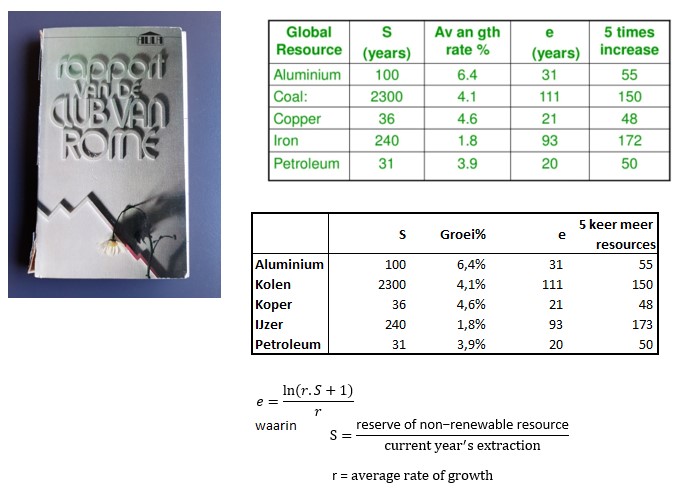
Een ander voorbeeld van een formule die je binnen de Office-onderdelen makkelijk kunt maken, komt uit het ‘rapport van de Club van Rome’.
Als je de voorraad van (in dit geval) grondstoffen weet en ook de hoeveelheid die je per jaar nodig hebt, dan weet je ook hoeveel jaar je nog vooruit kunt met die voorraad (de S hierboven). Maar een van de fundamentele bijdrages van de ‘club’ aan de discussie was om ook rekening te houden met de groei van de behoefte. Dit levert het aantal jaren op dat je werkelijk vooruit kunt (e). Deze is vaak dramatisch lager dan de S!
In het tabblad Groei van het Voorbeeldbestand is het effect van de groei van de behoefte grafisch weergegeven.
Binnenkort eens kijken of we de andere variabelen uit het model ook kunnen vinden, inclusief de aannames die daar zijn gebruikt. Dan kunnen we proberen het model in Excel na te bouwen.
Technologie
Nog maar even verder op de nostalgische tour. Tijdens mijn studie op de THE kregen we een handboekje (voor ƒ 1,00). Vol met interessante formules en grafieken.
Laten we de formule voor het Reynolds-getal eens gaan opbouwen (zie het tabblad Technologie van het Voorbeeldbestand):
kies in de menutab Invoegen in het blok Symbolen de optie Vergelijking (dus NIET op het vinkje erachter klikken). Een blok met Typ hier uw vergelijking komt tevoorschijn in het midden van het scherm.
tik in Re=
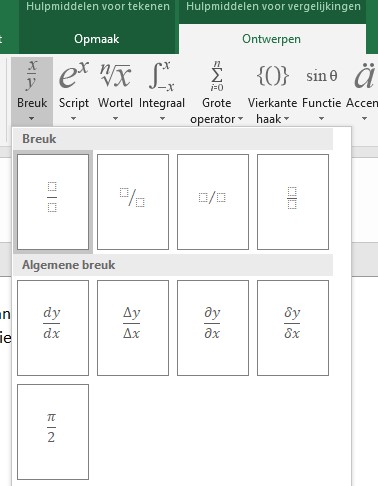
nu moet er een breuk komen: klik in de menutab Ontwerpen in het blok Structuren op het vinkje onder Breuk
we kiezen de eerste breuk, waarbij de gestippelde vierkantjes aangeven dat daar nog iets ingevuld kan worden
selecteer het vierkantje in de teller en klik op het knopje Meer, rechtsonder bij Symbolen. Kies daar de ρ(Griekse letter rho).
de rest van de teller is dan eenvoudig; tik in .U.2m
selecteer het vierkantje in de noemer en klik op het knopje Meer, rechtsonder bij Symbolen. We hebben de η (eta) nodig; die is niet te vinden bij Elementaire wiskunde. Kies rechtsboven bij Symbolen de optie Griekse letters en zoek de juiste letter.
klik ergens buiten het formuleblok.
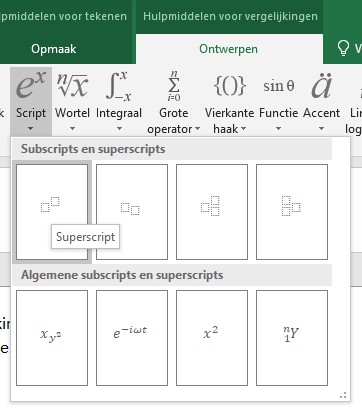
LET OP als je een formule gaat opbouwen zorg dan dat je elke keer goed vooruitkijkt. Zoals hiervoor bij het maken van een breuk moet je eerst de breuk-optie kiezen waarna je dan pas de teller en noemer kunt invullen. Wil je x2 tikken, kies dan eerst optie één binnen Script en vul dan de twee vierkantjes met de x en de 2 (of selecteer de 7e optie natuurlijk!).
NB door te switchen naar Lineair (zie hierboven) is het mogelijk om bijvoorbeeld een vergeten breuk te corrigeren door achter de bestaande formule een / te plaatsen. Ga daarna weer naar Professioneel.
Het vergt wat onderzoek om alle mogelijkheden voor het maken van formules te doorgronden. Zelfstudie is zeer noodzakelijk. Zoals eerder gezegd werkt het in de praktijk prima om eerst ‘met de hand’ zo goed mogelijk de formule te schrijven en dan met de Excel-hulpmiddelen zo nodig nog aanpassingen door te voeren.
Afstudeerscriptie
Naar aanleiding van de voorgaande voorbeelden herinnerde ik me dat mijn afstudeerscriptie (van 1978) vol stond met formules, die gedeeltelijk met een typemachine en gedeeltelijk met de hand moesten worden gemaakt (zie hiernaast).
Wanneer er ergens iets fout was (of er moest nog wat tekst tussen) dan moest zo’n pagina opnieuw. Soms kon je gelukkig volstaan met letterlijk knippen en plakken.
In het tabblad Menging van het Voorbeeldbestand heb ik het belangrijkste resultaat van mijn onderzoek nog eens nagebouwd. Binnen een paar minuten was dat gebeurd, terwijl dat toen op een typemachine heel wat meer tijd kostte.
En een correctie doorvoeren is een fluitje van een cent.
Op het tabblad Menging is ook te zien dat het schrijven van een differentiaal-vergelijking niets meer voorstelt; bovenaan staat een stukje uit mijn afstudeerscriptie, daar onder een Excel-formule.
Jammer dat ik nu nooit meer iets van doen heb met differentiaalvergelijkingen😉
Iedereen maakt het wel eens mee dat Excel ineens een melding geeft dat er een Kringverwijzing is gesignaleerd.
Wat betekent dat? Hoe weet je of er Kringverwijzingen zijn? Hoe los je het op? En kunnen we kringverwijzingen zinvol toepassen in de praktijk? Om de laatste vraag alvast te beantwoorden: jazeker, en dat noemen we dan Iteraties.
Kringverwijzing
Soms gebeurt het ineens: ben je ijverig bezig een mooie spreadsheet in elkaar te zetten, krijg je ineens de volgende melding:
Deze melding kun je ook krijgen als je een bestaande spreadsheet opent.
De uitleg in de melding maakt wel duidelijk wat er aan de hand is: een formule in een cel verwijst naar deze cel zelf (direct of indirect). Excel weet dan niet wat ie moet doen: 1 keer berekenen of, als dat resultaat is berekend, nog een keer? En daarna nog een keer? In de standaard-instelling (waarbij Excel alles automatisch herberekent) stopt de berekening en is het resultaat van de formule gelijk aan 0.
Wanneer Excel een kringverwijzing tegenkomt dan wordt dit zichtbaar in de status-balk onder aan het Excel-venster.
LET OP1 ook al staat er in de statusbalk maar één cel, er kunnen meerdere kringverwijzingen in het spreadsheet voorkomen.
LET OP2 als er kringverwijzingen zijn dan moet je normaal gesproken deze direct oplossen; ALLE resultaten van berekeningen zijn daardoor onbetrouwbaar.
Een paar voorbeelden (zie het tabblad Kring van het Voorbeeldbestand):
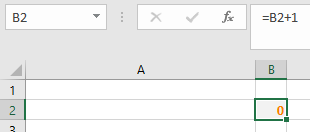
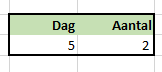
In cel B2 staat de formule =B2+1.
Er staat nu de waarde 0, dus het resultaat zou dan 1 moeten zijn. Maar als er 1 staat in de cel, dan wordt het resultaat van de formule 2 enzovoort. Meestal betekent dit dat er naar een verkeerde cel wordt verwezen of dat de formule in de verkeerde cel wordt geplaatst. De oplossing is simpel: pas de verwijzing in de formule aan of verplaats de formule.
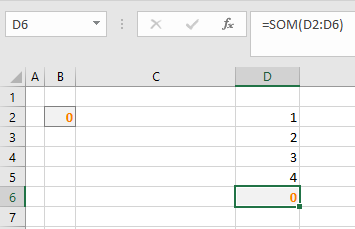
Een vaker voorkomende fout bij het maken van een spreadsheet: in de verwijzing in een Som-formule wordt ook verwezen naar de cel, waarin de formule staat (in het voorbeeld hiernaast D6). Oplossing: zorg dat de verwijzing in de formule naar de juiste cellen verwijst.
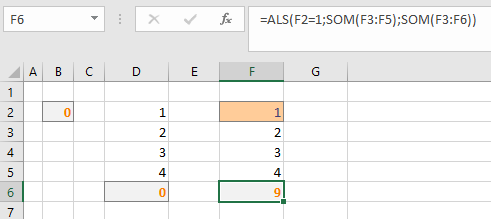
We kennen ook een zogenaamde verborgen kringverwijzing; deze zijn soms moeilijker op te sporen omdat deze niet altijd optreden. In het voorbeeld hiernaast staat in cel F6 een formule die afhankelijk van de waarde in F2 twee verschillende berekeningen uitvoert. Als F2 de waarde 1 bevat kan Excel de berekening gewoon uitvoeren en zal dan ook niets melden; bevat die cel echter een andere waarde dan wordt de tweede berekening uitgevoerd en dan ontstaat er wel een kringverwijzing. Oplossing: zorg dat de verwijzing in de formule naar de juiste cellen verwijst.
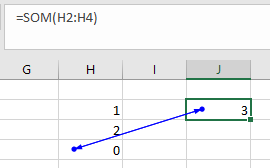
Een voorbeeld van een indirecte kringverwijzing: in cel J2 staat een verwijzing naar de cellen H2:H4. Niets geks. Behalve als we kijken naar de inhoud van cel H4: =SOM(H2:J3), dus hierbij wordt ook impliciet verwezen naar de cel J2.
Dit soort fouten zijn vaak moeilijker te achterhalen. Maar gelukkig helpt Excel ons door een lijntje tussen de 2 cellen te tekenen. Dubbelklik hierop en Excel toont afwisselend de inhoud van de 2 betrokken cellen.
Toepassing Kringverwijzing
Zoals gezegd: meestal duidt het optreden van kringverwijzingen er op, dat er ergens in één of meer formules fouten staan. Maar soms wil je bewust gebruik maken van dit fenomeen.
Eigenlijk overal waar een eindstand van een periode weer gebruikt wordt als input voor de berekeningen in de volgende periode zouden we kringverwijzingen kunnen tegenkomen/gebruiken.
Bijvoorbeeld wanneer we het verloop van een hypotheek in de tijd willen berekenen, zullen we de schuldrest op het einde van de maand gebruiken om de rente en aflossing van de volgende maand te berekenen. Daardoor kennen we weer de schuldrest op het einde van die periode . Deze gebruiken we dan weer als input voor de volgende maand etc.
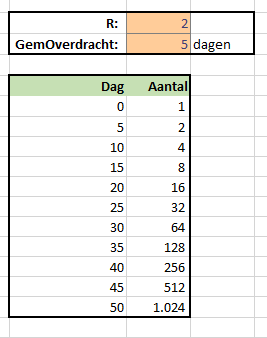
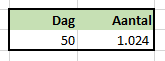
Een simpeler voorbeeld staat op het tabblad Corona van het Voorbeeldbestand . De berekening kent twee input-variabelen: de zogenaamde R en het gemiddeld aantal dagen dat het duurt om een besmetting over te dragen. Bij een R=2 en het aantal dagen=5 ligt, wanneer we op dag 0 met 1 besmetting starten, na 50 dagen het daaruit voorkomende aantal besmettingen al boven de 1.000.
In dit flink versimpelde model bepalen we het aantal besmettingen op het einde van een periode door de stand van de vorige periode te vermenigvuldigen met R.
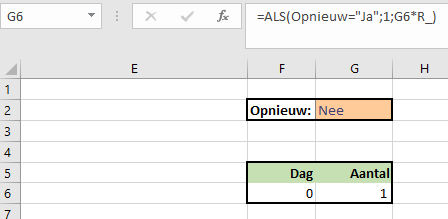
Als we niet geïnteresseerd zijn in de tussenresultaten zouden we het eindresultaat (in het voorbeeld in cel G6) ook kunnen berekenen door het het vorige resultaat in die cel te vermenigvuldigen met de R-waarde. Helaas: Excel voert die berekening normaal gesproken niet uit, want er ontstaat daar een kringverwijzing (zie op de statusbalk linksonder). En als die het wel zou kunnen/willen berekenen: wanneer moet die stoppen? Na 10 keer zoals in de berekening hiervoor of na 20 of na ???
NB1 in cel F6 staat de berekening =F6+GemOvDgn, dus ook daar ontstaat een kringverwijzing.
NB2 er ontstaan geen kringverwijzingen wanneer Opnieuw (de waarde in cel G2) gelijk is aan Ja. Dit gebruiken we om ons model op een standaard-waarde in te stellen (zie hierna).
We gaan de Excel-omgeving aanpassen zodat we de berekening in G6 WEL kunnen uitvoeren:
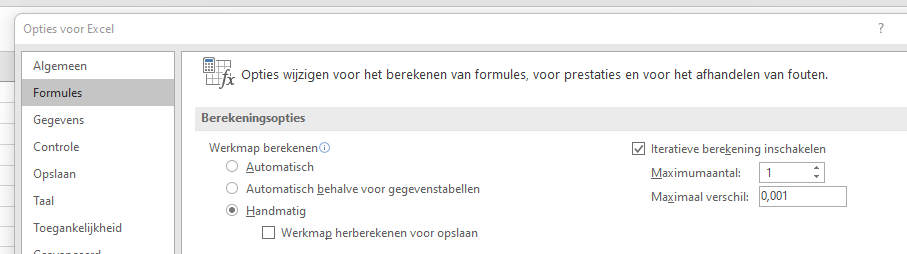
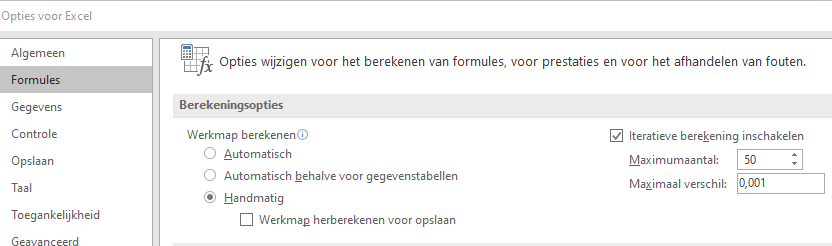
kies in de menutab Bestand de button Opties
klik op Formules en vul de Berekeningsopties in zoals hieronder, dus op handmatig berekenen en Iteratieve berekeningen inschakelen:
klik op OK
Nu kunnen we gaan rekenen:
vul cel G2 met de waarde Ja
we hebben Excel op Handmatig berekenen gezet, dus druk op F9 of klik onderaan in de statusbalk op Berekenen
geef cel G2 de waarde Nee
en kies opnieuw Berekenen:
telkens wanneer we herberekenen, verandert het resultaat:
wil je opnieuw beginnen? Vul cel G2 met de waarde Ja, wijzig eventueel de R en het aantal dagen in kolom C, vul G2 met Nee en kies Herberekenen zoals in stap 2.
NB in de Berekeningsopties hebben we het aantal Iteraties op 1 gezet. Iedere keer wanneer we herberekenen, gaat Excel dus alle cellen één keer langs om formules in die cellen te berekenen. Zet je het aantal Iteraties hoger dan voert Excel de berekeningen dat aantal keren achter elkaar uit.
LET OP vergeet niet de Berekeningsopties weer op Automatisch berekenen te zetten wanneer je met een ander spreadsheet aan de slag gaat!
Game of life
Het vorige voorbeeld laat goed de werking van Kruisverwijzingen/Iteraties zien. Een ander bekend (en zinvoller) voorbeeld is Conway’s Game of Life.
De Britse wiskundige Conway bedacht dit ‘spel’ in 1970 om de groei van een organisme na te bootsen, gebaseerd op het werk van John von Neumann.
In een 2-dimensionaal rooster heeft iedere cel óf de waarde Bewoond óf de waarde Onbewoond. Voor elke levenscyclus is iedere cel afhankelijk van de status van zijn 8 buren:
iedere bewoonde cel met minder dan 2 bewoonde buren sterft (onderbevolking)
iedere bewoonde cel met 2 of 3 bewoonde buren blijft bewoond
iedere bewoonde cel met meer dan 3 bewoonde buren sterft (overbevolking)
iedere onbewoonde cel met precies 3 bewoonde buren wordt bewoond (reproductie)
Hiernaast zie je de ‘vertaling’ van een patroon naar het aantal buren.
Om het ‘levenspel’ in Excel te implementeren maken we de volgende afspraken:
voor het Conway-rooster gebruiken we natuurlijk het raster van een tabblad
waar Conway een oneindig groot rooster gebruikt, beperken we ons tot 30 rijen en 40 kolommen
in een ‘bewoonde’ cel plaatsen we een 1, anders een 0
via Voorwaardelijke opmaak vullen we een bewoonde cel met een groene kleur, anders wordt de cel wit
Om iedere levenssstap na te bootsen vertalen we de Conway-regels in een formule:
eerst als een cel bewoond is: als het aantal bewoonde buren 0 of 1 is dan wordt de cel 0, als dat aantal 2 of 3 is dan blijft de cel 1, anders wordt de cel 0. In een Excel-formule: KIEZEN(buren+1);0;0;1;1;0;0;0;0;0) NB de laagste waarde van de eerste parameter moet 1 zijn, dus we verhogen het aantal buren met 1. Iets compacter: KIEZEN(MIN(5;buren+1));0;0;1;1;0)
als we te maken hebben met een onbewoonde cel:ALS(buren=3;1;0)
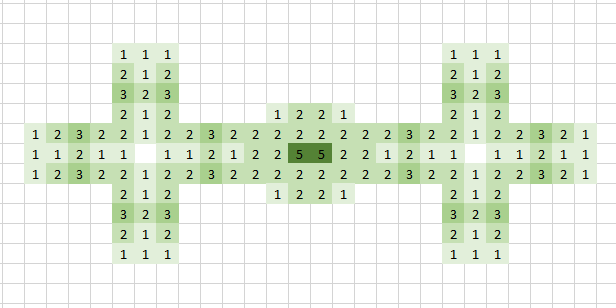
In het tabblad 1.Game van het Voorbeeldbestand staat een implementatie van het spel.
De bewoonde buren van een cel liggen vast in een ander tabblad (2.Buren).
Het aantal bewoonde buren van bijvoorbeeld cel E6 in het tabblad 1.Game liggen vast in cel E6 van het tabblad 2.Buren.
De gecombineerde formule hierboven wordt dan voor cel E6: =ALS(E6=1;KIEZEN(MIN(5;.’2.Buren’!E6+1);0;0;1;1;0);ALS(‘2.Buren’!E6=3;1;0))
Nu zijn we er bijna: we moeten ook nog een start-situatie kunnen vastleggen.
Cel C2 (met de naam Reset) geven we een waarde WAAR als we het rooster in de begin-situatie willen krijgen; we passen daarom de formules in het rooster aan: =ALS(Reset;Basis!E6;ALS(E6=1;KIEZEN(MIN(5;’2.Buren’!E6+1);0;0;1;1;0);ALS(‘2.Buren’!E6=3;1;0))) en leggen de gewenste begin-situatie in het tabblad Basis vast.
NB1 om het systeem te resetten kun je ook een vinkje plaatsen in het hokje in kolom E; dit selectievakje is gekoppeld aan cel E2.
NB2 och ja, vergeet niet de Berekeningsopties aan te passen zoals hierboven beschreven en het spreadsheet handmatig te herberekenen door bijvoorbeeld F9 in te drukken.
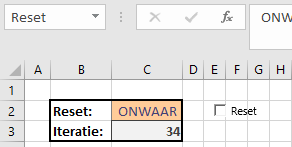
NB3 cel C3 (met de naam Iteratie) bevat een teller voor het aantal uitgevoerde iteraties vanaf een reset: =ALS(Reset;0;Iteratie+1)
Voorbeeld-run (zorg dat de Berekeningsopties goed staan):
vul de Reset-cel met de waarde WAAR (of vink het selectievakje aan)
herbereken het spreadsheet (F9 of Berekenen in de statusbalk aanklikken)
vul de Reset-cel met de waarde ONWAAR (of vink het selectievakje uit)
herbereken het spreadsheet (F9 of Berekenen in de statusbalk aanklikken)
herhaal stap 4 zo vaak als gewenst (dit is het resultaat na 6 iteraties)
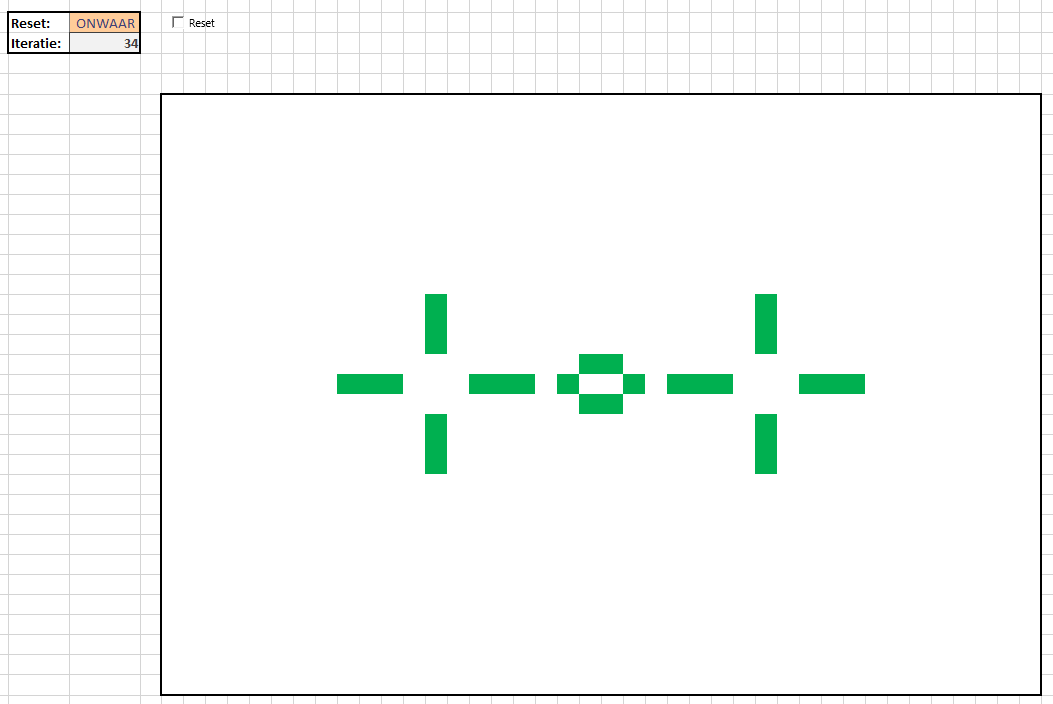
Na 13 iteraties ziet het scherm er zo uit:
maar na 18 iteraties blijft een zogenaamde oscillator over: <–>
NB1 dit voorbeeld eindigt in een 2-periode oscillator. Veel andere voorbeelden eindigen in een stabiele situatie (start bijvoorbeeld met een rijtje van 12 bewoonde cellen) of een leeg rooster (start met een rijtje van 6). Soms ontdek je een Life-game dat zich maar blijft ontwikkelen.
NB3 Het rooster in het tabblad 1.Game (en alle anderen) is redelijk beperkt (30 x 40) maar voldoet voor de meeste bekende voorbeelden. Een mogelijke verbetering: pas op het tabblad 2.Buren de formules op de grenzen aan; vervang verwijzingen naar cellen buiten het rooster door verwijzingen naar cellen op de grens aan de andere kant van het rooster.
In het Voorbeeldbestand staan nog diverse tabbladen met mogelijke start-posities; de namen daarvan beginnen met Basis. Kopieer het rooster daaruit naar het tabblad Basis en herstart een run zoals hiervoor beschreven.
Wanneer je het tabblad Basis450 gebruikt zul je zien dat het heel lang duurt voordat er een stabiele situatie ontstaat. In dit soort gevallen is het handig om eerst het aantal iteraties per herberekeningsronde te verhogen in de Berekeningsopties:
NB In dit systeem hebben we gebruik gemaakt van de volgende werking van Excel: het herberekenen van cellen begint op het eerste tabblad, daarna het tweede etc. Dus pas als alle berekeningen op het tabblad 1.Game zijn uitgevoerd, worden de cellen van het tabblad 2.Buren berekend.
Op de site van G-Info hebben we het al heel vaak gehad over allerlei methoden om met Excel gegevens te analyseren.
Uit alle vragen die we krijgen blijkt dat de meeste mensen daarbij worstelen met Voorwaardelijke opmaak, grafieken en draaitabellen. Daar hebben we dan ook al diverse keren aandacht aan besteed.
Waar we het nog niet over hebben gehad, is dat je Excel vaak automatisch het (voor)werk kunt laten doen! Microsoft heeft (vanaf versie 2013) een optie ingebouwd, die ze Snelle Analyse genoemd hebben. Naar mijn idee zijn ze daarbij eigenlijk te bescheiden: ik zou dat eerder Zeer snelle analyse met heel erg veel mogelijkheden hebben genoemd, maar dat is natuurlijk wat lang in een menu 😉
De diverse resultaten van Snelle analyse kunnen nog handmatig naar wens worden aangepast; ook kan het een goede start zijn om de diverse onderdelen van Excel die daarbij gebruikt worden, beter te begrijpen.
Basis-gegevens
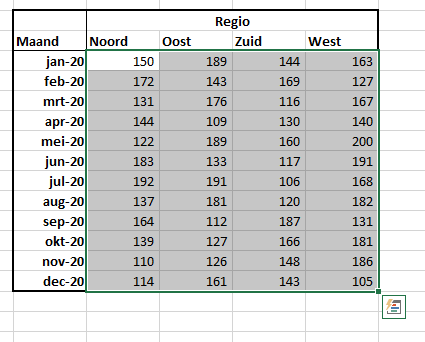
In het Voorbeeldbestand staat op het tabblad Data een blokje gegevens dat we in dit artikel zullen gebruiken om te laten zien hoe snel (en goed!) Snelle Analyse werkt.
De getallen worden door de functie ASELECTTUSSEN bij iedere wijziging in de werkmap (of na het drukken op F9) opnieuw gegenereerd. Het effect daarvan zie je dan direct in de verschillende analyses terug.
Snelle analyse starten
Selecteer je in Excel meer dan één cel tegelijk dan zie je rechtsonder bij die selectie de button Snelle analyse tevoorschijn komen. Zoals je kunt zien kun je ook de toetscombinatie Ctrl-Q gebruiken.
NB de button komt alleen tevoorschijn als je aaneengesloten cellen selecteert.
Klik je op de button dan verschijnt het Snelle analyse-menu:
Je kunt dus op 5 manieren je gegevens analyseren: met Opmaak (beter gezegd Voorwaardelijke opmaak), door middel van Grafieken, door automatisch Totalen (en andere statistieken) toe te laten voegen, door het gebruik van Tabellen (inclusief draaitabellen) of met Sparklines.
De mogelijkheden binnen deze opties kunnen afhankelijk zijn van de geselecteerde cellen.
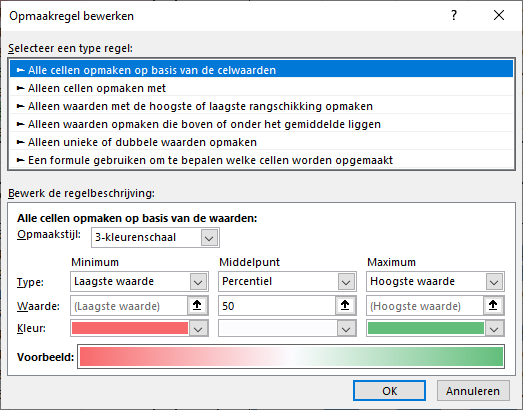
Opmaak
De (voorwaardelijke) opmaak willen we alleen toepassen op de getallen in het overzicht. Dus selecteer eerst de cellen met die getallen en klik dan op de Analyse-button (of druk op Ctrl-Q). De Opmaak-optie is al geselecteerd. Wanneer je nu met de muis over de 6 verschillende menu-keuzes gaat zie je direct het resultaat daarvan in de brongegevens.
Wanneer je de opmaak daadwerkelijk aan je gegevens wilt toevoegen dan moet je op de betreffende keuze klikken (zie het tabblad Opmaak van het Voorbeeldbestand). Ook kun je een combinatie van voorwaardelijke opmaak toevoegen door meerdere keuzes achter elkaar te maken. Wil je de opmaak verwijderen kies dan de laatste optie in het Opmaak-menu.
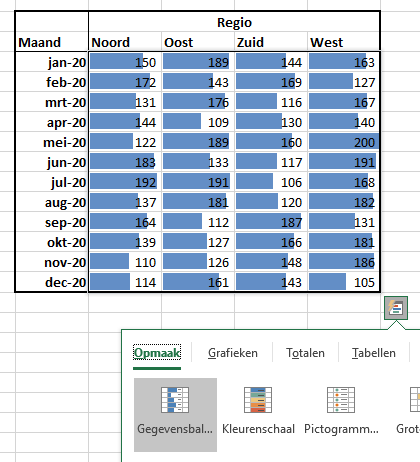
Gegevensbalk
Via de eerste keuzemogelijkheid worden Gegevensbalken aan de geselecteerde cellen toegevoegd. Hierdoor krijg je snel inzicht in hoe de getallen zich ten opzichte van elkaar verhouden.
NB Excel zal om de lengte van de gegevensbalken te maken alle getallen uit de geselecteerde cellen vergelijken. Wil je dat Excel per kolom (of rij) de waardes vergelijkt dan moet je de opmaak voor iedere kolom (of rij) apart instellen.
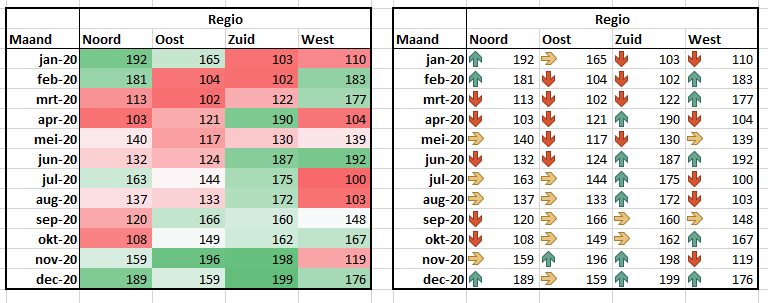
Kleurschalen en Pictogrammen
Ook via de opties Kleurschalen en Pictogrammen kun je de onderlinge verhoudingen van de geselecteerde getallen zichtbaar maken.
NB de voorwaardelijke opmaak kan nog naar wens worden aangepast:
selecteer één van de cellen met opmaak
kies in de menutab Start in het blok Stijlen de optie Voorwaardelijkeopmaak
kies Regels beheren….
kies Regel bewerken
pas de diverse opties naar wens aan
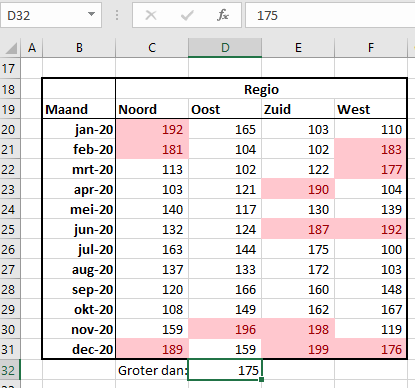
Groter dan
Door middel van de vierde opmaak-optie kun je getallen die groter zijn dan een bepaalde waarde een opmaak meegeven.
Kies je deze mogelijkheid dan moet je een grenswaarde opgeven; in het voorbeeld verwijzen we daarbij naar cel D32. Door deze cel te wijzigen zal de opmaak zich automatisch aanpassen.
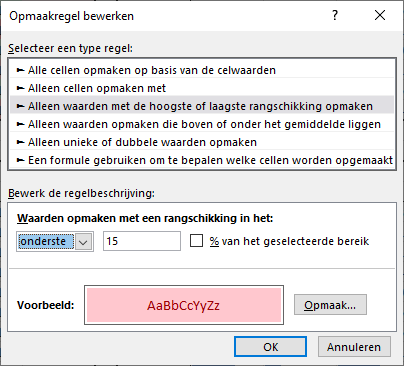
Bovenste 10%
Deze optie spreekt voor zich. De cellen die waarden bevatten die bij de hoogste 10% horen worden gemarkeerd.
Door de opmaak-regel aan te passen kun je ook een heel ander gedeelte van de getallen een opmaak geven:
Opmaak wissen
Met de 6e keuzemogelijkheid kun je bestaande opmaak wissen.
NB op het tabblad Opmaak van het Voorbeeldbestand staan ‘gewone’ Excel-overzichten. Wanneer je deze uitbreidt met nieuwe gegevens moet je de opmaak zelf nog aan die nieuwe gegevens toevoegen. In het tabblad Opmaak2 staan dezelfde overzichten, maar dan in de vorm van een Excel-tabel. Als je daar gegevens toevoegt, krijgen de nieuwe gegevens automatisch de bijbehorende opmaak.
Grafieken
Grafieken worden veel gebruikt als rapportagetool, maar kunnen ook een goed analyse-hulpmiddel zijn.
Met Snelle analyse is een grafiek maken een fluitje van een cent:
voor een grafiek hebben we niet alleen de getallen nodig maar ook de omschrijvingen daar omheen.
selecteer alle benodigde cellen en klik op de button Snelle analyse of selecteer één van de cellen met getallen en druk op Ctrl-Q
klik in het submenu op de optie Grafieken en ga met de muis over de voorgestelde grafieken. Welke dit zijn is afhankelijk van de brongegevens.
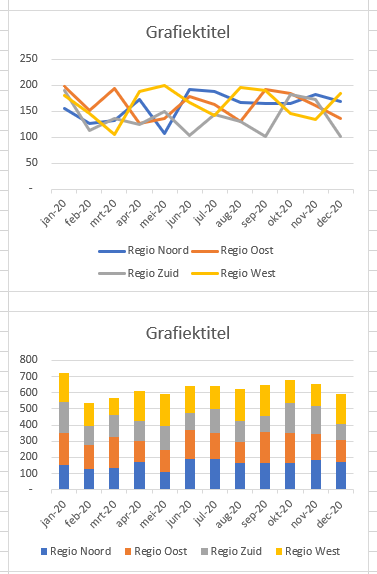
Klik op een van de grafieken, et voilà! Zie het tabblad Grafieken van het Voorbeeldbestand.
Komen er nieuwe gegevens bij, dan zul je óf de de brongegevens van de grafiek moeten aanpassen (rechtsklikken op de grafiek en Gegevens selecteren kiezen) óf de grafiek op bovenstaande manier opnieuw moeten maken.
Dat kun je ondervangen door de brongegevens als Excel-tabel vast te leggen (zie het tabblad Grafieken2 van het Voorbeeldbestand). Helaas, dan werkt het selecteren van de gegevens met Ctrl-Q niet goed. Doe dan het volgende:
selecteer één van de cellen met getallen en druk op Ctrl-A
maar we hebben ook de kopregel nodig; druk nogmaals op Ctrl-A
druk dan Ctrl-Q of kies de Snelle analyse-button.
Totalen
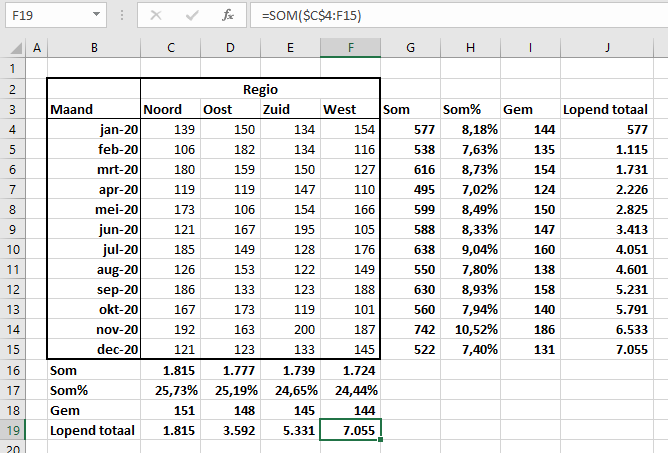
we willen natuurlijk alleen van de getallen in het binnenblok de totalen berekenen (en bijvoorbeeld niet van de datums ook al zijn dat voor Excel ook getallen); dus selecteer de cellen C4:F15 (zie het tabblad Totalen van het Voorbeeldbestand)
druk op Ctrl-Q of klik op de analyse-button
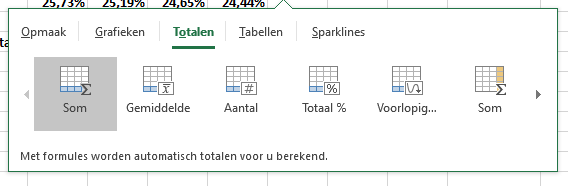
kies de optie Totalen en klik op de gewenste functie (Som, Gemiddelde, Aantal, Totaal % of Voorlopig …)
Excel plaatst formules onder het geselecteerde blok getallen en voert daarmee de gewenste berekening uit.
NB1 zijn de cellen onder de selectie niet leeg, dan krijg je een waarschuwing of je deze wilt overschrijven. Wil je deze gegevens bewaren maak dan eerst ruimte door een lege regel in te voegen voordat je bovenstaande handelingen uitvoert.
NB2 bij de eerste 5 opties is een regel blauw gekleurd; dit betekent dat Excel de formules onderaan in een regel plaatst (en totalen per kolom bepaalt). De 6e optie (en verder, klik op het pijltje aan de rechterkant) laten een gekleurde kolom zien. Als je die optie gebruikt zal Excel formules aan de rechterkant plaatsen en dus totaalberekeningen over de rij uitvoeren.
NB3 Excel plaatst formules in het tabblad. Deze zijn zodanig opgezet dat bij het toevoegen van nieuwe gegevens de berekeningen met een paar kleine aanpassingen weer kloppen.
Lopend totaal
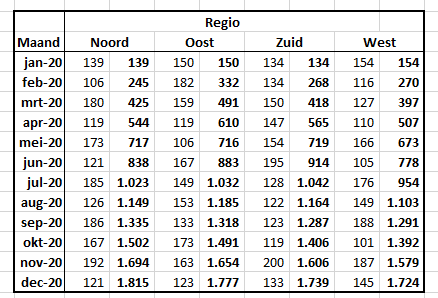
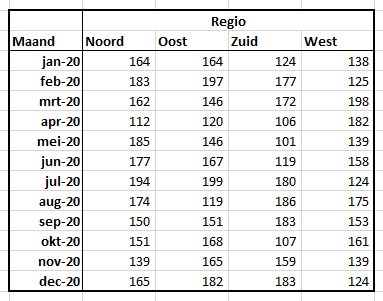
In rij 19 staat een formule die het lopend totaal bepaalt (in Excel wordt deze analyse-optie met Voorlopig … aangeduid). In cel C19 staat het totaal van de regio Noord, in D19 het totaal van Noord én Oost etc.
In kolom J staat een lopend totaal over alle regio’s. Wil je per regio een lopend totaal dan moet je eerst tussen C en D een nieuwe kolom invoegen, de gegevens van kolom C selecteren en dan het lopend totaal invoegen. Doe dat ook voor de andere kolommen; zie het tabblad Totalen:
NB plaats je de gegevens in een Excel-tabel dan zien de ingevoegde formules er heel anders uit (zie het tabblad Totalen2 van het Voorbeeldbestand). Bij het toevoegen van nieuwe gegevens hoeft dan niets (of veel minder) aan de formules gewijzigd te worden.
Tabellen
Met de eerste keuze binnen de analyse-optie Tabellen wordt een gewoon bereik van cellen omgezet naar een Excel-tabel. Maar ik gebruik die (bijna) nooit; die optie kennen we al via Invoegen of door Ctrl-L te tikken.
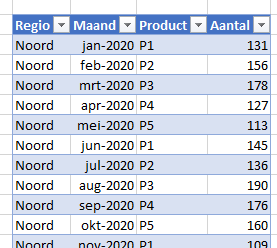
In het tabblad Tabellen van het Voorbeeldbestand is het gebruikte bronbestand omgezet naar een database-vorm; dit om de mogelijkheden van een draaitabel makkelijker te benutten.
Per combinatie van kenmerken (Regio, Maand en Product) wordt het Aantal vastgelegd.
selecteer één van de cellen in de Excel-tabel en druk op Ctrl-Q
kies de analyse-optie Tabellen
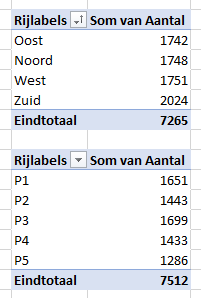
op basis van deze brongegevens stelt Excel 2 draaitabellen voor: Som van Aantal per regio en per product
klik op één van de 2 mogelijkheden (of de 3e om zelf een draaitabel te maken)
NB de 2 draaitabellen zijn gebaseerd op dezelfde brongegevens maar laten ieder een ander totaal zien! Dit is een inconsistentie binnen Excel. Maak je zelf verschillende draaitabellen op basis van dezelfde brongegevens dan worden alle draaitabellen tegelijkertijd vernieuwd. Zijn de draaitabellen via Snelle analyse aangemaakt dan moet iedere draaitabel afzonderlijk vernieuwd worden. Maar dan worden de brongegevens tussentijds aangepast door de Aselect-formule.
Op het tabblad Tabellen staat ook een draai-grafiek; deze is gemaakt op basis van de gegevens in de eerste kolommen door in de analyse-optie een grafiek te kiezen met het -teken.
Sparklines
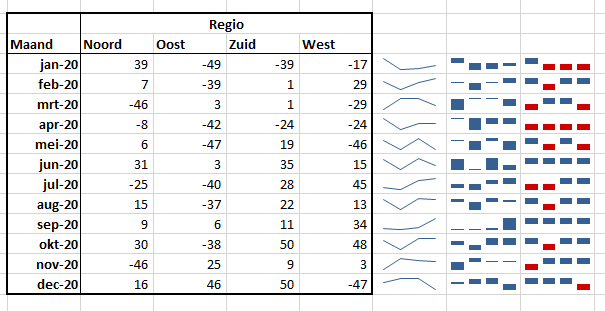
Niets nieuws meer onder zon: selecteer alle cellen met getallen (dus niet de maanden en de kopregels), Ctrl-Q, kies de optie Sparklines en klik op één van de drie mogelijkheden (zie het tabblad Sparklines in het Voorbeeldbestand).
Het eerste type sparkline laat het globale verloop als lijngrafiek zien, de tweede globaal het verloop als kolomgrafiek en de derde (Winst/verlies) laat alleen maar zien of het resultaat positief of negatief is.
NB1 het uiterlijk van de sparklines kan makkelijk aangepast worden: klik op een cel die een sparkline bevat en kies bij Hulpmiddelen voor sparklines de optie Ontwerpen.
NB2 of je nu met een bereik van cellen werkt of met een Excel-tabel (zie het tabblad Sparklines2 van het Voorbeeldbestand), bij het uitbreiden van gegevens zul je de sparklines ook moeten aanpassen (of opnieuw maken). Het aanpassen gaat simpel door de vulgreep rechtsonder in de onderste cel met een sparkline naar beneden te trekken.









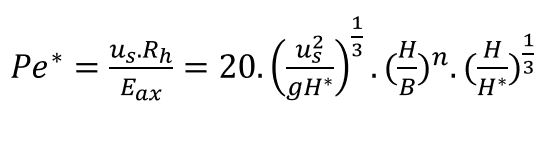





 ) in, hou vast en druk dan op de punt-komma-toets.
) in, hou vast en druk dan op de punt-komma-toets.

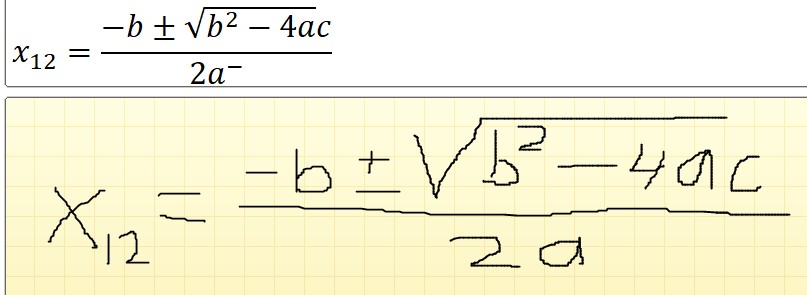

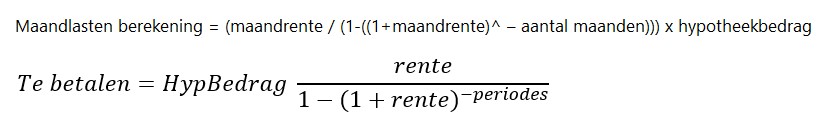
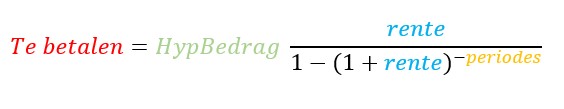






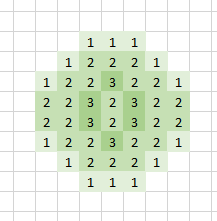

 (dit is het resultaat na 6 iteraties)
(dit is het resultaat na 6 iteraties)
 <–>
<–> 


 kun je bestaande opmaak wissen.
kun je bestaande opmaak wissen.