Vorige week werd duidelijk dat het bedrag aan belastingkorting voor de fossiele industrie in Nederland, vaak ook fossiele subsidies genoemd, veel groter is dan tot nu gedacht/ berekend.
(Foto: Joris van Gennip voor de Volkskrant)
Milieudefensie e.a. hebben op basis van een internationale definitie, opgesteld door de Wereldhandelsorganisatie (WHO), een nieuwe berekening gemaakt. De Nederlandse overheid hanteert dezelfde definitie en methodologie.
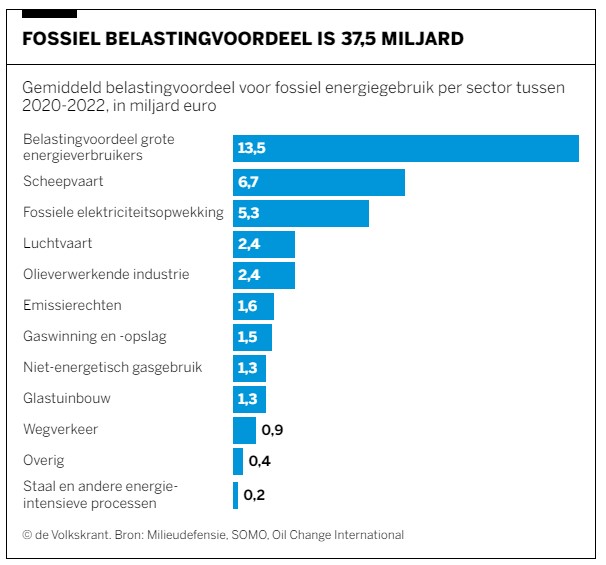
De totale omvang van de subsidies (een gemiddelde over de jaren 2020-2022) wordt in het betreffende rapport geraamd op ruim 37,5 miljard euro per jaar.
Bij bestudering van de onderliggende cijfers moeten we echter constateren, dat dit bedrag zelfs nog te laag is. Na correctie van een foutieve berekening komen we uit op een totaal van € 38,2 mld.
Hierna zullen we eens kijken naar de gehanteerde methode, de fout in de berekening en hoe je snel enkele soorten grafieken kunt maken die inzicht geven in de verhouding tussen de diverse soorten “subsidies”.
Basis-gegevens

In het tabblad Docu van het Voorbeeldbestand ziet u enkele verwijzingen naar onderliggende documenten. Via de derde link kunt u een spreadsheet downloaden met daarin op detailniveau de gehanteerde berekeningen en bronnen. Transparanter kan niet!
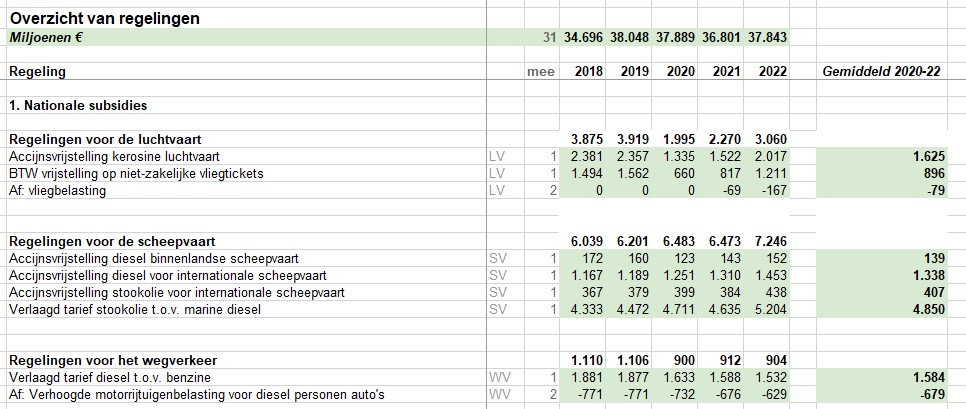

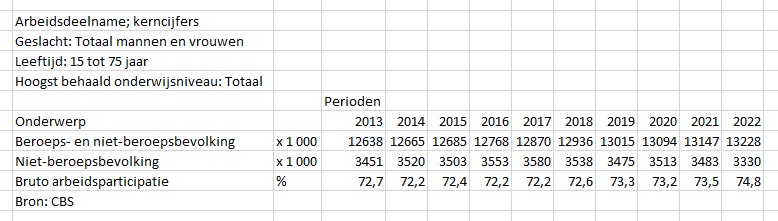
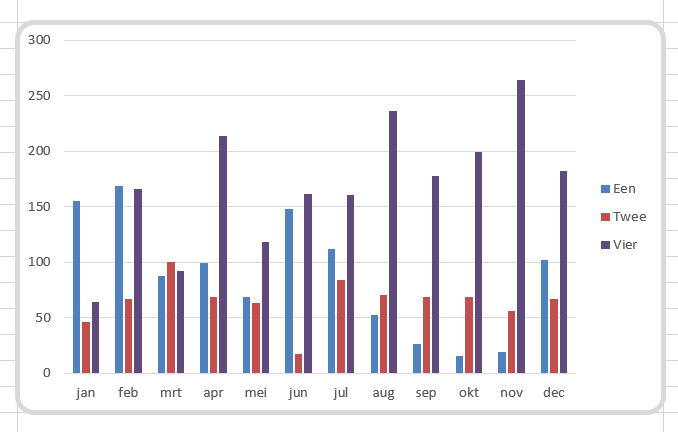
De gemiddelden over 2020-22 uit dit spreadsheet zijn overgenomen in het tabblad Data van het Voorbeeldbestand.
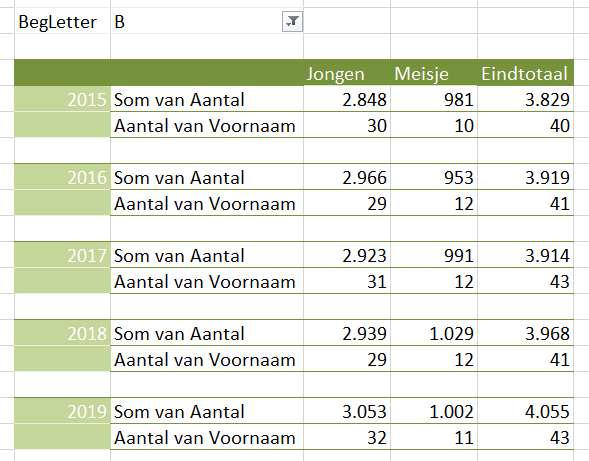
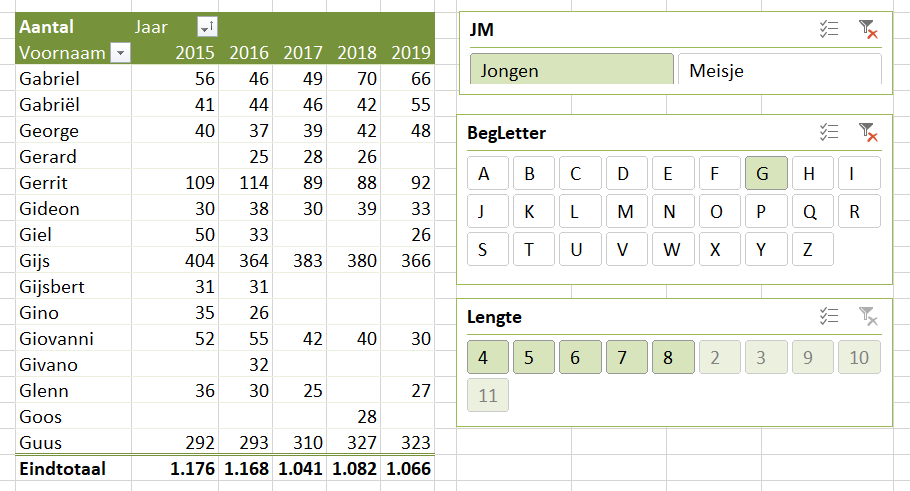
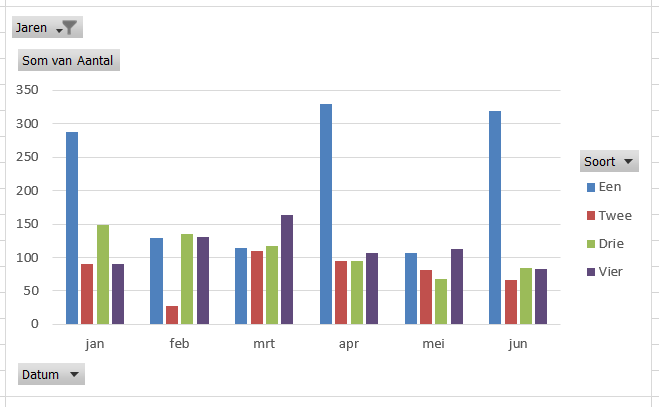
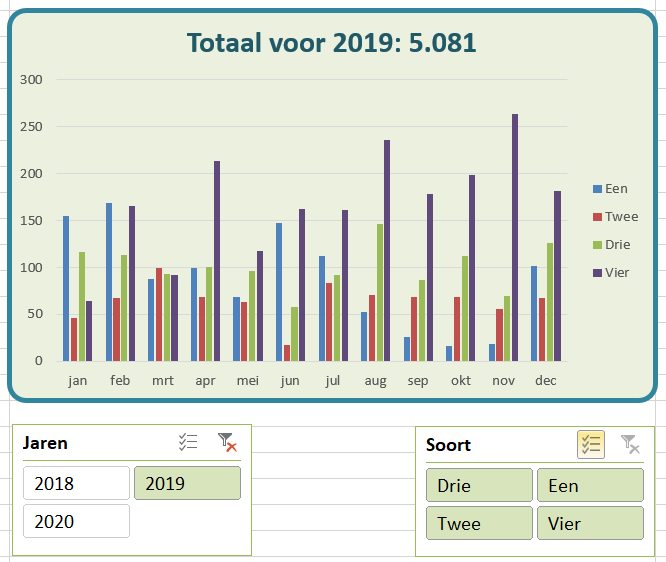
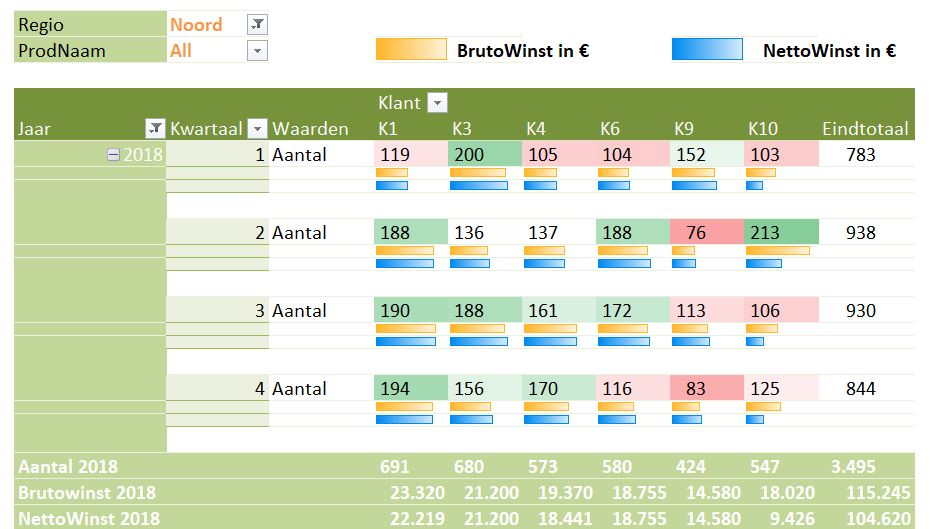
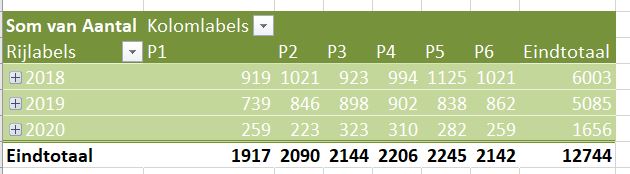
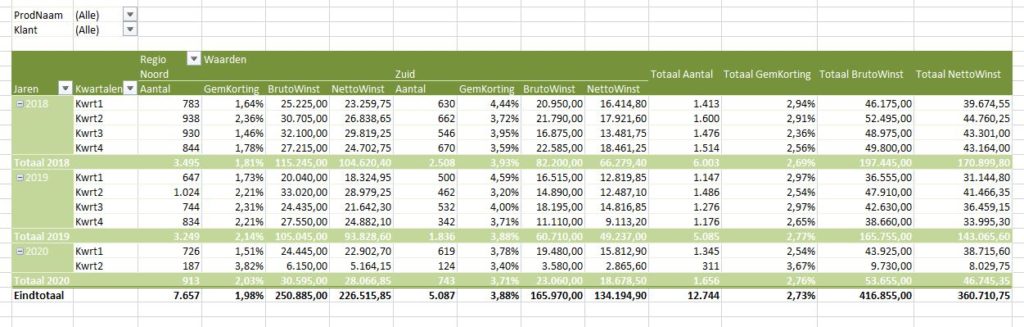
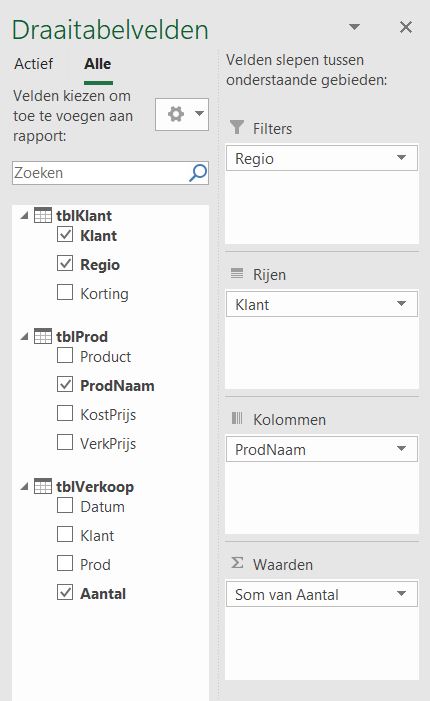
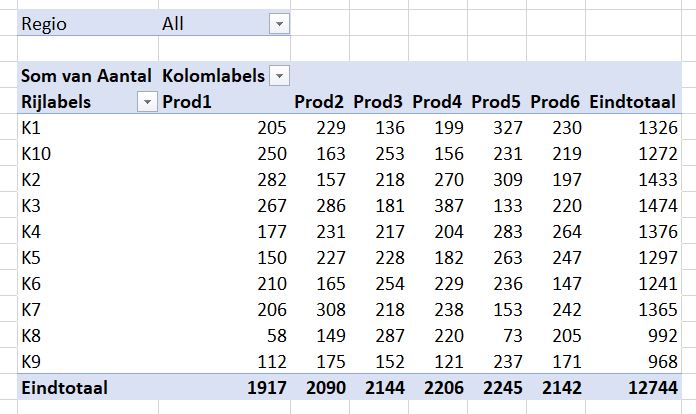
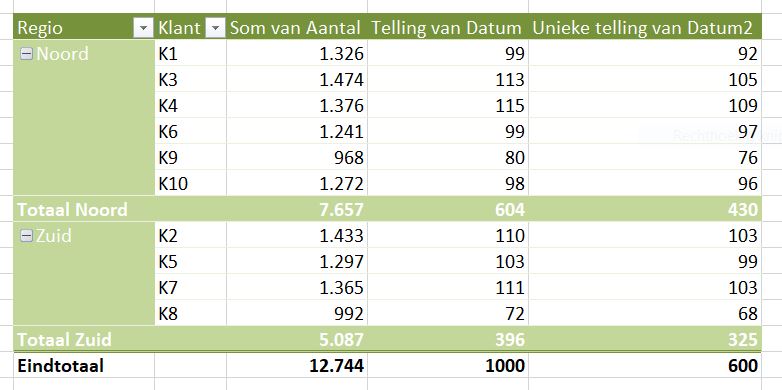
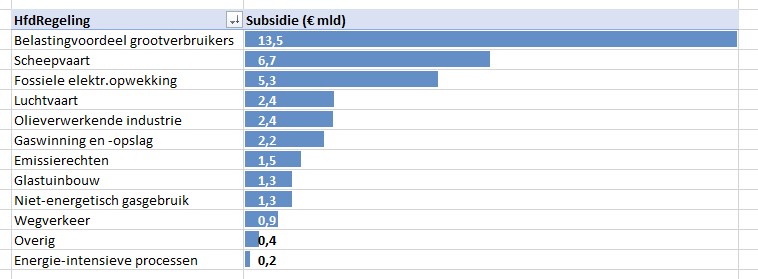
Maken we een overzicht daarvan met behulp van de draaitabel-optie van Excel (zie het tabblad Draai) dan zien we dat dit optelt tot € 38,2 mld en niet 37,5 zoals het rapport aangeeft (en dat door alle media is overgenomen).

We zien dat de post ten voordele van de grootgebruikers het grootste is. In het rapport wordt die hoofdcategorie Regelingen sectoroverstijgende energiebelasting genoemd.
NB wilt u de onderliggende details van een subsidie-bedrag zien? Dubbelklik in de draaitabel op dat bedrag en Excel opent een nieuw tabblad met daarin de betreffende regeling-bedragen.
Afwijking in berekening
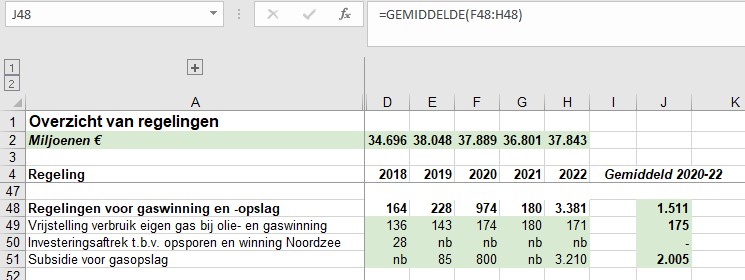
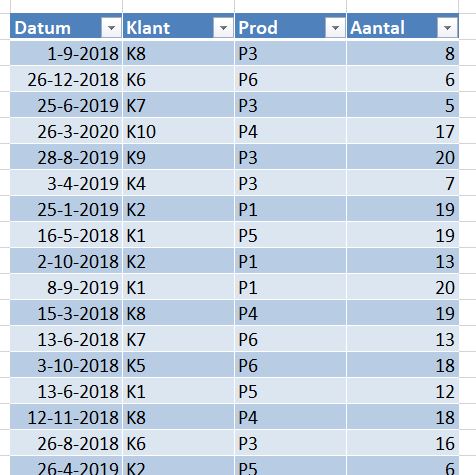
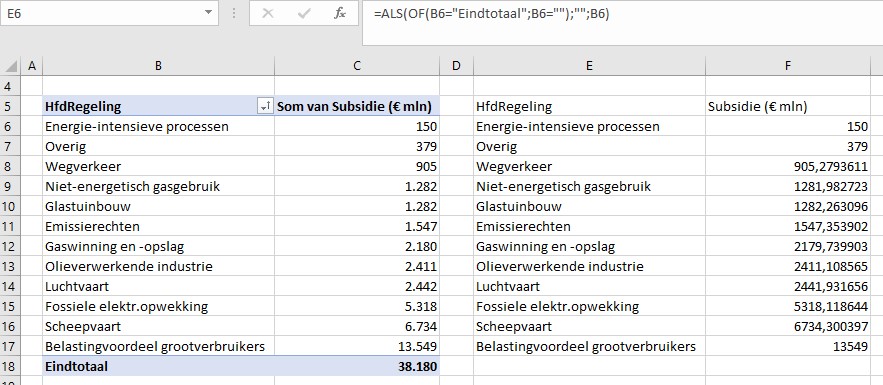
Waar komt het verschil in de totale subsidie-berekening nu vandaan? Hierboven staat een klein gedeelte van de door Milieudefensie e.a. gebruikte cijfers.
In cel J48 wordt het gemiddelde over 3 jaar van de categorie gaswinning en -opslag bepaald. Maar dat is niet gelijk aan de som van de onderliggende gemiddeldes!
Dat wordt veroorzaakt door de nb in cel G51. Bij het berekenen van het gemiddelde in die regel wordt die cel door Excel (terecht) niet meegenomen; bij het bepalen van het gemiddelde in cel J48 is (impliciet) de nb meegeteld als 0, waardoor dit bedrag lager uitkomt.
LET OP: wanneer je gemiddelden wilt berekenen (of dit nu in Excel is of niet) en er ontbreken basisgegevens, bedenk dan in welke volgorde de berekeningen moeten worden uitgevoerd.
Staafdiagram
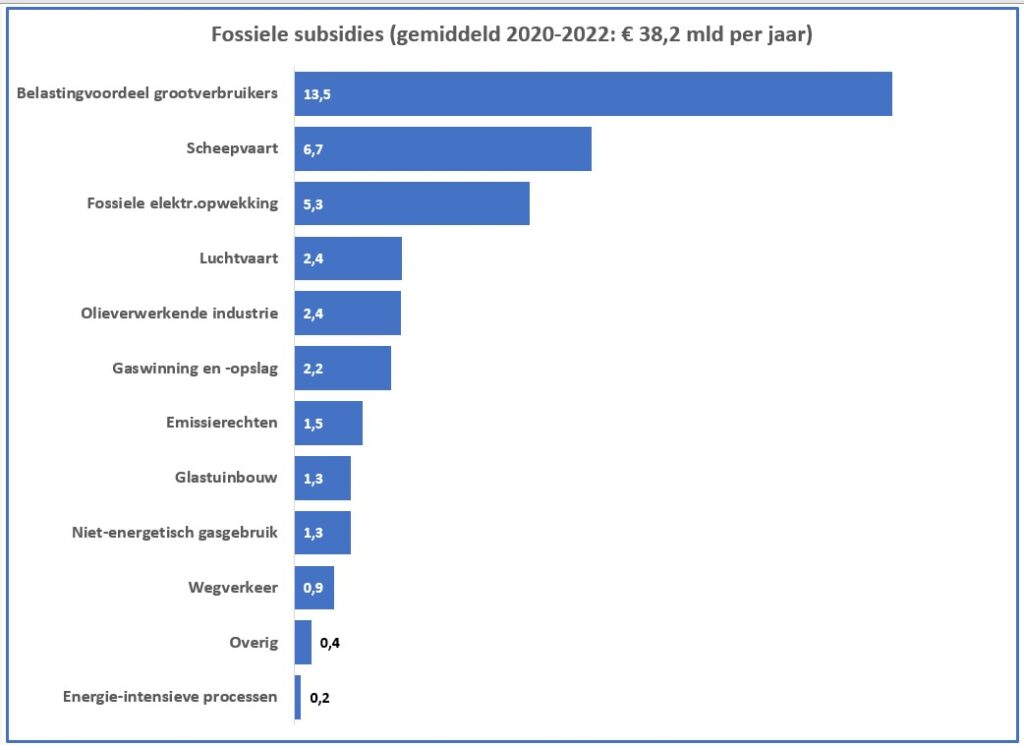
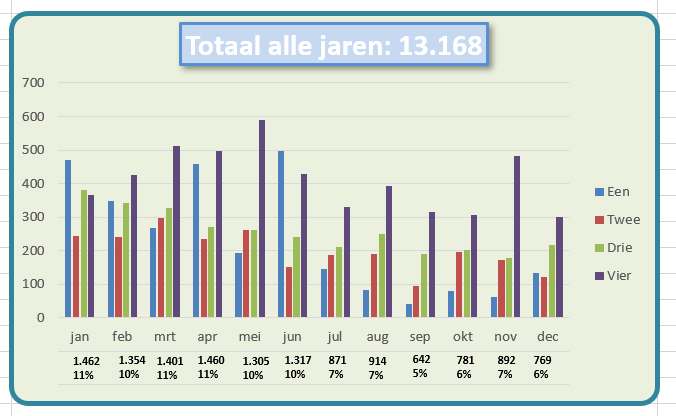
Een eerste grafiek, die goed laat zien in welke mate de diverse subsidies bijdragen aan het totaal-bedrag is het zogenaamde staafdiagram (zie het tabblad Graf in het Voorbeeldbestand):
- klik ergens in de draaitabel op het tabblad Draai van het Voorbeeldbestand
- kies in de menutab Hulpmiddelen voor draaitabellen in het blok Analyseren op Draaigrafiek
- kies de optie Staaf
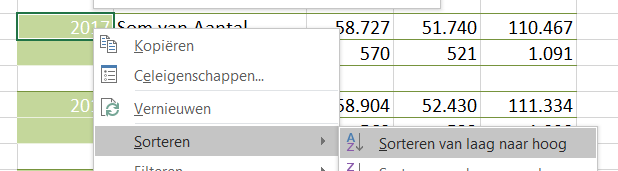
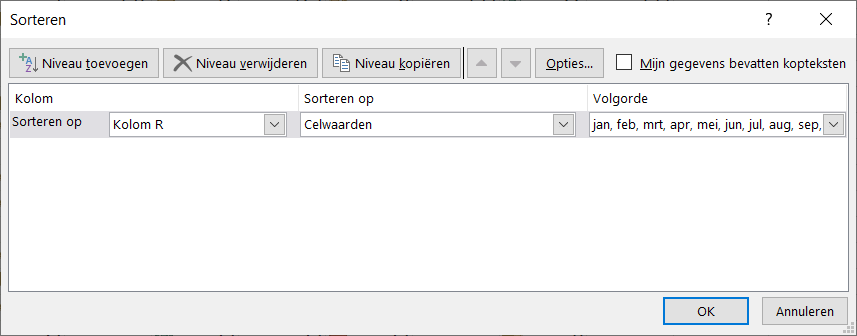
- zorg dat in de draaitabel de bedragen gesorteerd staan van laag naar hoog (via rechts-klikken)
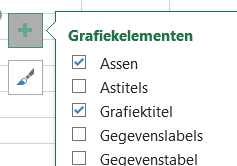
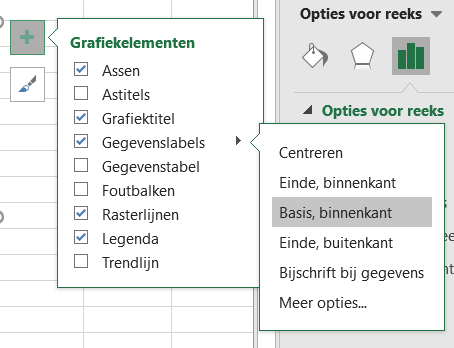
- selecteer bij Grafiekelementen de optie Gegevenslabels
- klik rechts op één van de gegevenslabels en kies Gegevenslabels opmaken
- pas de Labelpositie aan en maak een aangepaste Notatie: 0,0.
Dus een paar spaties, een nul, een komma, weer een nul en dan een punt.
Excel zal de getallen dan van extra spaties aan de voorkant voorzien, zorgen dat er 1 decimaal wordt weergegeven en, door de punt achter de cijfers, dat hij moet afronden op duizendtallen.
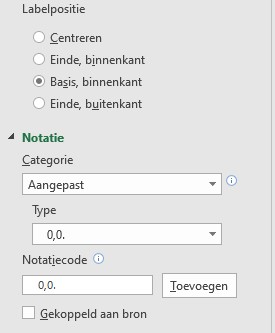
- de positie van de onderste 2 gegevenslabels zijn gewijzigd door nog een keer extra op deze labels te klikken en de opmaak aan te passen (Einde, buitenkant)
- pas ‘naar smaak’ nog wat extra opmaak toe
De grafiek is ook voorzien van een dynamische titel:
- klik ergens in de grafiektitel
- tik in de formulebalk het volgende in: =Draai!$E$2
- op het tabblad Draai staat in cel E2 de formule:
=”Fossiele subsidies (gemiddeld 2020-2022: € “&TEKST(DRAAITABEL.OPHALEN(“Subsidie (€ mln)”;$B$5);”0,0.”)&” mld per jaar)”
Staafdiagram 2
Een vergelijkbare grafiek kun je ook direct in de draaitabel maken (zie het tabblad Draai2 in het Voorbeeldbestand):
- klik op één van de cellen in de bedragenkolom van de draaitabel
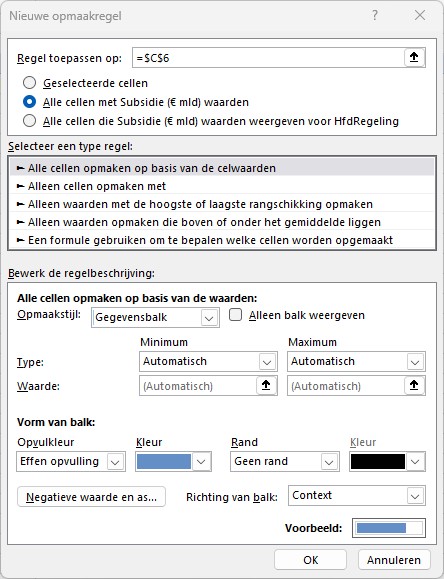
- klik in de menutab Start in het blok Stijlen op Voorwaardelijke opmaak en kies de optie Nieuwe regel
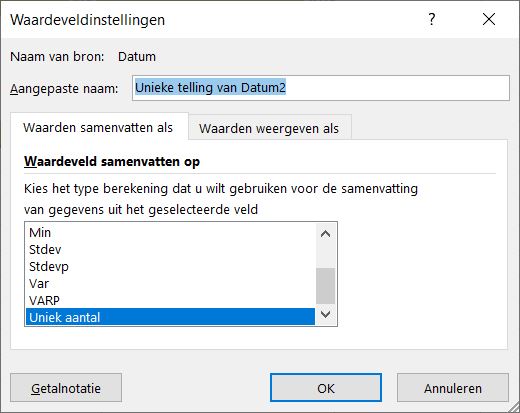
- vul het tussenscherm in, zoals hiernaast.
Het keuzerondje zorgt er voor dat als de draaitabel later uitgebreid wordt, de nieuwe gegevens ook deze opmaak krijgen. - klik rechts op één van de bedragen en kies de optie Getalnotatie.
Ook hier zorgen we weer voor een aangepaste notatie: 0,0.
- de kop van de bedragenkolom moeten we nog veranderen, want er worden nu geen miljoenen meer weergegeven maar miljarden.
NB wilt u nog wat tips voor het opmaken van draaitabellen kijk dan op het tabblad Docu van het Voorbeeldbestand; daar staat een verwijzing naar een internet-artikel en naar een ‘spiekbriefje’.

Treemap
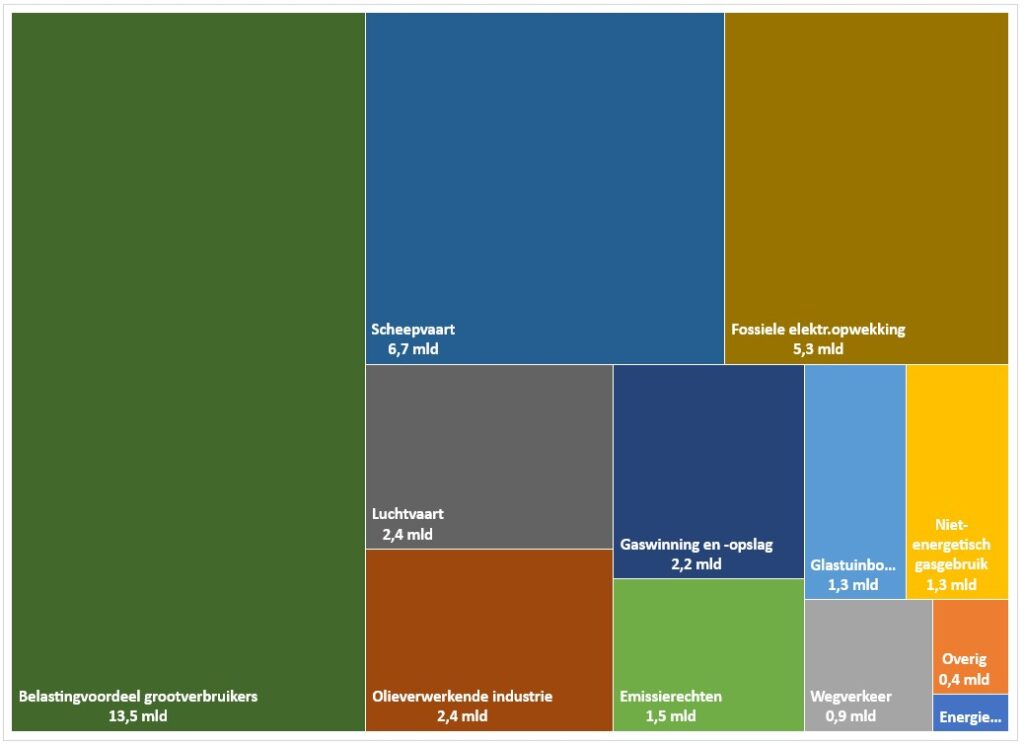
Het tabblad Tree1 van het Voorbeeldbestand bevat een ander soort grafiek, waarmee de verhouding tussen de onderdelen goed zichtbaar gemaakt kan worden, een zogenaamde Treemap.
Helaas kan die niet als Draaigrafiek rechtstreeks op een draaitabel gebaseerd worden (tenminste niet in mijn Excel-versie 2019).
We hebben een tussenstap nodig (zie het tabblad Draai):
Naast de draaitabel maken we dus een verwijzing naar die gegevens. Selecteer de betreffende kolommen en kies in de menutab Invoegen in het blok Grafiek de optie Hiërarchiegrafiek. Daar vindt u de Treemap-optie. De treemap is op een grafiekblad Graf geplaatst, zodat we een grafiek overhouden zonder ‘afleiding’ daar omheen. Excel schikt de diverse categorieën zodanig dat er een mooi gevulde rechthoek ontstaat.
Helaas: bij het verder opmaken van de grafiek zult u merken dat het niet mogelijk is om een dynamische titel toe te voegen. En ook de oplossing met een Tekstvak gaat hier niet werken.
Dezelfde treemap staat ook op een gewoon Excel-blad (zie het tabblad Tree2). Nu kun je wel een tekstvak toevoegen en daarin een verwijzing maken naar cel E2 in het tabblad Draai.
Een ander voordeel van het plaatsen op een gewoon Excel-blad is dat je de vorm van de rechthoek kunt aanpassen aan je eigen wensen:

Extra data
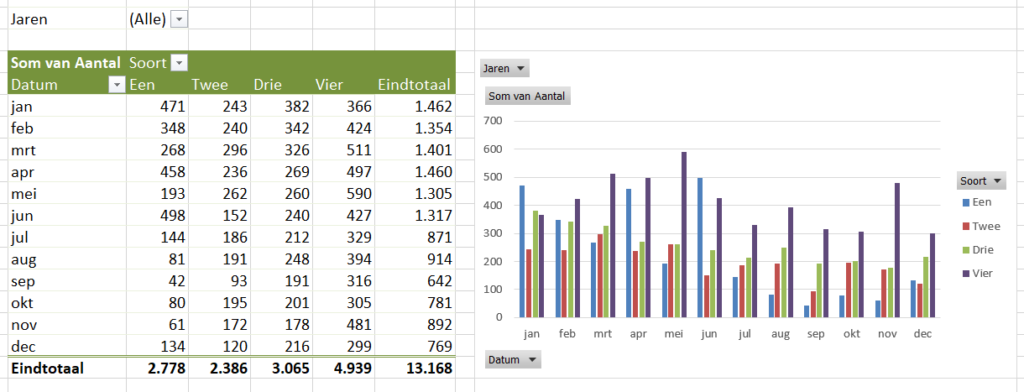
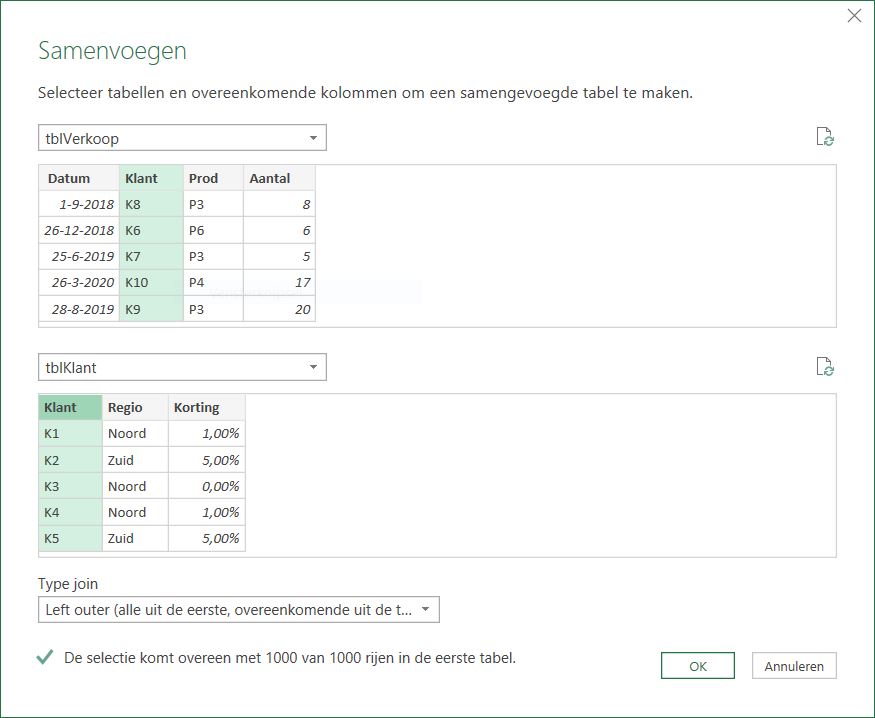
Voor de liefhebbers heb ik met behulp van Power Query uit de bron wat meer details opgehaald (zie het tabblad Data2 in het Voorbeeldbestand):
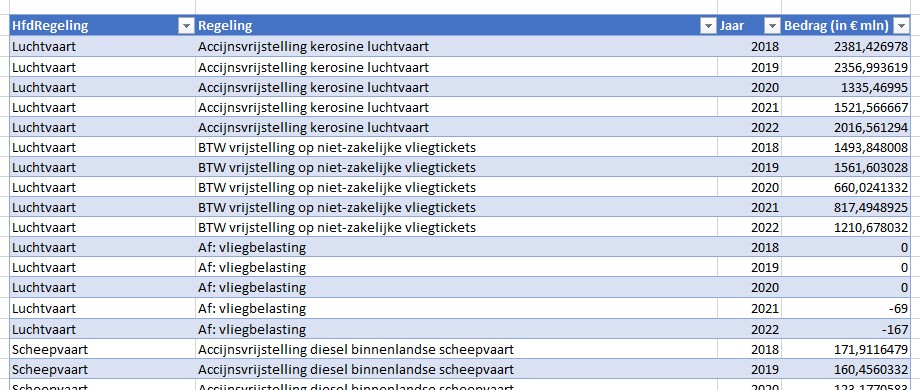
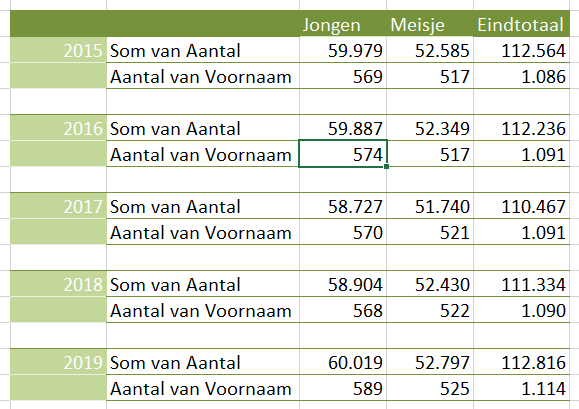
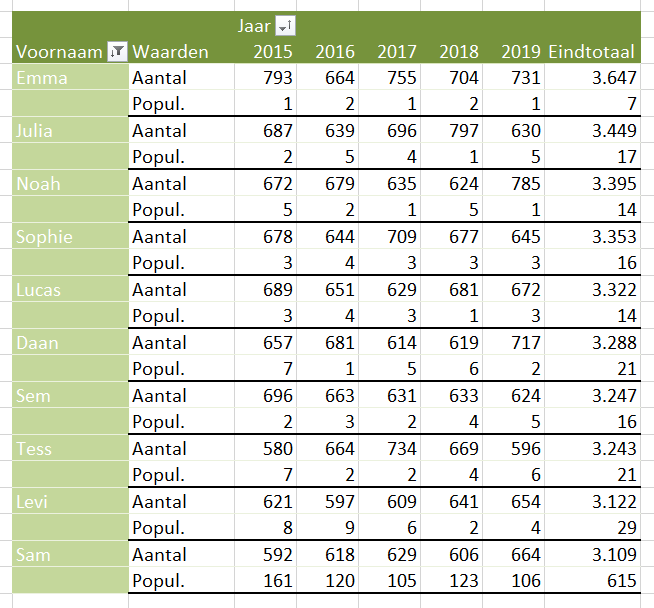
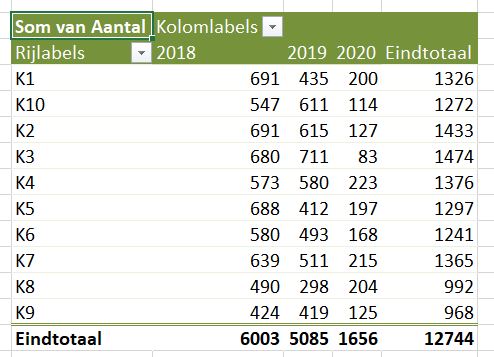
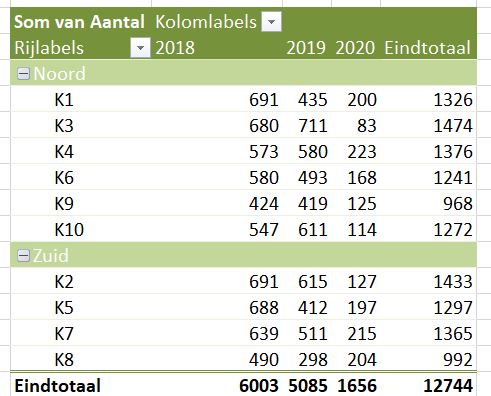
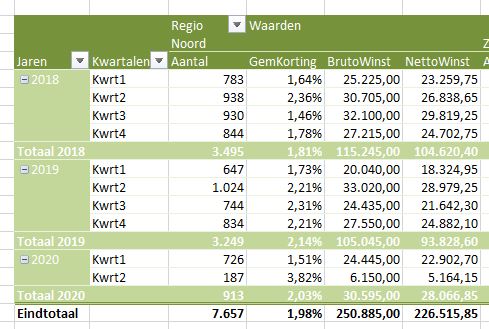
Op basis van deze data kun je diverse overzichten genereren, bijvoorbeeld een draaitabel op hoofdregeling-niveau over de jaren:
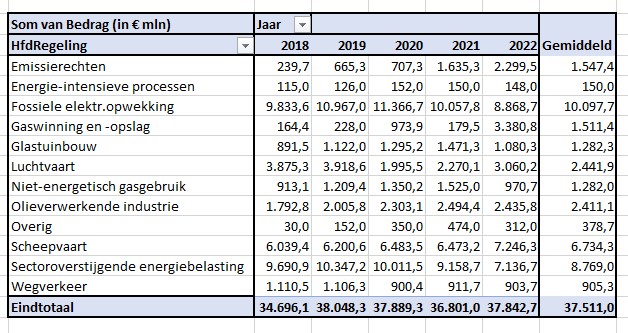
LET OP: het probleem met het middelen zoals hierboven aangegeven, steekt hier ook weer de kop op!


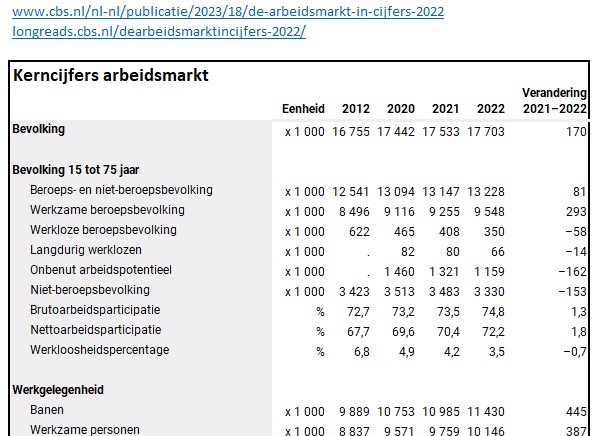
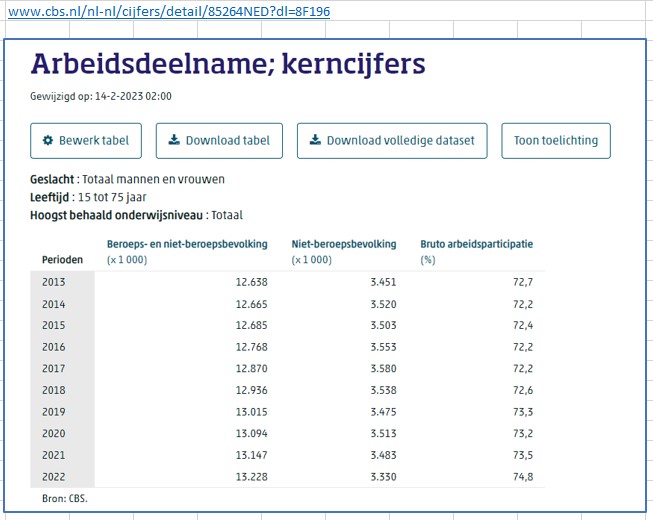

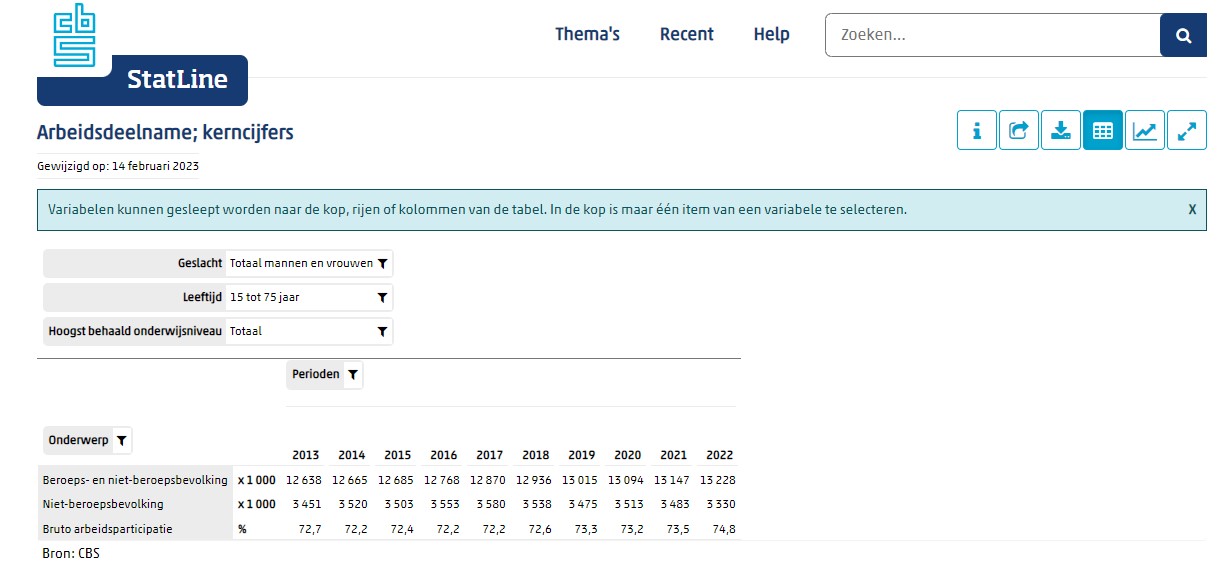
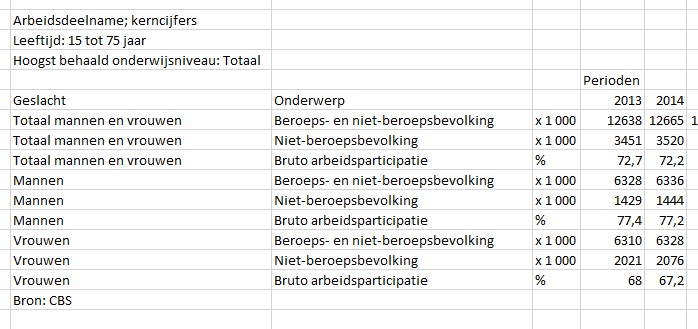
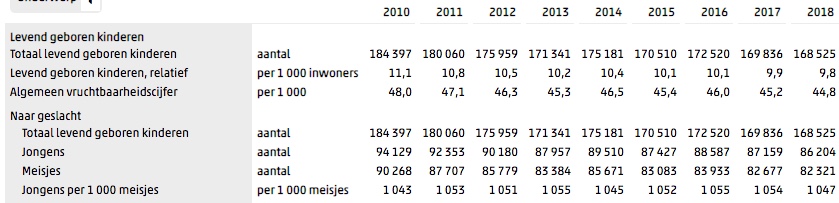
 te klikken kom je vanzelf in het Statline-gebied van het CBS, waar je veel meer opties hebt om gegevens te kiezen.
te klikken kom je vanzelf in het Statline-gebied van het CBS, waar je veel meer opties hebt om gegevens te kiezen.